















































































































































































![[The AI Show Episode 151]: Anthropic CEO: AI Will Destroy 50% of Entry-Level Jobs, Veo 3’s Scary Lifelike Videos, Meta Aims to Fully Automate Ads & Perplexity’s Burning Cash](https://www.marketingaiinstitute.com/hubfs/ep%20151%20cover.png)


















































































































































































































































.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)













































































































![Epic Games: Apple’s attempt to pause App Store antitrust order fails [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/05/epic-games-app-store.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)



















![Apple AI Launch in China Delayed Amid Approval Roadblocks and Trade Tensions [Report]](https://www.iclarified.com/images/news/97500/97500/97500-640.jpg)


























![[UPDATED] New Android Trojan Can Fake Contacts to Scam You — Meet Crocodilus](https://www.androidheadlines.com/wp-content/uploads/2022/12/Android-malware-image-1.jpg)

















![T-Mobile may be misleading customers into spending more with new switch offer [UPDATED]](https://m-cdn.phonearena.com/images/article/171029-two/T-Mobile-may-be-misleading-customers-into-spending-more-with-new-switch-offer-UPDATED.jpg?#)














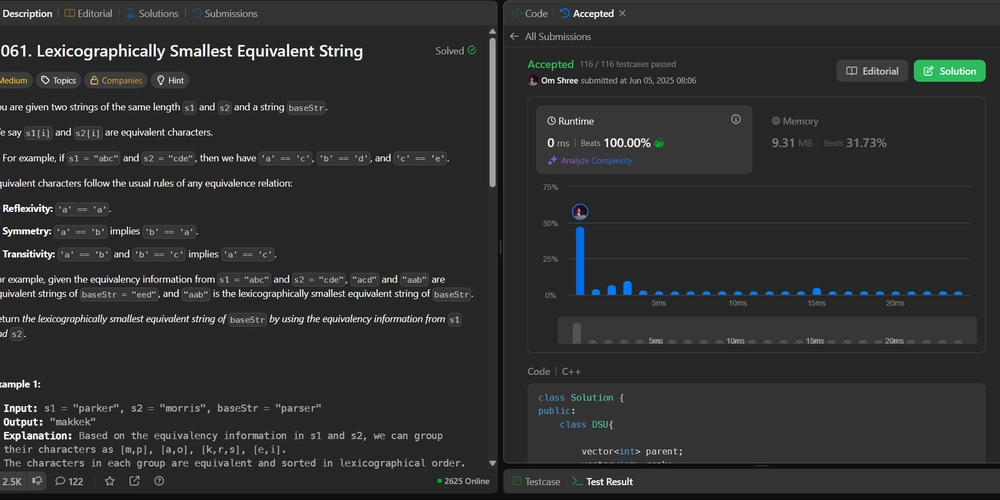
From Exploration Collapse to Predictable Limits: Shanghai AI Lab Proposes Entropy-Based Scaling Laws for Reinforcement Learning in LLMs
Recent advances in reasoning-centric large language models (LLMs) have expanded the scope of reinforcement learning (RL) beyond narrow, task-specific applications, enabling broader generalization and reasoning capabilities. However, this shift introduces significant challenges, particularly in scaling the training compute required for learning from experience. Unlike imitation learning through pre-training and fine-tuning, RL demands a more computationally […] The post From Exploration Collapse to Predictable Limits: Shanghai AI Lab Proposes Entropy-Based Scaling Laws for Reinforcement Learning in LLMs appeared first on MarkTechPost.

Recent advances in reasoning-centric large language models (LLMs) have expanded the scope of reinforcement learning (RL) beyond narrow, task-specific applications, enabling broader generalization and reasoning capabilities. However, this shift introduces significant challenges, particularly in scaling the training compute required for learning from experience. Unlike imitation learning through pre-training and fine-tuning, RL demands a more computationally intensive approach. A central issue is the decline in policy entropy, which affects the balance between exploiting known strategies and exploring new ones. This exploitation-exploration trade-off is fundamental in RL, and controlling policy entropy has become critical to maintaining effective exploration during training.
Existing efforts address the exploration-exploitation trade-off in RL by utilizing policy entropy. Maximum entropy RL introduces a regularization term to the reward function, promoting uncertainty in action selection and encouraging broader exploration. While this technique has been widely adopted in conventional RL algorithms, its application to LLMs remains debated. Moreover, predictability in RL for LLMs is not explored. While neural scaling laws guide LLM development, similar predictive frameworks for RL training remain limited. Existing RL methods for LLMs with verifiable rewards show promise in reasoning improvements, but lack a deep understanding of their core mechanisms.
Researchers from Shanghai AI Laboratory, Tsinghua University, UIUC, Peking University, Nanjing University, and CUHK provide an approach to address the collapse of policy entropy in RL for reasoning-centric LLMs. They established a transformation equation, R = −a exp H + b, where H is entropy, R is downstream performance, and a and b are fitting coefficients. This empirical law strongly suggests that policy performance is traded from policy entropy, thus bottlenecked by its exhaustion. Researchers investigate entropy dynamics, and their derivation highlights that the change in policy entropy is driven by the covariance between action probability and the change in logits. They also proposed two techniques, namely Clip-Cov and KL-Cov, which clip and apply a KL penalty to tokens with high covariances, respectively.
To investigate and validate the entropy collapse phenomenon in RL-tuned LLMs, researchers applied RL to LLMs on verifiable tasks, like math and coding, using an autoregressive generation setup where models produce token sequences based on input prompts. The study involves 11 widely adopted open-source models spanning four families: Qwen2.5, Mistral, LLaMA, and DeepSeek, with parameters ranging from 0.5B to 32 B. Evaluations are performed on eight public benchmarks, including MATH500, AIME 2024, AMC, and Eurus-2-RL-Code. Moreover, RL training follows the veRL framework in a zero-shot setting, utilizing algorithms like GRPO, REINFORCE++, and PRIME to optimize policy performance while observing entropy dynamics.
The proposed Clip-Cov and KL-Cov techniques were evaluated on the Qwen2.5 models using the DAPOMATH dataset for math tasks. These methods achieve non-trivial performance gains across all benchmarks. In comparison to the GRPO baseline, these methods improve performance by 2.0% on average for the 7B model and by 6.4% for the 32B model. For example, when the baseline’s entropy reaches a plateau, the KL-Cov method still sustains an entropy level over 10 times higher. The methods can maintain a higher level of entropy throughout the training. Moreover, the methods yield more substantial gains on the larger Qwen2.5-32B model, with improvements of 15.0% and 14.6% compared to GRPO on the most challenging benchmarks, AIME24 and AIME25, respectively.

In conclusion, researchers have overcome the challenge of policy entropy collapse in RL for reasoning-centric LLMs. The findings highlight a trade-off between performance improvement and diminished exploration, which ultimately limits further gains. Through theoretical analysis and empirical validation, researchers identify entropy dynamics as a key bottleneck and propose two effective regularization strategies—Clip-Cov and KL-Cov to manage high-covariance tokens and sustain exploration. As RL emerges as a crucial axis for scaling beyond pre-training, addressing entropy collapse becomes essential. This work provides foundational insights into the role of entropy, guiding future efforts to scale RL toward more intelligent and capable language models.
Check out the Paper and GitHub Page . All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 95k+ ML SubReddit and Subscribe to our Newsletter.
The post From Exploration Collapse to Predictable Limits: Shanghai AI Lab Proposes Entropy-Based Scaling Laws for Reinforcement Learning in LLMs appeared first on MarkTechPost.



