







































































![[The AI Show Episode 149]: Google I/O, Claude 4, White Collar Jobs Automated in 5 Years, Jony Ive Joins OpenAI, and AI’s Impact on the Environment](https://www.marketingaiinstitute.com/hubfs/ep%20149%20cover.png)







































































































































































































































![Laid off but not afraid with X-senior Microsoft Dev MacKevin Fey [Podcast #173]](https://cdn.hashnode.com/res/hashnode/image/upload/v1747965474270/ae29dc33-4231-47b2-afd1-689b3785fb79.png?#)











































































































.jpg?#)
























_David_Hall_-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Andriy_Popov_Alamy_Stock_Photo.jpg?width=1280&auto=webp&quality=80&disable=upscale#)













































































































![Apple's Secret AI Robot With Expressive Arm Now a Major Focus [Report]](https://www.iclarified.com/images/news/97425/97425/97425-640.jpg)
![Trump Targets Apple After Tim Cook Skips Middle East Trip [Report]](https://www.iclarified.com/images/news/97427/97427/97427-640.jpg)
![Apple to Unveil New 'Solarium' Interface at WWDC [Report]](https://www.iclarified.com/images/news/97422/97422/97422-640.jpg)
![Apple 15-inch M4 MacBook Air On Sale for $1049.99 [Deal]](https://www.iclarified.com/images/news/97419/97419/97419-640.jpg)




























































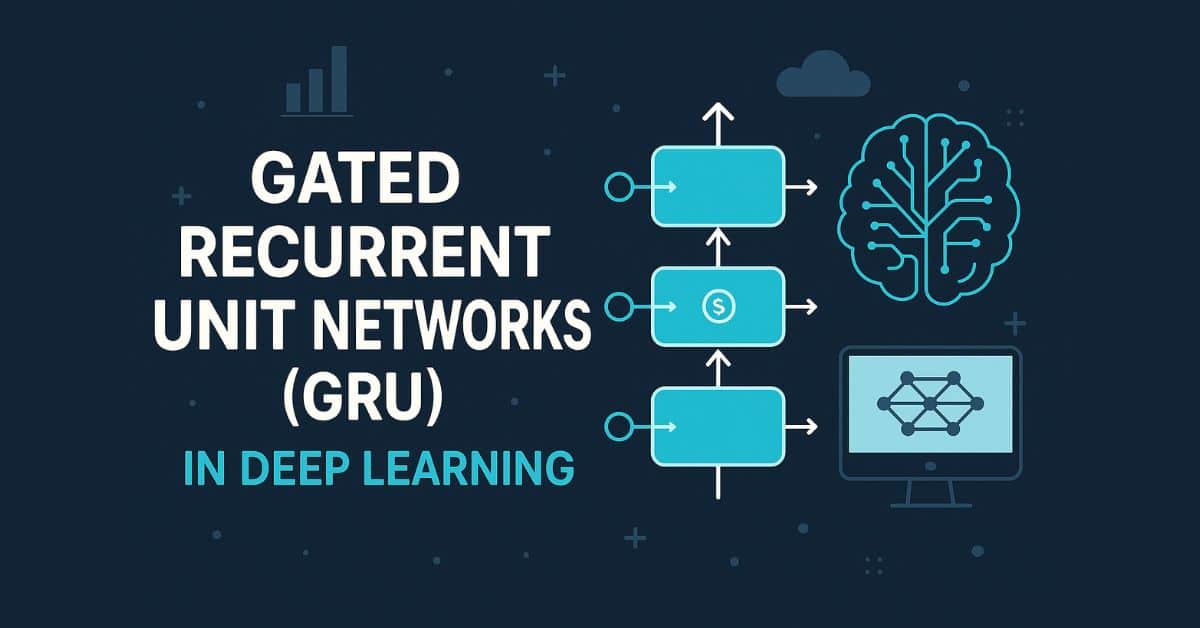
Comparing DiskANN in SQL Server & HNSW in RavenDB
When building RavenDB 7.0, a major feature was Vector Search and AI integration.We weren't the first database to make Vector Search a core feature, and that was pretty much by design. Not being the first out of the gate meant that we had time to observe the industry, study new research, and consider how we could best enable Vector Search for our users. This isn’t just about the algorithm or the implementation, but about the entire mindset of how you provide the feature to your users. The logistics of a feature dictate how effectively you can use it, after all.This post is prompted by the recent release of SQL Server 2025 Preview, which includes Vector Search indexing.Looking at what others in the same space are doing is fascinating. The SQL Server team is using the DiskANN algorithm for their Vector Search indexes, and that is pretty exciting to see.The DiskANN algorithm was one of the algorithms we considered when implementing Vector Search for RavenDB. We ended up choosing the HNSW algorithm as the basis for our vector indexing.This is a common choice; most databases with both indexing options use HNSW. PostgreSQL, MongoDB, Redis, and Elasticsearch all use HNSW.Microsoft’s choice to use DiskANN isn’t surprising (DiskANN was conceived at Microsoft, after all). I also assume that Microsoft has sufficient resources and time to do a good job actually implementing it. So I was really excited to see what kind of behavior the new SQL Server has here.RavenDB's choice of HNSW for vector search ended up being pretty simple.Of all the algorithms considered, it was the only one that met our requirements.These requirements are straightforward: Vector Search should function like any other index in the system. You define it, it runs, your queries are fast. You modify the data, the index is updated, your queries are still fast.I don’t think this is too much to ask :-), but it turned out to be pretty complicated when we look at the Vector Search indexes. Most vector indexing solutions have limitations, such as requiring all data upfront (ANNOY, SCANN) or degrading over time (IVF Flat, LSH) with modifications.HNSW, on the other hand, builds incrementally and operates efficiently on inserted, updated, and deleted data without significant maintenance.Therefore, it was interesting to examine the DiskANN behavior in SQL Server, as it's a rare instance of a world-class algorithm available from the source that I can start looking at. I must say I'm not impressed. I’m not talking about the actual implementation, but rather the choices that were made for this feature in general. As someone who has deeply explored this topic and understands its complexities, I believe using vector indexes in SQL Server 2025, as it currently appears, will be a significant hassle and only suitable for a small set of scenarios.I tested the preview using this small Wikipedia dataset, which has just under 500,000 vectors and less than 2GB of data – a tiny dataset for vector search.On a Docker instance with 12 cores and 32 GB RAM, SQL Server took about two and a half hours to create the index!In contrast, RavenDB will index the same dataset in under two minutes.I might have misconfigured SQL Server or encountered some licensing constraints affecting performance, but the difference between 2 minutes and 150 minutes is remarkable. I’m willing to let that one go, assuming I did something wrong with the SQL Server setup. Another crucial aspect is that creating a vector index in SQL Server has other implications. Most notably, the source table becomes read-only and is fully locked during the (very long) indexing period.This makes working with vector indexes on frequently updated data very challenging to impossible. You would need to copy data every few hours, perform indexing (which is time-consuming), and then switch which table you are querying against – a significant inconvenience.Frankly, it seems suitable only for static or rarely updated data, for example, if you have documentation that is updated every few months.It's not a good solution for applying vector search to dynamic data like a support forum with continuous questions and answers.I believe the design of SQL Server's vector search reflects a paradigm where all data is available upfront, as discussed in research papers. DiskANN itself is immutable once created. There is another related algorithm, FreshDiskANN, which can handle updates, but that isn’t what SQL Server has at this point. The problem is the fact that this choice of algorithm is really not operationally transparent for users. It will have serious consequences for anyone trying to actually make use of this for anything but frozen datasets. In short, even disregarding the indexing time difference, the ability to work with live data and incrementally add vectors to the index makes me very glad we chose HNSW for RavenDB. The entire problem just doesn’t exist for us.
When building RavenDB 7.0, a major feature was Vector Search and AI integration.We weren't the first database to make Vector Search a core feature, and that was pretty much by design.
Not being the first out of the gate meant that we had time to observe the industry, study new research, and consider how we could best enable Vector Search for our users. This isn’t just about the algorithm or the implementation, but about the entire mindset of how you provide the feature to your users. The logistics of a feature dictate how effectively you can use it, after all.
This post is prompted by the recent release of SQL Server 2025 Preview, which includes Vector Search indexing.Looking at what others in the same space are doing is fascinating. The SQL Server team is using the DiskANN algorithm for their Vector Search indexes, and that is pretty exciting to see.
The DiskANN algorithm was one of the algorithms we considered when implementing Vector Search for RavenDB. We ended up choosing the HNSW algorithm as the basis for our vector indexing.This is a common choice; most databases with both indexing options use HNSW. PostgreSQL, MongoDB, Redis, and Elasticsearch all use HNSW.
Microsoft’s choice to use DiskANN isn’t surprising (DiskANN was conceived at Microsoft, after all). I also assume that Microsoft has sufficient resources and time to do a good job actually implementing it. So I was really excited to see what kind of behavior the new SQL Server has here.
RavenDB's choice of HNSW for vector search ended up being pretty simple.Of all the algorithms considered, it was the only one that met our requirements.These requirements are straightforward: Vector Search should function like any other index in the system. You define it, it runs, your queries are fast. You modify the data, the index is updated, your queries are still fast.
I don’t think this is too much to ask :-), but it turned out to be pretty complicated when we look at the Vector Search indexes. Most vector indexing solutions have limitations, such as requiring all data upfront (ANNOY, SCANN) or degrading over time (IVF Flat, LSH) with modifications.
HNSW, on the other hand, builds incrementally and operates efficiently on inserted, updated, and deleted data without significant maintenance.
Therefore, it was interesting to examine the DiskANN behavior in SQL Server, as it's a rare instance of a world-class algorithm available from the source that I can start looking at.
I must say I'm not impressed. I’m not talking about the actual implementation, but rather the choices that were made for this feature in general. As someone who has deeply explored this topic and understands its complexities, I believe using vector indexes in SQL Server 2025, as it currently appears, will be a significant hassle and only suitable for a small set of scenarios.
I tested the preview using this small Wikipedia dataset, which has just under 500,000 vectors and less than 2GB of data – a tiny dataset for vector search.On a Docker instance with 12 cores and 32 GB RAM, SQL Server took about two and a half hours to create the index!
In contrast, RavenDB will index the same dataset in under two minutes.I might have misconfigured SQL Server or encountered some licensing constraints affecting performance, but the difference between 2 minutes and 150 minutes is remarkable. I’m willing to let that one go, assuming I did something wrong with the SQL Server setup.
Another crucial aspect is that creating a vector index in SQL Server has other implications. Most notably, the source table becomes read-only and is fully locked during the (very long) indexing period.
This makes working with vector indexes on frequently updated data very challenging to impossible. You would need to copy data every few hours, perform indexing (which is time-consuming), and then switch which table you are querying against – a significant inconvenience.
Frankly, it seems suitable only for static or rarely updated data, for example, if you have documentation that is updated every few months.It's not a good solution for applying vector search to dynamic data like a support forum with continuous questions and answers.
I believe the design of SQL Server's vector search reflects a paradigm where all data is available upfront, as discussed in research papers. DiskANN itself is immutable once created. There is another related algorithm, FreshDiskANN, which can handle updates, but that isn’t what SQL Server has at this point.
The problem is the fact that this choice of algorithm is really not operationally transparent for users. It will have serious consequences for anyone trying to actually make use of this for anything but frozen datasets.
In short, even disregarding the indexing time difference, the ability to work with live data and incrementally add vectors to the index makes me very glad we chose HNSW for RavenDB. The entire problem just doesn’t exist for us.



