










































































































































































![[The AI Show Episode 151]: Anthropic CEO: AI Will Destroy 50% of Entry-Level Jobs, Veo 3’s Scary Lifelike Videos, Meta Aims to Fully Automate Ads & Perplexity’s Burning Cash](https://www.marketingaiinstitute.com/hubfs/ep%20151%20cover.png)

















































































































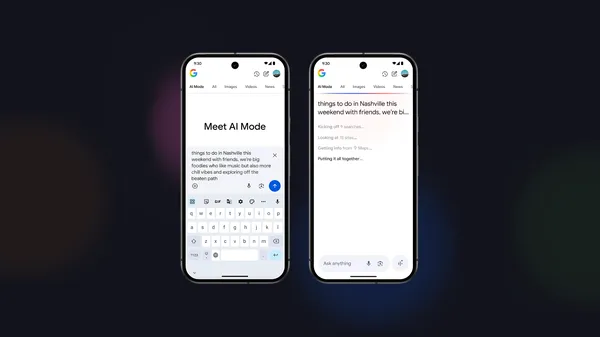

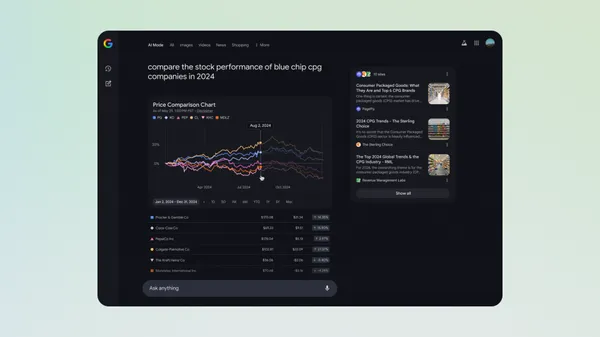






























































































































































































































































![Apple Shares Official Trailer for 'The Wild Ones' [Video]](https://www.iclarified.com/images/news/97515/97515/97515-640.jpg)


































































LifelongAgentBench: A Benchmark for Evaluating Continuous Learning in LLM-Based Agents
Lifelong learning is crucial for intelligent agents navigating ever-changing environments, yet current LLM-based agents fall short—they lack memory and treat every task as a fresh start. While LLMs have transformed language tasks and inspired agent-based systems, these agents remain stateless and unable to learn from past experiences. True progress toward general intelligence requires agents that […] The post LifelongAgentBench: A Benchmark for Evaluating Continuous Learning in LLM-Based Agents appeared first on MarkTechPost.

Lifelong learning is crucial for intelligent agents navigating ever-changing environments, yet current LLM-based agents fall short—they lack memory and treat every task as a fresh start. While LLMs have transformed language tasks and inspired agent-based systems, these agents remain stateless and unable to learn from past experiences. True progress toward general intelligence requires agents that can retain, adapt, and reuse knowledge over time. Unfortunately, current benchmarks primarily focus on isolated tasks, overlooking the reuse of skills and knowledge retention. Without standardized evaluations for lifelong learning, it’s difficult to measure real progress, and issues like label errors and reproducibility further hinder practical development.
Lifelong learning, also known as continual learning, aims to help AI systems build and retain knowledge across tasks while avoiding catastrophic forgetting. Most previous work in this area has focused on non-interactive tasks, such as image classification or sequential fine-tuning, where models process static inputs and outputs without needing to respond to changing environments. However, applying lifelong learning to LLM-based agents that operate in dynamic, interactive settings remains underexplored. Existing benchmarks, such as WebArena, AgentBench, and VisualWebArena, assess one-time task performance but don’t support learning over time. Even interactive studies involving games or tools lack standard frameworks for evaluating lifelong learning in agents.
Researchers from the South China University of Technology, MBZUAI, the Chinese Academy of Sciences, and East China Normal University have introduced LifelongAgentBench, the first comprehensive benchmark for evaluating lifelong learning in LLM-based agents. It features interdependent, skill-driven tasks across three environments—Database, Operating System, and Knowledge Graph—with built-in label verification, reproducibility, and modular design. The study reveals that conventional experience replay is often ineffective due to the inclusion of irrelevant information and the limitation of context length. To address this, the team proposes a group self-consistency mechanism that clusters past experiences and applies voting strategies, significantly enhancing lifelong learning performance across various LLM architectures.
LifelongAgentBench is a benchmark designed to test how effectively language model-based agents learn and adapt across a series of tasks over time. The setup treats learning as a sequential decision-making problem using goal-conditioned POMDPs within three environments: Databases, Operating Systems, and Knowledge Graphs. Tasks are structured around core skills and crafted to reflect real-world complexity, with attention to factors like task difficulty, overlapping skills, and environmental noise. Task generation combines both automated and manual validation to ensure quality and diversity. This benchmark helps assess whether agents can build on past knowledge and improve continuously in dynamic, skill-driven settings.
LifelongAgentBench is a new evaluation framework designed to test how well LLM-based agents learn over time by tackling tasks in a strict sequence, unlike previous benchmarks that focus on isolated or parallel tasks. Its modular system includes components like an agent, environment, and controller, which can run independently and communicate via RPC. The framework prioritizes reproducibility and flexibility, supporting diverse environments and models. Through experiments, it has been shown that experience replay—feeding agents successful past trajectories—can significantly boost performance, especially on complex tasks. However, larger replays can lead to memory issues, underscoring the need for more efficient replay and memory management strategies.

In conclusion, LifelongAgentBench is a pioneering benchmark designed to evaluate the ability of LLM-based agents to learn continuously over time. Unlike earlier benchmarks that treat agents as static, this framework tests their ability to build, retain, and apply knowledge across interconnected tasks in dynamic environments, such as databases, operating systems, and knowledge graphs. It offers modular design, reproducibility, and automated evaluation. While experience replay and group self-consistency show promise in boosting learning, issues such as memory overload and inconsistent gains across models persist. This work lays the foundation for developing more adaptable, memory-efficient agents, with future directions focusing on smarter memory use and real-world multimodal tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 95k+ ML SubReddit and Subscribe to our Newsletter.
The post LifelongAgentBench: A Benchmark for Evaluating Continuous Learning in LLM-Based Agents appeared first on MarkTechPost.



