

















































































































































































![[The AI Show Episode 151]: Anthropic CEO: AI Will Destroy 50% of Entry-Level Jobs, Veo 3’s Scary Lifelike Videos, Meta Aims to Fully Automate Ads & Perplexity’s Burning Cash](https://www.marketingaiinstitute.com/hubfs/ep%20151%20cover.png)


















































































































































































































































































































































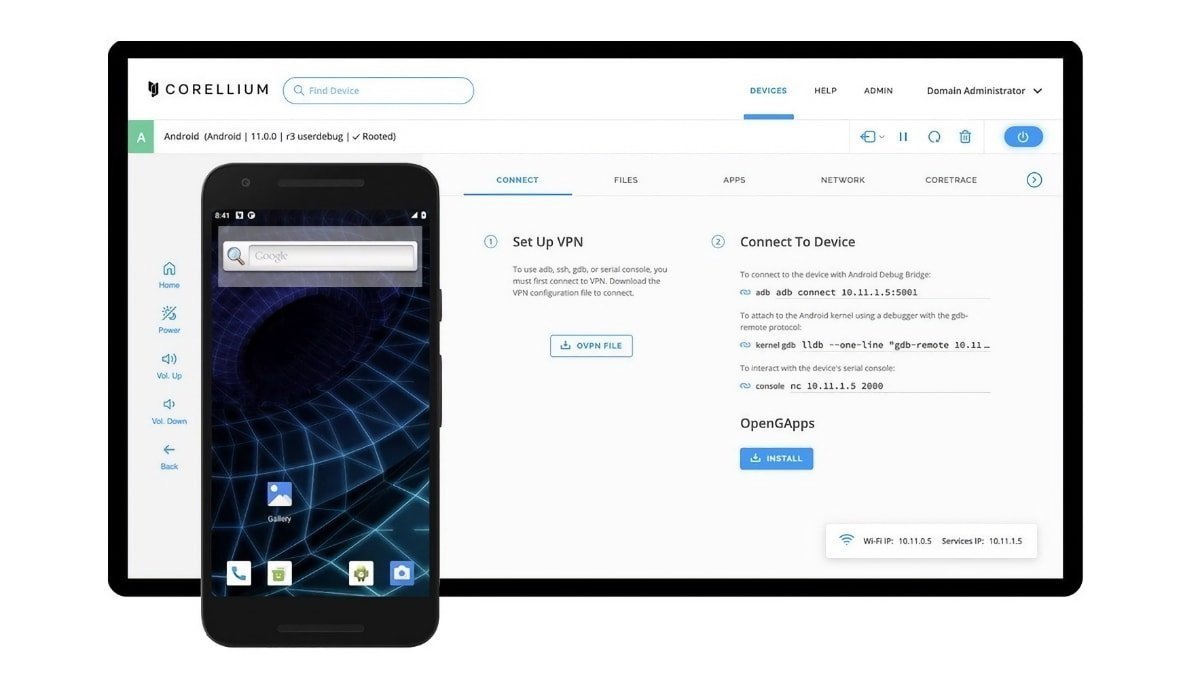

























![Apple Shares Official Trailer for 'The Wild Ones' [Video]](https://www.iclarified.com/images/news/97515/97515/97515-640.jpg)


































































Blackwell GPUs Lift Nvidia to the Top of MLPerf Training Rankings
Nvidia’s latest MLPerf Training 5.0 results show its Blackwell GB200 accelerators sprinting through record time-to-train scores, showing how the company’s rack-scale “AI-factory” design can turn raw compute into deployable models more quickly than before. Using 34 72-GPU NVLink domains combined into a 2,496-GPU cluster, the system sustained 1,829 teraflops (roughly 1.8 petaflops) of measured application throughput while maintaining 90 percent scaling efficiency. Additionally, it was the only submission to complete the suite’s new 405-billion-parameter Llama-3.1 workload, making this Nvidia’s most ambitious MLPerf showing to date. Blackwell’s Debut at Scale Nvidia submitted results for its GB200 NVL72 systems – 72 Blackwell GPUs linked by fifth-generation NVLink and NVSwitch fabric – at a cluster scale of 2,496 GPUs. Working with cloud partners CoreWeave and IBM, the company reported 90 % strong-scaling efficiency when expanding from 512 to 2,496 devices. That figure is notable, as linear scaling is rarely achieved beyond a few hundred GPUs. “What we achieved was phenomenal scaling efficiency,” said Dave Salvator, Nvidia director of accelerated computing products, in a press briefing. “What you see there is 90% scaling efficiency, which is almost linear scaling.” In typical large-scale training runs, scaling efficiency in the 70 to 80 percent range is considered a solid result, especially when increasing GPU count by a factor of five. Hitting 90 percent, Salvator noted, “basically has [engineers] doing happy dances.” Nvidia attributes the efficiency to its NVLink fabric, overlapping computation/communication strategy, tuned collective-communications libraries (NCCL), and InfiniBand networking all working in concert. Time-To-Train Gains, Not Just Raw Throughput Across the seven workloads in MLPerf Training 5.0, Blackwell improved time-to-convergence by “up to 2.6 ×” at constant GPU count compared with the Hopper-generation H100. The largest jumps showed up in image generation and LLM pre-training, where parameter counts and memory pressure are highest. In this benchmark, time to convergence refers to how long it takes a system to train a model until it reaches a preset level of accuracy, and faster results directly reflect how quickly a system can develop a usable model, reducing both experimentation time and compute costs. These speed-ups translate directly into shorter R&D cycles, or as Nvidia pitched it, better “training performance per dollar.” The cost angle is easy to overlook in a benchmark dominated by record times, yet Nvidia stressed that faster completion means less time renting cloud instances and lower energy bills for on-prem deployments. While the company did not publish power-efficiency data this round, it positioned Blackwell as “more economical” on a per-job basis, suggesting that the company's tensor-core design tweaks are delivering better performance per watt than Hopper. A Heavier LLM Workload Enters the Mix MLPerf Training 5.0 also introduces a new pre-training task based on Llama 3.1 405B, replacing the older GPT-3-175B test. Doubling the parameter count pushes memory bandwidth, interconnect traffic, and optimizer performance in ways the previous model did not. Nvidia was the only vendor to submit on this fresh workload, setting an initial reference point for 405-billion-parameter training. This matters because early adopters are already stretching beyond the 70–80B parameter class for frontier models. Demonstrating a validated recipe at 405B gives engineers a clearer picture of what it will take, both in GPU hours and in cluster fabric, to bring these next-gen models online. Training Still Matters in an Inference-Obsessed Market During the press call, Nvidia fielded a common question: why focus on training when industry chatter is currently centered on inference? Dave Salvator argued that fine-tuning (post-training) remains a key prerequisite for production LLMs, particularly for enterprises sitting on proprietary data. He framed training as the “investment phase” that unlocks return later in inference-heavy deployments. That approach fits with the company’s larger “AI factory” concept, where racks of GPUs supply data and power to train models, which then produce tokens for use in real-world applications. These include newer “reasoning tokens” used in agentic AI systems. MLPerf’s time-to-train metric aligns well with this production-line model. Hopper Stays in the Mix Nvidia also re-submitted Hopper results to underscore that H100 remains “the only architecture other than Blackwell” posting leadership numbers across the full MLPerf Training suite. With H100 instances widely available at cloud providers, the company appears eager to reassure customers that existing deployments still make architectural sense, even as GB200 rolls out on Microsoft Azure, Google Cloud, and CoreWeave. What Wasn’t Shown Two absences stood out: Power results. Lenovo submitted the only G

Nvidia’s latest MLPerf Training 5.0 results show its Blackwell GB200 accelerators sprinting through record time-to-train scores, showing how the company’s rack-scale “AI-factory” design can turn raw compute into deployable models more quickly than before.
Using 34 72-GPU NVLink domains combined into a 2,496-GPU cluster, the system sustained 1,829 teraflops (roughly 1.8 petaflops) of measured application throughput while maintaining 90 percent scaling efficiency. Additionally, it was the only submission to complete the suite’s new 405-billion-parameter Llama-3.1 workload, making this Nvidia’s most ambitious MLPerf showing to date.
Blackwell’s Debut at Scale
Nvidia submitted results for its GB200 NVL72 systems – 72 Blackwell GPUs linked by fifth-generation NVLink and NVSwitch fabric – at a cluster scale of 2,496 GPUs. Working with cloud partners CoreWeave and IBM, the company reported 90 % strong-scaling efficiency when expanding from 512 to 2,496 devices. That figure is notable, as linear scaling is rarely achieved beyond a few hundred GPUs.

A compute tray in the GB200 NVL72 rack. (Source: Nvidia)
“What we achieved was phenomenal scaling efficiency,” said Dave Salvator, Nvidia director of accelerated computing products, in a press briefing. “What you see there is 90% scaling efficiency, which is almost linear scaling.”
In typical large-scale training runs, scaling efficiency in the 70 to 80 percent range is considered a solid result, especially when increasing GPU count by a factor of five. Hitting 90 percent, Salvator noted, “basically has [engineers] doing happy dances.”
Nvidia attributes the efficiency to its NVLink fabric, overlapping computation/communication strategy, tuned collective-communications libraries (NCCL), and InfiniBand networking all working in concert.
Time-To-Train Gains, Not Just Raw Throughput
Across the seven workloads in MLPerf Training 5.0, Blackwell improved time-to-convergence by “up to 2.6 ×” at constant GPU count compared with the Hopper-generation H100. The largest jumps showed up in image generation and LLM pre-training, where parameter counts and memory pressure are highest.
In this benchmark, time to convergence refers to how long it takes a system to train a model until it reaches a preset level of accuracy, and faster results directly reflect how quickly a system can develop a usable model, reducing both experimentation time and compute costs. These speed-ups translate directly into shorter R&D cycles, or as Nvidia pitched it, better “training performance per dollar.”
The cost angle is easy to overlook in a benchmark dominated by record times, yet Nvidia stressed that faster completion means less time renting cloud instances and lower energy bills for on-prem deployments. While the company did not publish power-efficiency data this round, it positioned Blackwell as “more economical” on a per-job basis, suggesting that the company's tensor-core design tweaks are delivering better performance per watt than Hopper.
A Heavier LLM Workload Enters the Mix
MLPerf Training 5.0 also introduces a new pre-training task based on Llama 3.1 405B, replacing the older GPT-3-175B test. Doubling the parameter count pushes memory bandwidth, interconnect traffic, and optimizer performance in ways the previous model did not. Nvidia was the only vendor to submit on this fresh workload, setting an initial reference point for 405-billion-parameter training.
This matters because early adopters are already stretching beyond the 70–80B parameter class for frontier models. Demonstrating a validated recipe at 405B gives engineers a clearer picture of what it will take, both in GPU hours and in cluster fabric, to bring these next-gen models online.
Training Still Matters in an Inference-Obsessed Market

(Source: Nvidia)
During the press call, Nvidia fielded a common question: why focus on training when industry chatter is currently centered on inference? Dave Salvator argued that fine-tuning (post-training) remains a key prerequisite for production LLMs, particularly for enterprises sitting on proprietary data. He framed training as the “investment phase” that unlocks return later in inference-heavy deployments.
That approach fits with the company’s larger “AI factory” concept, where racks of GPUs supply data and power to train models, which then produce tokens for use in real-world applications. These include newer “reasoning tokens” used in agentic AI systems. MLPerf’s time-to-train metric aligns well with this production-line model.
Hopper Stays in the Mix
Nvidia also re-submitted Hopper results to underscore that H100 remains “the only architecture other than Blackwell” posting leadership numbers across the full MLPerf Training suite. With H100 instances widely available at cloud providers, the company appears eager to reassure customers that existing deployments still make architectural sense, even as GB200 rolls out on Microsoft Azure, Google Cloud, and CoreWeave.
What Wasn’t Shown
Two absences stood out:
- Power results. Lenovo submitted the only GB200-based entry in MLPerf’s power measurement category, using a two-node system with 8 Blackwell GPUs per node — far smaller than a full NVL72 configuration. Nvidia said it prioritized scaling GB200 across 2,496 GPUs for this round, but hinted it may submit energy data in a future cycle.
- GB300 preview. Salvator confirmed that next-generation GB300 silicon is slated for late-2025 sampling and was “too soon” for this round. The one-year product cadence on Nvidia’s publicly disclosed roadmap suggests that MLPerf 6.0 could become the launchpad for GB300.
Beyond the Numbers

(Source: Shutterstock)
Underneath the records, this round of MLPerf Training hints at two bigger trends:
- Recipe portability vs. Specialization: Nvidia emphasized using identical “recipes” (data types, optimizer settings, precision) across scaling points, a sign the company wants to prove that performance gains come from architectural capability rather than one-off tuning. That transparency will matter as customers evaluate whether they can replicate lab results in real-world workloads.
- Standardization pressure on emerging tasks: Reasoning-heavy agentic models are not yet part of MLPerf, but committees are discussing how to integrate them. When they arrive, vendors will have to show not just how fast their chips generate tokens, but how quickly they train models capable of multi-step planning and tool use.
The Takeaway
In this round, Nvidia’s GB200 NVL72 systems showed strong time-to-train results and near-linear scaling efficiency across multiple workloads. The results give early adopters confidence that Blackwell can shoulder the next cohort of 100-plus-billion-parameter models while shortening the training path from data ingest to deployable LLM. Yet power metrics and competitor submissions remain outstanding questions that the next MLPerf cycle, and the inevitable GB300 debut, will be under pressure to answer.



