








































































![How to Build an AI Assistant with Keith Moehring [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/MAICON-Speaker_Series%20%281%29.png)






































































































![[The AI Show Episode 156]: AI Answers - Data Privacy, AI Roadmaps, Regulated Industries, Selling AI to the C-Suite & Change Management](https://www.marketingaiinstitute.com/hubfs/ep%20156%20cover.png)
![[The AI Show Episode 155]: The New Jobs AI Will Create, Amazon CEO: AI Will Cut Jobs, Your Brain on ChatGPT, Possible OpenAI-Microsoft Breakup & Veo 3 IP Issues](https://www.marketingaiinstitute.com/hubfs/ep%20155%20cover.png)


































































































































































































































































_incamerastock_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Brain_light_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)























































































![Nothing Phone (3) has a 50MP ‘periscope’ telephoto lens – here are the first samples [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/06/nothing-phone-3-telephoto.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)

















































































Creating an MCP server with Anthropic
Intro There has been a lot of hype on socials recently about MCP or Model Context Protocol. Essentially it's a protocol that allows LLM AI to be extended. Most of the extensions relate to providing context using your own data. This is what I am going to walk through here. I will walk through: Creating an MCP What works and what works better My discoveries so far TLDR If you just want the code - it's here: https://github.com/codecowboydotio/mcp-server-examples Why The reason I decided to initially play around with MCP was because I had a high level of scepticism regarding it. I've seen a LOT of posts on the internet that talk about it, how it's transformational and so on. I thought to myself "I'm going to look into this, but I'm going to do it bottom up and by writing a server". High level overview The following diagram represents a high level overview of what has been built and how it works. ...and don't worry there are more diagrams that show more detail further on :) Where to start I started at the following address: https://modelcontextprotocol.io/introduction This describes the MCP protocol, but also describes some of the capabilities. I then decided to to read through the examples here: https://modelcontextprotocol.io/quickstart/server This is a great example, because it covered my initial use case almost exactly. It's an example of a weather application that is a REST based API. After reading through the example, I decided to set up my development environment and start writing some code. Install the environment In order to install the environment, you need to grab a copy of the Anthropic client, and then install all of the pre-requisite software. https://claude.ai/download Once installed, I needed to get the rest of the development environment up and running. I chose python as the language of choice to develop in - but other SDKs are available (Python, Typescript, Java, Kotlin and C#). I am also running on windows, so my configuration examples will use windows nomenclature. Next it's time to install uv for python, it's an alternative package manager, but you can use pip also if you're more comfortable with it. powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex" Then we create a virtual environment using uv, and activate it (it's the same as any other venv in the pythonic world). # Create a new directory for our project uv init swapi cd swapi # Create virtual environment and activate it uv venv .venv\Scripts\activate # Install dependencies uv add mcp[cli] httpx json requests # Create our server file new-item swapi.py Configure the desktop client In order for your MCP server to be registered, you'll need to configure the desktop client. Claude has a file called claude_desktop_config.json. This is where you will define your MCP server. Essentially it's a way for the local desktop application to run your server. You simply point it at your code. { "mcpServers": { "swapi": { "command": "C:\\Users\\scott\\.local\\bin\\uv", "args": [ "--directory", "C:\\users\\scott\\Desktop\\swapi", "run", "swapi.py" ] } } } From here we are ready to start writing some code. Star Wars API I am running a local version of the star wars API as a container. I also inserted myself into the API as an easy way to validate that my MCP server is asking my API and not deriving data from other sources or its trained dataset. There is a detailed explanation of the API I am using, as this feeds directly into the question of "specific" versus "generalised" for LLM AI models and MCP. The API that I use is quite specific and has a number of routes: You will note that each of the routes has two possible requests: /route/ - Return ALL records /route/{id} - Return a specific record All records All records looks like this: curl -s 10.1.1.150:3000/people/ | more [ { "edited": "2014-12-20T21:17:56.891Z", "name": "Luke Skywalker", "created": "2014-12-09T13:50:51.644Z", "gender": "male", "skin_color": "fair", "hair_color": "blond", "height": "172", "eye_color": "blue", "mass": "77", "homeworld": 1, "birth_year": "19BBY", "image": "luke_skywalker.jpg", "id": 1, "vehicles": [ 14, 30 ], "starships": [ 12, 22 ], "films": [ 1, 2, 3, 6 ] }, { "edited": "2014-12-20T21:17:50.309Z", "name": "C-3PO", "created": "2014-12-10T15:10:51.357Z", "gender": "n/a", "skin_color": "gold", "hair_color": "n/a", "height": "167", "eye_color": "yellow", "mass": "75", "homeworld": 1, "birth_year": "112BBY", "image": "c-3po.jpg", "id": 2, "vehicles": [], "starship

Intro
There has been a lot of hype on socials recently about MCP or Model Context Protocol. Essentially it's a protocol that allows LLM AI to be extended. Most of the extensions relate to providing context using your own data.
This is what I am going to walk through here.
I will walk through:
- Creating an MCP
- What works and what works better
- My discoveries so far
TLDR
If you just want the code - it's here:
https://github.com/codecowboydotio/mcp-server-examples
Why
The reason I decided to initially play around with MCP was because I had a high level of scepticism regarding it. I've seen a LOT of posts on the internet that talk about it, how it's transformational and so on. I thought to myself "I'm going to look into this, but I'm going to do it bottom up and by writing a server".
High level overview
The following diagram represents a high level overview of what has been built and how it works.
...and don't worry there are more diagrams that show more detail further on :)
Where to start
I started at the following address:
https://modelcontextprotocol.io/introduction
This describes the MCP protocol, but also describes some of the capabilities.
I then decided to to read through the examples here:
https://modelcontextprotocol.io/quickstart/server
This is a great example, because it covered my initial use case almost exactly. It's an example of a weather application that is a REST based API.
After reading through the example, I decided to set up my development environment and start writing some code.
Install the environment
In order to install the environment, you need to grab a copy of the Anthropic client, and then install all of the pre-requisite software.
Once installed, I needed to get the rest of the development environment up and running. I chose python as the language of choice to develop in - but other SDKs are available (Python, Typescript, Java, Kotlin and C#).
I am also running on windows, so my configuration examples will use windows nomenclature.
Next it's time to install uv for python, it's an alternative package manager, but you can use pip also if you're more comfortable with it.
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
Then we create a virtual environment using uv, and activate it (it's the same as any other venv in the pythonic world).
# Create a new directory for our project
uv init swapi
cd swapi
# Create virtual environment and activate it
uv venv
.venv\Scripts\activate
# Install dependencies
uv add mcp[cli] httpx json requests
# Create our server file
new-item swapi.py
Configure the desktop client
In order for your MCP server to be registered, you'll need to configure the desktop client.
Claude has a file called claude_desktop_config.json.
This is where you will define your MCP server. Essentially it's a way for the local desktop application to run your server. You simply point it at your code.
{
"mcpServers": {
"swapi": {
"command": "C:\\Users\\scott\\.local\\bin\\uv",
"args": [
"--directory",
"C:\\users\\scott\\Desktop\\swapi",
"run",
"swapi.py"
]
}
}
}
From here we are ready to start writing some code.
Star Wars API
I am running a local version of the star wars API as a container.
I also inserted myself into the API as an easy way to validate that my MCP server is asking my API and not deriving data from other sources or its trained dataset.
There is a detailed explanation of the API I am using, as this feeds directly into the question of "specific" versus "generalised" for LLM AI models and MCP.
The API that I use is quite specific and has a number of routes:

You will note that each of the routes has two possible requests:
/route/ - Return ALL records
/route/{id} - Return a specific record
All records
All records looks like this:
curl -s 10.1.1.150:3000/people/ | more
[
{
"edited": "2014-12-20T21:17:56.891Z",
"name": "Luke Skywalker",
"created": "2014-12-09T13:50:51.644Z",
"gender": "male",
"skin_color": "fair",
"hair_color": "blond",
"height": "172",
"eye_color": "blue",
"mass": "77",
"homeworld": 1,
"birth_year": "19BBY",
"image": "luke_skywalker.jpg",
"id": 1,
"vehicles": [
14,
30
],
"starships": [
12,
22
],
"films": [
1,
2,
3,
6
]
},
{
"edited": "2014-12-20T21:17:50.309Z",
"name": "C-3PO",
"created": "2014-12-10T15:10:51.357Z",
"gender": "n/a",
"skin_color": "gold",
"hair_color": "n/a",
"height": "167",
"eye_color": "yellow",
"mass": "75",
"homeworld": 1,
"birth_year": "112BBY",
"image": "c-3po.jpg",
"id": 2,
"vehicles": [],
"starships": [],
"films": [
1,
2,
3,
4,
5,
6
]
},
It is returned as a JSON array.
Note the id element. The API is keyed on id. So when I get an individual people instance, I will see the following:
Single record
A single record looks like this
curl -s 10.1.1.150:3000/people/1 | more
{
"edited": "2014-12-20T21:17:56.891Z",
"name": "Luke Skywalker",
"created": "2014-12-09T13:50:51.644Z",
"gender": "male",
"skin_color": "fair",
"hair_color": "blond",
"height": "172",
"eye_color": "blue",
"mass": "77",
"homeworld": 1,
"birth_year": "19BBY",
"image": "luke_skywalker.jpg",
"id": 1,
"vehicles": [
14,
30
],
"starships": [
12,
22
],
"films": [
1,
2,
3,
6
]
}
My own record
I inserted myself as record id 84.
The idea here is that this is the ultimate test of not only the MCP server, but is also a test of generalised reasoning.
curl -s http://10.1.1.150:3000/people/84
{
"edited": "2014-12-20T21:17:56.891Z",
"name": "Scott",
"created": "2014-12-09T13:50:51.644Z",
"gender": "male",
"skin_color": "fair",
"hair_color": "blonde",
"height": "184",
"eye_color": "blue",
"mass": "01",
"homeworld": 1,
"birth_year": "19BBY",
"image": "luke_skywalker.jpg",
"id": 84,
"vehicles": [],
"starships": [],
"films": []
}
Basic MCP server
Initially I thought like a REST API dev, and built the diagram below:

I wrote an MCP server (based on the example server) that pulls back a single person from the star wars database.
The flow
I used the code from the example server, and charged ahead with typical REST based "query for the smallest thing" logic.
A diagram of the MCP tool flow is below:

- Client is asked "get swapi character id 1"
- MCP tool calls make_request
- make_request queries the external API
- external API returns a JSON value for a single person with the ID of 1
- The make_request function returns RAW JSON data to the MCP tool
- The MCP tool called the format_msg function.
- The format_msg function makes a secondary call to the API to resolve the planet name
- The SWAPI API returns the planet information for a single planet
- The format_msg function parses the JSON responses and formats a message
- The formatted response is sent back to the client
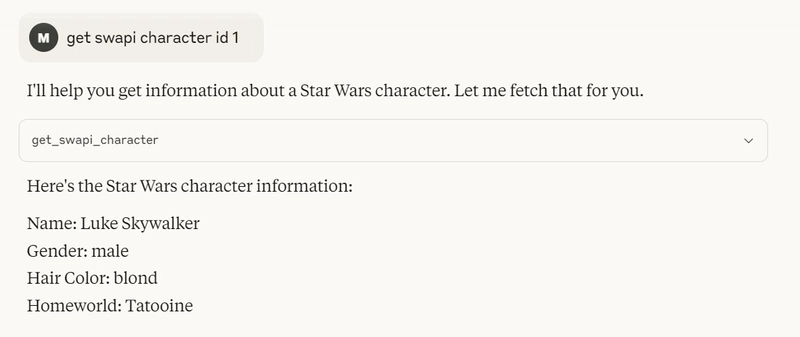
In the desktop application it looks like this:
The code
The code is below.
The code is relatively straightforward.
from typing import Any
import httpx
import json
import requests
from mcp.server.fastmcp import FastMCP
# Initialize FastMCP server
mcp = FastMCP("swapi")
# Constants
API_BASE = "http://10.1.1.150:3000"
USER_AGENT = "swapi-app/1.0"
async def make_request(url: str) -> dict[str, Any] | None:
"""Make a request to the API with proper error handling."""
headers = {
"User-Agent": USER_AGENT,
"Accept": "application/json"
}
async with httpx.AsyncClient() as client:
try:
response = await client.get(url, headers=headers, timeout=30.0)
response.raise_for_status()
return response.json()
except Exception:
return None
def format_msg(json_string):
"""Format an alert feature into a readable string."""
props = json_string
homeworld=json_string['homeworld']
homeworld_url="http://10.1.1.150:3000/planets/" + str(homeworld)
homeworld_name = requests.get(homeworld_url)
homeworld_json=json.loads(homeworld_name.text)
return f"""
Name: {props.get('name', 'Unknown')}
Gender: {props.get('gender', 'Unknown')}
Hair Colour: {props.get('hair_color', 'Unknown')}
Homeworld: {homeworld_json.get('name', 'Unknown')}
"""
@mcp.tool()
async def get_swapi_character(id: str) -> str:
"""Get name from swapi api.
Args:
id: exact name match
"""
url = f"{API_BASE}/people/{id}"
data = await make_request(url)
if not data:
return "Unable to fetch data from API."
#alerts = [format_alert(feature) for feature in data["features"]]
msg = format_msg(data)
return msg
if __name__ == "__main__":
# Initialize and run the server
mcp.run(transport='stdio')
Note that the MCP tool is making a specific request for an ID.
The results
The results are very interesting. There are differences between specific searching and just dumping large datasets into the LLM and getting the LLM to do the heavy lifting via more generalised searching.
Specific searching
When searching for a specific character, I get a single set of results. This is a great start and it matches my single record above. Note that the response is formatted in the same way that my function returns it.

Next I retrieve another character with an ID of 84. This corresponds to the character that I added to the database of the API. It's me!

The interesting part here, is that while my MCP server has been used to get the result, additional context and reasoning has been applied to this answer. The additional reasoning says that this character is also from planet 1 (Tatooine) and is not fetured as part of the official star wars canon of characters.
When I ask a second time, the answer becomes more refined, and specific.

Finally, I ask claude to give me characters that appear in my search but do not appear in other sources. Note that this answer does not use my MCP server.

Generalised searching
I can also perform more generalised searching using the results that I have so far.

I can compare the characters that I have.
This made me wonder what would happen if I had a much larger dataset.
I altered the code to pull in ALL people.
I changed the url on my mcp server to be /people rather than requiring a specific ID.
@mcp.tool()
#async def get_swapi_character(id: str) -> str:
async def get_swapi_character():
"""Get name from swapi api.
Args:
id: exact name match
"""
url = f"{API_BASE}/people/"
data = await make_request(url)
if not data:
return "Unable to fetch data from API."
#alerts = [format_alert(feature) for feature in data["features"]]
#msg = format_msg(data)
#return "\n---\n".join(msg)
return data
if __name__ == "__main__":
# Initialize and run the server
mcp.run(transport='stdio')
This allows me to perform a much less specific search. I automatically pull back ALL star wars characters, and then claude searches the result set to find a specific things that I am searching for.

Note that above the search uses a more generalised search through the entire dataset to find exactly what I want. The search still uses my MCP server even though it is more generalised in nature.
The response section of my search still sends a blank search request because I don't need anything to be sent, but ALL possible star wars characters are returned.

This is an important concept. The larger the data source you send to the model, the more you are able to search through it and combine answers.
Combined answers
Now that I have a larger data set, I can combine answers, and splice the data however I need to.

This answer does not require running the MCP server again, as the original result set is still within the same conversation.
Conclusion
Writing my own MCP server was very instructive and helped me a lot with being able to understand the MCP protocol a lot. I learned that having a larger data set will give you better answers. I also learned that this pattern is almost like an anti pattern of the current API design and thought process. Rather than querying an API for the smallest possible unit of data (like /people/1) it's better from an LLM perspective to import a larger and more complete set of data. This allows thorough searching and splicing of the datasets by the LLM.
Other than this, it was a lot of fun to do, and has helped me to be able to discern more useful AI / LLM / MCP content that I see in other places.
I encourage everyone to have a go and give this a try.


