











































































































































































![[The AI Show Episode 155]: The New Jobs AI Will Create, Amazon CEO: AI Will Cut Jobs, Your Brain on ChatGPT, Possible OpenAI-Microsoft Breakup & Veo 3 IP Issues](https://www.marketingaiinstitute.com/hubfs/ep%20155%20cover.png)


































































































































































































































































































































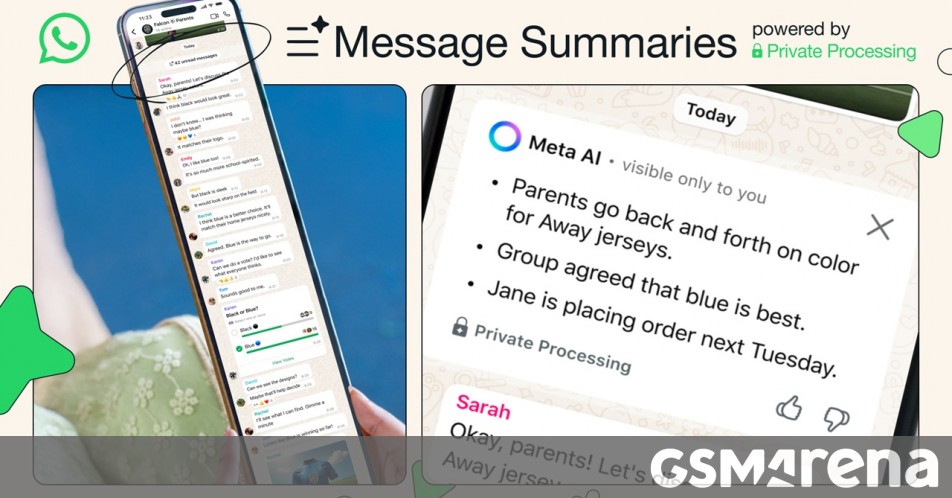
















































![Mercedes, Audi, Volvo Reject Apple's New CarPlay Ultra [Report]](https://www.iclarified.com/images/news/97711/97711/97711-640.jpg)



























































ETH and Stanford Researchers Introduce MIRIAD: A 5.8M Pair Dataset to Improve LLM Accuracy in Medical AI
Challenges of LLMs in Medical Decision-Making: Addressing Hallucinations via Knowledge Retrieval LLMs are set to revolutionize healthcare through intelligent decision support and adaptable chat-based assistants. However, a major challenge is their tendency to produce factually incorrect medical information. To address this, a common solution is RAG, where external medical knowledge is broken into smaller text […] The post ETH and Stanford Researchers Introduce MIRIAD: A 5.8M Pair Dataset to Improve LLM Accuracy in Medical AI appeared first on MarkTechPost.

Challenges of LLMs in Medical Decision-Making: Addressing Hallucinations via Knowledge Retrieval
LLMs are set to revolutionize healthcare through intelligent decision support and adaptable chat-based assistants. However, a major challenge is their tendency to produce factually incorrect medical information. To address this, a common solution is RAG, where external medical knowledge is broken into smaller text pieces that LLMs can retrieve and use during generation. While promising, current RAG methods depend on unstructured medical content that is often noisy, unfiltered, and difficult for LLMs to interpret effectively. There is a clear need for better organization and presentation of medical knowledge to ensure LLMs can use it more reliably and accurately.
Limitations of Current RAG Approaches in Healthcare AI
Though LLMs perform impressively across general language tasks, they often fall short in domains requiring up-to-date and precise knowledge, such as medicine. RAG offers a cost-effective alternative to expensive fine-tuning by grounding models in external literature. Yet, many current RAG systems rely on general-purpose text embeddings and standard vector databases, which are not optimized for medical content. Unlike in general domains, the medical field lacks large, high-quality datasets pairing medical questions with relevant answers. Existing datasets, such as PubMedQA or MedQA, are either too small, overly structured (e.g., multiple-choice), or lack the kind of open-ended, real-world responses needed to build strong medical retrieval systems.
MIRIAD Dataset: Structuring Medical QA with Peer-Reviewed Grounding
Researchers from ETH Zurich, Stanford, the Mayo Clinic, and other institutions have developed MIRIAD, a large-scale dataset comprising over 5.8 million high-quality medical instruction-response pairs. Each pair is carefully rephrased and grounded in peer-reviewed literature through a semi-automated process involving LLMs, filters, and expert review. Unlike prior unstructured datasets, MIRIAD offers structured, retrievable medical knowledge, boosting LLM accuracy on complex medical QA tasks by up to 6.7% and improving hallucination detection by 22.5–37%. They also launched MIRIAD-Atlas, a visual tool encompassing 56 medical fields, which enables users to explore and interact with this rich resource, thereby enhancing trustworthy AI in healthcare.
Data Pipeline: Filtering and Structuring Medical Literature Using LLMs and Classifiers
To build MIRIAD, researchers filtered 894,000 medical articles from the S2ORC corpus and broke them into clean, sentence-based passages, excluding overly long or noisy content. They used LLMs with structured prompts to generate over 10 million question-answer pairs, later refining this to 5.8 million through rule-based filtering. A custom-trained classifier, based on GPT-4 labels, helped further narrow it down to 4.4 million high-quality pairs. Human medical experts also validated a sample for accuracy, relevance, and grounding. Finally, they created MIRIAD-Atlas, an interactive 2D map of the dataset, using embedding and dimensionality reduction to cluster related content by topic and discipline.
Performance Gains: Enhancing QA Accuracy and Hallucination Detection Using MIRIAD
The MIRIAD dataset significantly improves the performance of large language models on medical tasks. When used in RAG, models achieved up to 6.7% higher accuracy compared to using unstructured data, even with the same amount of retrieved content. MIRIAD also enhanced the ability of models to detect medical hallucinations, with F1 score improvements ranging from 22.5% to 37%. Additionally, training retriever models on MIRIAD resulted in improved retrieval quality. The dataset’s structure, grounded in verified literature, enables more precise and reliable access to information, supporting a wide range of downstream medical applications.

MIRIAD-Atlas: Visual Exploration Across 56 Medical Fields
In conclusion, MIRIAD is a large, structured dataset comprising 5.8 million medical question-answer pairs, grounded in peer-reviewed literature, and built to support a range of medical AI applications. It includes an interactive atlas for easy exploration and incorporates rigorous quality control through automated filters, LLM assessments, and expert reviews. Unlike previous unstructured corpora, MIRIAD improves retrieval accuracy in medical question answering and can help identify hallucinations in language models. While not yet exhaustive, it lays a strong foundation for future datasets. Continued improvements could enable more accurate, user-involved retrieval and better integration with clinical tools and medical AI systems.
Check out the Paper, GitHub Page and Dataset on Hugging Face. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post ETH and Stanford Researchers Introduce MIRIAD: A 5.8M Pair Dataset to Improve LLM Accuracy in Medical AI appeared first on MarkTechPost.


