





































































































![How to Build an AI Assistant with Keith Moehring [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/MAICON-Speaker_Series%20%281%29.png)
![[The AI Show Episode 156]: AI Answers - Data Privacy, AI Roadmaps, Regulated Industries, Selling AI to the C-Suite & Change Management](https://www.marketingaiinstitute.com/hubfs/ep%20156%20cover.png)
![[The AI Show Episode 155]: The New Jobs AI Will Create, Amazon CEO: AI Will Cut Jobs, Your Brain on ChatGPT, Possible OpenAI-Microsoft Breakup & Veo 3 IP Issues](https://www.marketingaiinstitute.com/hubfs/ep%20155%20cover.png)


































































































































































































































































_incamerastock_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Brain_light_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































![Senators reintroduce App Store bill to rein in ‘gatekeeper power in the app economy’ [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/06/app-store-senate.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










































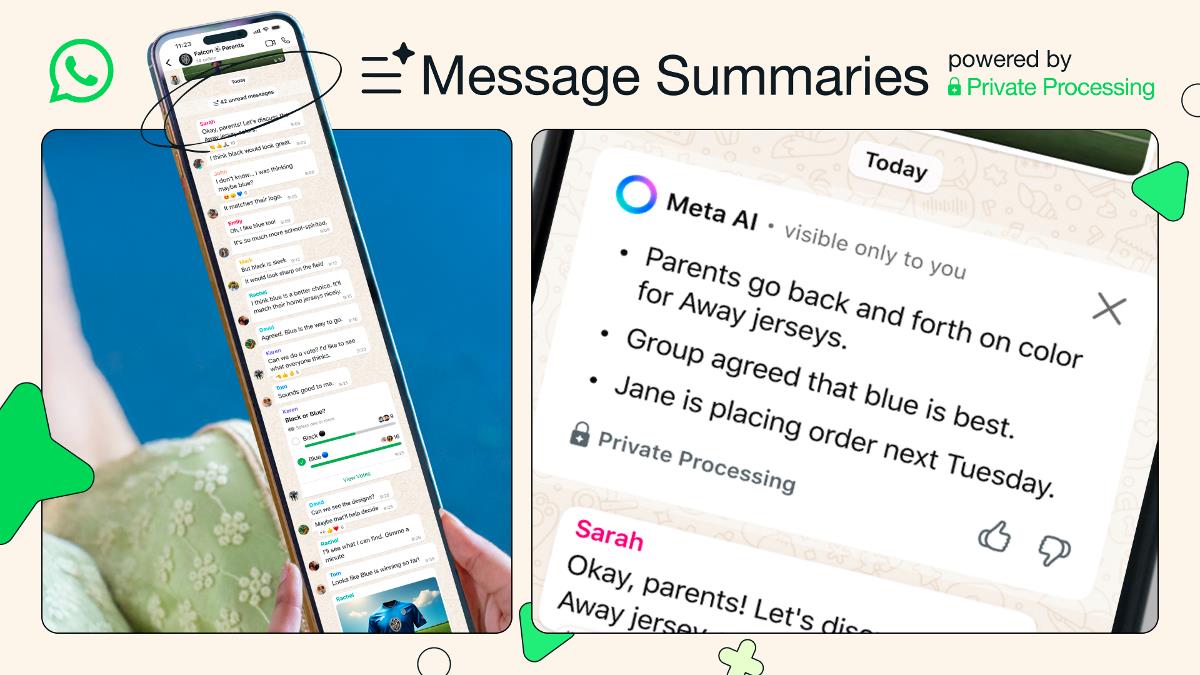







































AWS Databases Decoded: Your Ultimate Guide to Picking the Perfect Service in 2025
Intro : The Database Dilemma Picture this: you're architecting a new application on AWS. Everything's humming along – compute, networking, CI/CD... and then you hit the data layer. Suddenly, you're faced with a bewildering array of AWS database services. Relational? NoSQL? Serverless? Which one is "best"? If you've ever felt that paralysis of choice, you're not alone! Choosing the right AWS database service is one of the most critical decisions you'll make. It impacts performance, scalability, cost, and even developer productivity. In today's data-driven world, getting this wrong can be a costly mistake. But fear not! This post is your guide through the AWS database landscape. We'll demystify the options, explore use cases, and equip you to make informed decisions that set your projects up for success in 2025 and beyond. Table of Contents Why Choosing the Right AWS Database Matters Understanding AWS Database Categories in Simple Terms Deep Dive into Key AWS Database Services Relational Databases (RDS & Aurora) Key-Value & Document Databases (DynamoDB & DocumentDB) Graph Databases (Neptune) Time Series Databases (Timestream) Ledger Databases (QLDB) Data Warehouses (Redshift) In-Memory Databases (ElastiCache) Real-World Use Case: Architecting a Social Media App's Data Layer Common Mistakes and Pitfalls (And How to Avoid Them!) Pro Tips and Hidden Features for AWS Databases Conclusion & Your Next Steps Why Choosing the Right AWS Database Matters In the cloud, flexibility is king. But with great flexibility comes great responsibility, especially with databases. Why is this choice so pivotal? Performance & Scalability: A mismatch between your workload and database type can lead to sluggish performance and scaling nightmares. A relational database might struggle with the massive, unstructured data a NoSQL database handles with ease (and vice-versa). Cost Optimization: AWS offers various pricing models (on-demand, provisioned, serverless). Choosing a database that aligns with your access patterns and capacity needs can save you significant money. Over-provisioning is a common budget-drainer. Developer Productivity: Working with a database that naturally fits your data model and query patterns makes development faster and more intuitive. Forcing a square peg into a round hole leads to complex workarounds. Operational Overhead: Managed services like RDS and DynamoDB reduce operational burden, but understanding their nuances is key. Picking a service that's overly complex for your needs can increase this burden unnecessarily. Future-Proofing: While migrations are possible, they are often complex and risky. Making a thoughtful choice upfront can save you major headaches down the line. The sheer volume of data being generated is staggering. IDC predicts that the global datasphere will grow to 175 zettabytes by 2025. AWS is constantly innovating in the database space to help manage this explosion. Recent re:Invent announcements often feature enhancements to existing services (like Aurora Serverless v2 improvements or new DynamoDB features) and sometimes entirely new database offerings. Staying informed is crucial! Understanding AWS Database Categories in Simple Terms Let's break down the main categories of databases AWS offers. Think of it like choosing the right tool for a job: you wouldn't use a hammer to screw in a nail! Relational Databases (SQL): Analogy: Think of highly organized spreadsheets (tables) with strict columns (schema) and clear relationships between them (e.g., a Customers table linked to an Orders table via CustomerID). Good for: Traditional applications, ERP systems, CRM, e-commerce where data consistency and structured queries are paramount (ACID compliance). AWS Services: Amazon RDS (MySQL, PostgreSQL, MariaDB, SQL Server, Oracle), Amazon Aurora. NoSQL Databases (Non-Relational): A broad category for databases that don't follow the traditional relational model. They offer flexibility in schema and often scale horizontally. Key-Value Stores: Analogy: A giant, super-fast dictionary or hash map. You store a value (like user session data) associated with a unique key (like session_id). Good for: Caching, session management, user profiles, real-time bidding. High-volume, low-latency lookups. AWS Service: Amazon DynamoDB, Amazon ElastiCache for Redis/Memcached (often used as key-value stores). Document Databases: Analogy: Storing data in flexible, self-describing documents, like JSON or BSON. Each document can have its own structure. Think of a filing cabinet where each folder (document) contains related information. Good for: Content management, catalogs, user profiles, mobile apps where data structures evolve. AWS Services: Amazon DynamoDB (can be used as a document store), Amazon DocumentDB (with MongoDB compatibility). Graph Databases
Intro : The Database Dilemma
Picture this: you're architecting a new application on AWS. Everything's humming along – compute, networking, CI/CD... and then you hit the data layer. Suddenly, you're faced with a bewildering array of AWS database services. Relational? NoSQL? Serverless? Which one is "best"? If you've ever felt that paralysis of choice, you're not alone!
Choosing the right AWS database service is one of the most critical decisions you'll make. It impacts performance, scalability, cost, and even developer productivity. In today's data-driven world, getting this wrong can be a costly mistake. But fear not! This post is your guide through the AWS database landscape. We'll demystify the options, explore use cases, and equip you to make informed decisions that set your projects up for success in 2025 and beyond.
Table of Contents
- Why Choosing the Right AWS Database Matters
- Understanding AWS Database Categories in Simple Terms
- Deep Dive into Key AWS Database Services
- Relational Databases (RDS & Aurora)
- Key-Value & Document Databases (DynamoDB & DocumentDB)
- Graph Databases (Neptune)
- Time Series Databases (Timestream)
- Ledger Databases (QLDB)
- Data Warehouses (Redshift)
- In-Memory Databases (ElastiCache)
- Real-World Use Case: Architecting a Social Media App's Data Layer
- Common Mistakes and Pitfalls (And How to Avoid Them!)
- Pro Tips and Hidden Features for AWS Databases
- Conclusion & Your Next Steps
Why Choosing the Right AWS Database Matters
In the cloud, flexibility is king. But with great flexibility comes great responsibility, especially with databases. Why is this choice so pivotal?
- Performance & Scalability: A mismatch between your workload and database type can lead to sluggish performance and scaling nightmares. A relational database might struggle with the massive, unstructured data a NoSQL database handles with ease (and vice-versa).
- Cost Optimization: AWS offers various pricing models (on-demand, provisioned, serverless). Choosing a database that aligns with your access patterns and capacity needs can save you significant money. Over-provisioning is a common budget-drainer.
- Developer Productivity: Working with a database that naturally fits your data model and query patterns makes development faster and more intuitive. Forcing a square peg into a round hole leads to complex workarounds.
- Operational Overhead: Managed services like RDS and DynamoDB reduce operational burden, but understanding their nuances is key. Picking a service that's overly complex for your needs can increase this burden unnecessarily.
- Future-Proofing: While migrations are possible, they are often complex and risky. Making a thoughtful choice upfront can save you major headaches down the line.
The sheer volume of data being generated is staggering. IDC predicts that the global datasphere will grow to 175 zettabytes by 2025. AWS is constantly innovating in the database space to help manage this explosion. Recent re:Invent announcements often feature enhancements to existing services (like Aurora Serverless v2 improvements or new DynamoDB features) and sometimes entirely new database offerings. Staying informed is crucial!
Understanding AWS Database Categories in Simple Terms
Let's break down the main categories of databases AWS offers. Think of it like choosing the right tool for a job: you wouldn't use a hammer to screw in a nail!
-
Relational Databases (SQL):
- Analogy: Think of highly organized spreadsheets (tables) with strict columns (schema) and clear relationships between them (e.g., a
Customerstable linked to anOrderstable viaCustomerID). - Good for: Traditional applications, ERP systems, CRM, e-commerce where data consistency and structured queries are paramount (ACID compliance).
- AWS Services: Amazon RDS (MySQL, PostgreSQL, MariaDB, SQL Server, Oracle), Amazon Aurora.
- Analogy: Think of highly organized spreadsheets (tables) with strict columns (schema) and clear relationships between them (e.g., a
-
NoSQL Databases (Non-Relational): A broad category for databases that don't follow the traditional relational model. They offer flexibility in schema and often scale horizontally.
- Key-Value Stores:
- Analogy: A giant, super-fast dictionary or hash map. You store a value (like user session data) associated with a unique key (like
session_id). - Good for: Caching, session management, user profiles, real-time bidding. High-volume, low-latency lookups.
- AWS Service: Amazon DynamoDB, Amazon ElastiCache for Redis/Memcached (often used as key-value stores).
- Analogy: A giant, super-fast dictionary or hash map. You store a value (like user session data) associated with a unique key (like
- Document Databases:
- Analogy: Storing data in flexible, self-describing documents, like JSON or BSON. Each document can have its own structure. Think of a filing cabinet where each folder (document) contains related information.
- Good for: Content management, catalogs, user profiles, mobile apps where data structures evolve.
- AWS Services: Amazon DynamoDB (can be used as a document store), Amazon DocumentDB (with MongoDB compatibility).
- Graph Databases:
- Analogy: A social network map. Focuses on relationships (edges) between data points (nodes).
- Good for: Recommendation engines, fraud detection, social networking, knowledge graphs.
- AWS Service: Amazon Neptune.
- Time Series Databases:
- Analogy: A specialized logbook for data points timestamped in chronological order.
- Good for: IoT sensor data, application monitoring, financial data analysis.
- AWS Service: Amazon Timestream.
- Ledger Databases:
- Analogy: An immutable, cryptographically verifiable transaction log, like a bank's ledger. Once data is written, it cannot be altered or deleted.
- Good for: Systems of record, supply chain tracking, financial audits where data integrity and history are critical.
- AWS Service: Amazon Quantum Ledger Database (QLDB).
- Key-Value Stores:
-
Data Warehouses:
- Analogy: A massive, centralized repository designed for heavy-duty analytics and business intelligence rather than transactional processing.
- Good for: Complex analytical queries, reporting, BI dashboards.
- AWS Service: Amazon Redshift.
-
In-Memory Databases:
- Analogy: A database that keeps data primarily in RAM for lightning-fast access.
- Good for: Caching, real-time analytics, gaming leaderboards, session stores.
- AWS Service: Amazon ElastiCache (for Redis and Memcached), DynamoDB Accelerator (DAX).
Deep Dive into Key AWS Database Services
Let's zoom in on some of the most popular AWS database services.
Relational Databases (RDS & Aurora)
-
Amazon RDS (Relational Database Service):
- What it is: A managed service that makes it easy to set up, operate, and scale a relational database in the cloud. Supports popular engines: MySQL, PostgreSQL, MariaDB, Oracle, SQL Server.
- Use Cases: Web and mobile applications, e-commerce platforms, CRM systems, financial applications.
- Pricing: Based on instance hours, storage, I/O, data transfer. Reserved Instances can offer significant savings.
- Key Features: Automated patching, backups, read replicas for scalability, Multi-AZ for high availability.
-
Amazon Aurora:
- What it is: A MySQL and PostgreSQL-compatible relational database built for the cloud. Offers higher performance and availability than standard MySQL/PostgreSQL on RDS.
- Use Cases: High-throughput applications, enterprise applications requiring greater scalability and resilience.
- Pricing: Similar to RDS but often more cost-effective at scale due to its architecture. Pay for storage used, not provisioned.
- Key Features: Auto-scaling storage (up to 128TB), fault-tolerant and self-healing, Global Database, Aurora Serverless for on-demand auto-scaling.
CLI Example (RDS - Creating a MySQL instance):
aws rds create-db-instance \
--db-instance-identifier my-rds-instance \
--db-instance-class db.t3.micro \
--engine mysql \
--master-username myadmin \
--master-user-password mysecurepassword123 \
--allocated-storage 20 \
--backup-retention-period 7 \
--multi-az # For high availability
Key-Value & Document Databases (DynamoDB & DocumentDB)
- Amazon DynamoDB:
- What it is: A fast, flexible NoSQL database service for applications that need consistent, single-digit millisecond latency at any scale. It's a fully managed, multi-region, multi-active, durable database with built-in security, backup and restore, and in-memory caching.
- Use Cases: Mobile apps, gaming, ad tech, IoT, serverless applications (often paired with Lambda). Ideal for high-traffic web applications, e-commerce systems, and any application requiring low-latency data access.
- Pricing: Based on provisioned/on-demand read/write capacity units (RCUs/WCUs), storage, and optional features like Global Tables or DAX.
- Key Features: Schema-less (flexible data model), auto-scaling (on-demand mode), Global Tables for multi-region replication, DynamoDB Accelerator (DAX) for in-memory caching, Point-in-Time Recovery (PITR).
Boto3 Snippet (DynamoDB - Put and Get Item):
import boto3
# Ensure your AWS credentials and region are configured
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('YourTableName') # Replace with your table name
# Put an item
try:
table.put_item(
Item={
'userId': 'user123',
'username': 'janedoe',
'email': 'jane.doe@example.com',
'preferences': {
'theme': 'dark',
'notifications': True
}
}
)
print("Item added successfully!")
except Exception as e:
print(f"Error adding item: {e}")
# Get an item
try:
response = table.get_item(
Key={
'userId': 'user123'
}
)
item = response.get('Item')
if item:
print(f"Retrieved item: {item}")
else:
print("Item not found.")
except Exception as e:
print(f"Error retrieving item: {e}")
- Amazon DocumentDB (with MongoDB compatibility):
- What it is: A fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads.
- Use Cases: Applications currently using MongoDB that want a managed service, content management, catalogs, user profiles.
- Pricing: Based on instance hours, storage, I/O.
- Key Features: MongoDB compatibility, high availability and durability through replication across Availability Zones.

Graph Databases (Neptune)
- Amazon Neptune:
- What it is: A fast, reliable, fully managed graph database service that makes it easy to build and run applications that work with highly connected datasets. Supports popular graph models Property Graph (Apache TinkerPop Gremlin) and W3C's RDF (SPARQL).
- Use Cases: Social networking, recommendation engines, fraud detection, knowledge graphs, network security analysis.
- Pricing: Based on instance hours, storage, I/O, and data transfer.
- Key Features: Optimized for graph queries, high availability, read replicas.
Time Series Databases (Timestream)
- Amazon Timestream:
- What it is: A fast, scalable, and serverless time series database service for IoT and operational applications that makes it easy to store and analyze trillions of events per day.
- Use Cases: Storing and analyzing IoT sensor data, DevOps metrics, application logs, clickstream data.
- Pricing: Based on writes, data stored (memory & magnetic tier), and queries scanned.
- Key Features: Serverless, auto-scaling, data lifecycle management (moving data from memory to magnetic store), built-in analytics functions.
Ledger Databases (QLDB)
- Amazon Quantum Ledger Database (QLDB):
- What it is: A fully managed ledger database that provides a transparent, immutable, and cryptographically verifiable transaction log.
- Use Cases: Systems of record, auditing, supply chain tracking, financial transaction history, digital identity verification.
- Pricing: Based on journal storage, indexed storage, data written, and I/O requests.
- Key Features: Immutability, cryptographic verifiability, serverless, SQL-like query language (PartiQL).
Data Warehouses (Redshift)
- Amazon Redshift:
- What it is: A fast, fully managed, petabyte-scale data warehouse service.
- Use Cases: Business intelligence, analytics, reporting, data mining on large datasets.
- Pricing: Based on node type and number of nodes (Provisioned Clusters) or Redshift Processing Units (RPUs) for Serverless.
- Key Features: Columnar storage for fast querying, massively parallel processing (MPP), Redshift Spectrum for querying data in S3, Concurrency Scaling.
In-Memory Databases (ElastiCache)
- Amazon ElastiCache:
- What it is: A web service that makes it easy to deploy, operate, and scale an in-memory cache in the cloud. Supports two open-source in-memory caching engines: Redis and Memcached.
- Use Cases: Caching database query results, session management, real-time leaderboards, rate limiting. Significantly reduces latency and load on your primary database.
- Pricing: Based on node type and hours.
- Key Features: Sub-millisecond latency, managed service (patching, monitoring), support for Redis clusters for scalability.
Real-World Use Case: Architecting a Social Media App's Data Layer
Let's imagine we're building "CloudConnect," a new social media application. How would we choose our databases? We'll likely need a mix:
-
User Profiles & Authentication:
- Data: User ID, username, email (hashed password managed by Cognito), profile picture URL, bio, preferences.
- Choice: Amazon DynamoDB.
- Why: User profiles are often key-value lookups (
userId-> profile data). DynamoDB offers low latency, high scalability for millions of users, and flexible schema for evolving profile attributes. Can also use RDS Aurora if strong relational needs exist, but DynamoDB often fits better for massive scale. - Setup Notes: Use
userIdas the partition key. Consider Global Secondary Indexes (GSIs) for lookups byusernameoremail.
-
Posts, Comments, Likes (The Feed):
- Data: Post ID, user ID, content, timestamp, likes count, comments.
- Choice: Amazon DynamoDB.
- Why: High write and read volume. Timelines/feeds require fast retrieval of recent posts. DynamoDB's scalability and flexible schema are ideal. Use single-table design patterns for efficient querying.
- Setup Notes: Complex data modeling here. Often involves a combination of partition keys (e.g.,
userIdfor user's own posts) and sort keys (e.g.,timestamporpostId). GSIs are critical for feed generation.
-
Follower/Following Relationships (Social Graph):
- Data: Who follows whom.
- Choice: Amazon Neptune.
- Why: This is a classic graph problem (users are nodes, "follows" are edges). Neptune is optimized for queries like "Who are Jane's followers?" or "Mutual friends between John and Jane."
- Alternative: For simpler, smaller-scale needs, DynamoDB with adjacency list patterns can work, but Neptune excels for complex graph traversals.
-
Real-time Notifications:
- Data: Notification type, recipient, timestamp, link to content.
- Choice: Amazon DynamoDB (potentially with Streams enabling Lambda triggers for real-time delivery via SNS or WebSockets).
- Why: High-velocity writes for new notifications, fast reads for user notification feeds.
-
Caching Layer:
- Data: Frequently accessed user profiles, popular posts, feed components.
- Choice: Amazon ElastiCache for Redis.
- Why: To reduce load on primary databases and improve read latency for hot data. Redis provides rich data structures.
-
Analytics & Reporting:
- Data: User engagement metrics, content popularity trends, growth statistics.
- Choice: Amazon Redshift.
- Why: For complex analytical queries on large volumes of historical data. Data can be ETL'd from DynamoDB (e.g., via AWS Glue or DynamoDB export to S3) into Redshift.
Security & Cost Notes for CloudConnect:
- Security: Always use IAM roles with least privilege for services accessing databases. Encrypt data at rest and in transit. Use VPC endpoints for private connectivity. Implement robust security groups and network ACLs.
- Cost: Start with on-demand capacity for DynamoDB and smaller instances for RDS/Neptune/ElastiCache. Monitor usage closely with CloudWatch and AWS Cost Explorer. Optimize DynamoDB RCUs/WCUs based on actual traffic. Consider Reserved Instances or Savings Plans for predictable workloads.

Common Mistakes and Pitfalls (And How to Avoid Them!)
Choosing the wrong database or misconfiguring it can lead to headaches. Here are some common traps:
-
One-Size-Fits-All Mentality:
- Mistake: Trying to use a single database type (e.g., only relational) for every part of a complex application.
- Avoidance: Embrace polyglot persistence. Use the right tool for the job, even if it means using multiple database types.
-
Ignoring Data Access Patterns (Especially with NoSQL):
- Mistake: Choosing DynamoDB without deeply understanding how your application will query the data. This leads to inefficient scans or needing too many GSIs.
- Avoidance: Design your DynamoDB table structure around your queries. This is a fundamental shift from relational design.
-
Underestimating Scalability Needs (or Over-provisioning):
- Mistake: Picking a database that can't scale to meet peak demand, or conversely, massively over-provisioning resources and wasting money.
- Avoidance: Load test your application. Use auto-scaling features where available (e.g., Aurora Auto Scaling, DynamoDB On-Demand). Monitor metrics and adjust capacity.
-
Treating Managed Services Like Self-Hosted:
- Mistake: For RDS, trying to SSH into the instance for OS-level tweaks (you can't, and shouldn't need to). Forgetting about automated backups or Multi-AZ.
- Avoidance: Understand the managed service contract. Leverage the features AWS provides (patching, backups, failover).
-
Neglecting Security Best Practices:
- Mistake: Using root credentials, overly permissive IAM roles, public S3 buckets for backups, not encrypting data.
- Avoidance: Follow the principle of least privilege. Encrypt data at rest (e.g., KMS with RDS, DynamoDB server-side encryption) and in transit (SSL/TLS). Use security groups and NACLs diligently.
-
Not Planning for Data Migration & Evolution:
- Mistake: Assuming the initial schema or database choice will last forever without any changes.
- Avoidance: Consider how your data model might evolve. For migrations, explore AWS Database Migration Service (DMS) and Schema Conversion Tool (SCT) early on.
-
Misunderstanding Consistency Models:
- Mistake: Expecting strong consistency from a database designed for eventual consistency (or vice-versa) without configuring it appropriately or understanding the trade-offs.
- Avoidance: Understand the consistency guarantees of your chosen database (e.g., DynamoDB offers strongly consistent reads at a higher RCU cost).
Pro Tips and Hidden Features for AWS Databases
Level up your AWS database game with these tips:
-
RDS Performance Insights:
- What: A powerful tool for RDS that helps you quickly diagnose performance bottlenecks by visualizing database load and wait events.
- Tip: Enable it! It's often more insightful than just looking at CloudWatch CPU/memory metrics.
-
DynamoDB Global Tables:
- What: Fully managed, multi-region, multi-active database replication.
- Tip: For applications needing low-latency access for users across different geographic regions and high availability. It simplifies building global apps.
-
DynamoDB Time To Live (TTL):
- What: Automatically deletes items from your tables after a specified timestamp, at no extra cost for the deletes.
- Tip: Perfect for session data, logs, or any transient information. Saves on storage and avoids manual cleanup.
-
Aurora Serverless v2:
- What: Scales database capacity up or down instantly and granularly based on application demand.
- Tip: Ideal for intermittent or unpredictable workloads. Can be more cost-effective than provisioned instances if your load varies significantly. Pay only for capacity consumed.
-
Redshift Spectrum:
- What: Allows you to run SQL queries directly against exabytes of data in Amazon S3 without loading or transforming it.
- Tip: Extend your data warehouse to a data lake. Great for infrequently accessed data or ad-hoc analysis on raw S3 data.
-
AWS Database Migration Service (DMS) & Schema Conversion Tool (SCT):
- What: DMS helps you migrate databases to AWS easily and securely. SCT helps convert your source database schema and code to a format compatible with your target database.
- Tip: Essential for migrating on-premises databases to AWS or for heterogeneous migrations (e.g., Oracle to Aurora PostgreSQL).
-
IAM Database Authentication (RDS & Aurora):
- What: Authenticate to your database instances using IAM users and roles instead of traditional database passwords.
- Tip: Centralizes access control, simplifies credential management (no more hardcoded passwords in apps!), and leverages IAM's robust security features.
-
DynamoDB Accelerator (DAX):
- What: An in-memory cache for DynamoDB that delivers up to a 10x performance improvement – from milliseconds to microseconds.
- Tip: For read-heavy applications with extremely low latency requirements. Transparently caches hot items.
Conclusion & Your Next Steps
Choosing the right AWS database is a journey, not a destination. It involves understanding your application's needs, data characteristics, access patterns, and the strengths of each AWS service. Don't be afraid to use multiple database services if it makes sense for different parts of your application (polyglot persistence).
Key Takeaways:
- No single "best" database: The "right" choice depends on your specific use case.
- Understand the categories: Relational, Key-Value, Document, Graph, etc., each serves different needs.
- Prioritize data modeling: Especially crucial for NoSQL databases like DynamoDB.
- Leverage managed services: Let AWS handle the undifferentiated heavy lifting.
- Continuously monitor and optimize: For performance and cost.
Further Learning:
- AWS Databases Official Page: aws.amazon.com/products/databases/
- Specific Service FAQs: Each AWS database service has a detailed FAQ page (e.g., RDS FAQ, DynamoDB FAQ).
- AWS Well-Architected Framework (Reliability & Performance Pillars): Provides guidance on database design.
- AWS Certified Database - Specialty: If you want to go deep, this certification is a great goal.

I hope this guide has armed you with the knowledge to confidently navigate the AWS database landscape! It's a vast and fascinating area, and getting it right can make all the difference.
What are your biggest challenges when choosing an AWS database? What are your favorite tips or services? Share your thoughts in the comments below!
If this post helped you, please consider:
- Following me here on Dev.to for more deep dives into AWS and cloud technologies!
- Leaving a comment or bookmarking this post for future reference.
- Connecting with me on LinkedIn: LinkedIn
Happy architecting!