








































































![How to Build an AI Assistant with Keith Moehring [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/MAICON-Speaker_Series%20%281%29.png)






































































































![[The AI Show Episode 156]: AI Answers - Data Privacy, AI Roadmaps, Regulated Industries, Selling AI to the C-Suite & Change Management](https://www.marketingaiinstitute.com/hubfs/ep%20156%20cover.png)
![[The AI Show Episode 155]: The New Jobs AI Will Create, Amazon CEO: AI Will Cut Jobs, Your Brain on ChatGPT, Possible OpenAI-Microsoft Breakup & Veo 3 IP Issues](https://www.marketingaiinstitute.com/hubfs/ep%20155%20cover.png)


































































































































































































































































_incamerastock_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Brain_light_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)










































































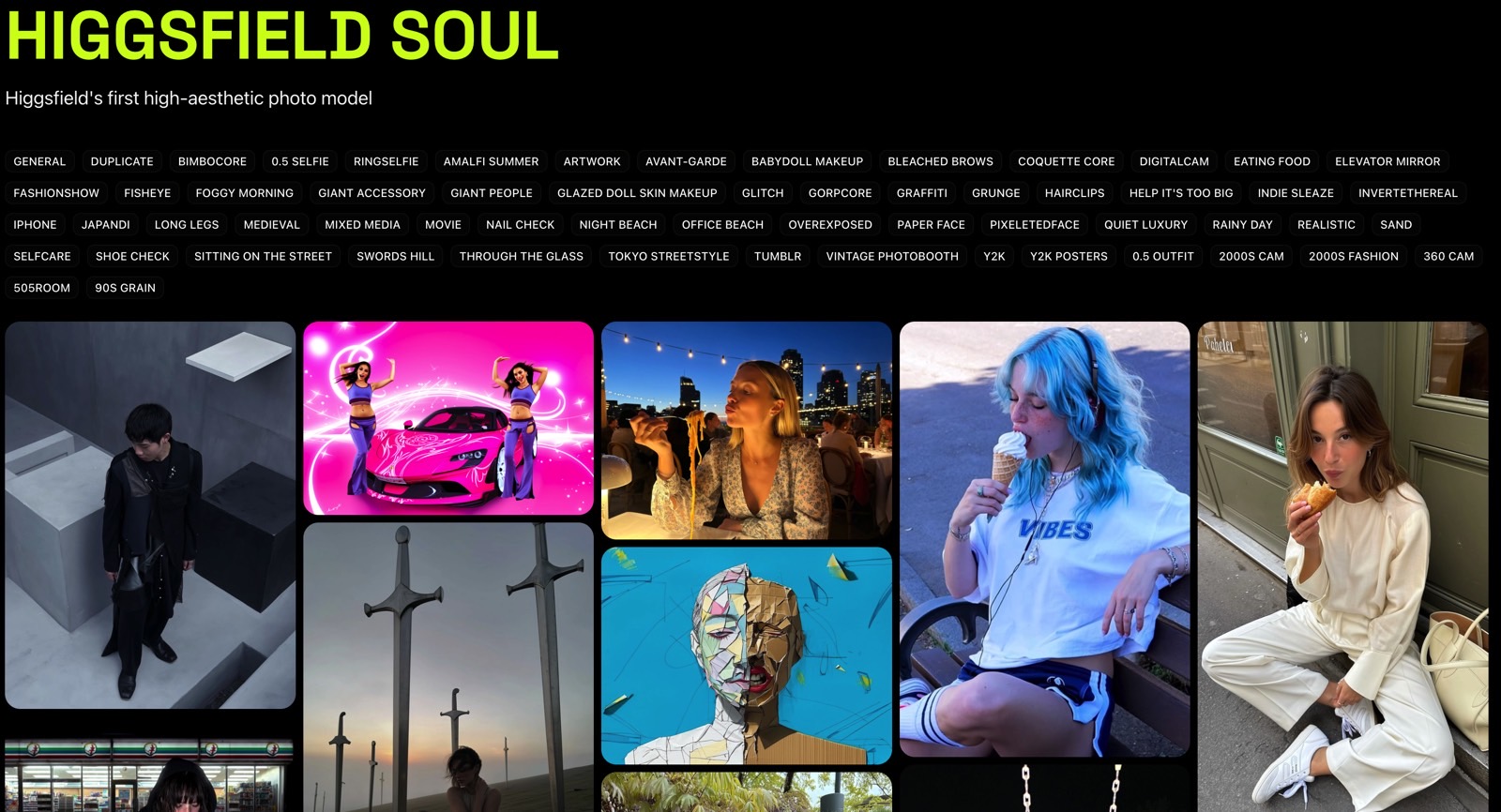
















![Nothing Phone (3) has a 50MP ‘periscope’ telephoto lens – here are the first samples [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/06/nothing-phone-3-telephoto.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)





































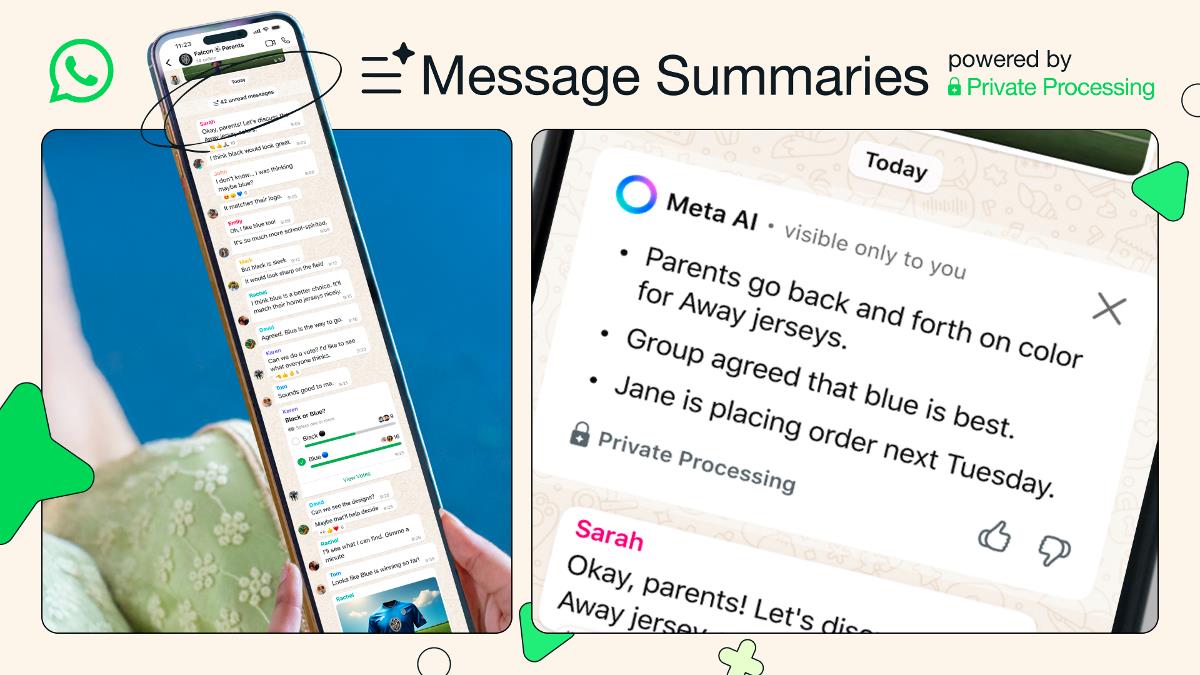








































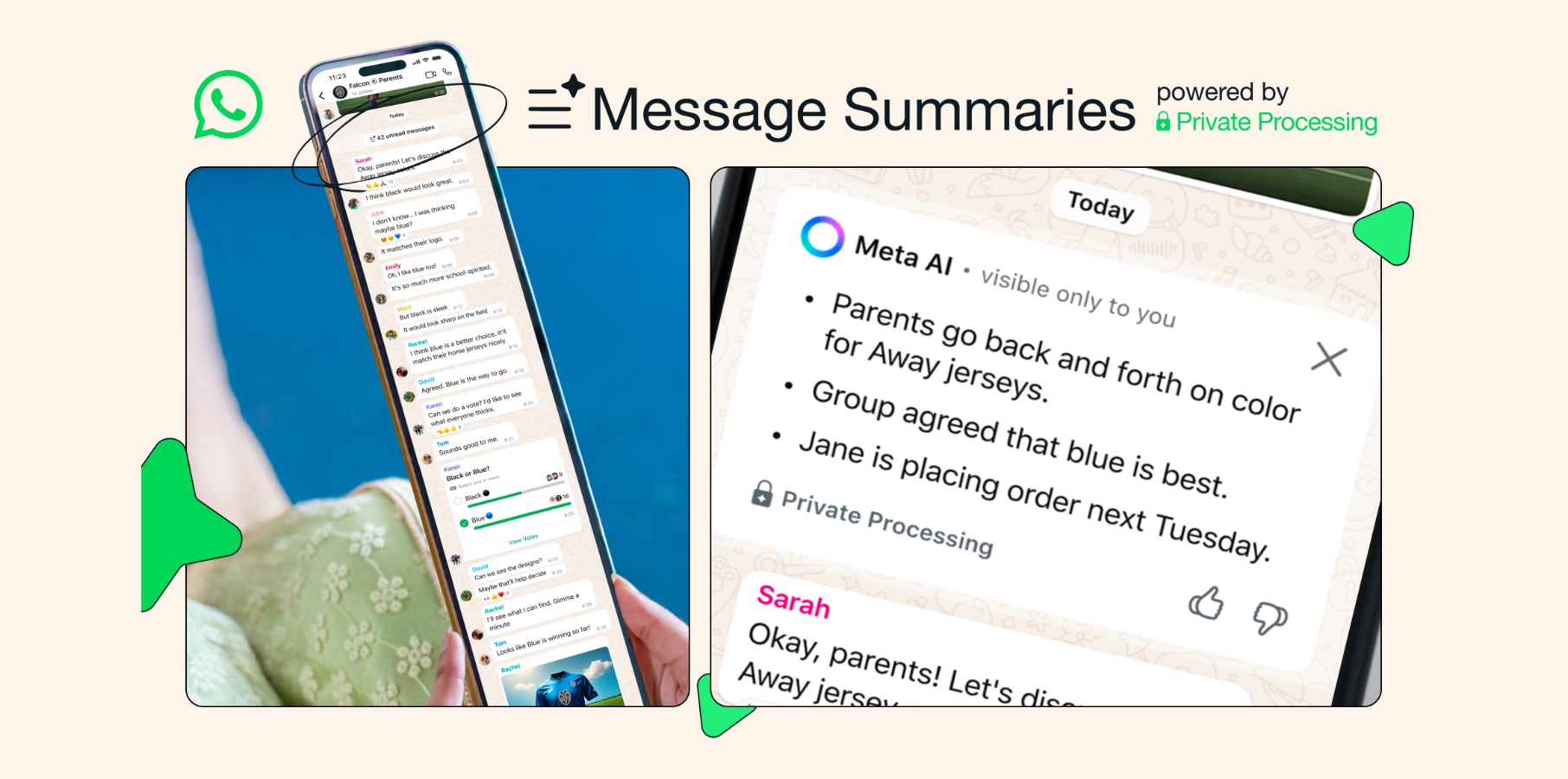
What is NMT?
Neural machine translation (NMT) is an approach to machine translation that uses an artificial neural network to predict the likelihood of a sequence of words, typically modeling entire sentences in a single integrated model. It is the dominant approach today[1]: 293 [2]: 1 and can produce translations that rival human translations when translating between high-resource languages under specific conditions.[3] However, there still remain challenges, especially with languages where less high-quality data is available,[4][5][1]: 293 and with domain shift between the data a system was trained on and the texts it is supposed to translate.[1]: 293 NMT systems also tend to produce fairly literal translations. NMT has overcome several challenges that were present in statistical machine translation (SMT): NMT's full reliance on continuous representation of tokens overcame sparsity issues caused by rare words or phrases. Models were able to generalize more effectively.[18]: 1 [37]: 900–901 The limited n-gram length used in SMT's n-gram language models caused a loss of context. NMT systems overcome this by not having a hard cut-off after a fixed number of tokens and by using attention to choosing which tokens to focus on when generating the next token.[37]: 900–901 End-to-end training of a single model improved translation performance and also simplified the whole process. [citation needed] The huge n-gram models (up to 7-gram) used in SMT required large amounts of memory,[38]: 88 whereas NMT requires less. As outlined in the history section above, instead of using an NMT system that is trained on parallel text, one can also prompt a generative LLM to translate a text. These models differ from an encoder-decoder NMT system in a number of ways:[35]: 1 Generative language models are not trained on the translation task, let alone on a parallel dataset. Instead, they are trained on a language modeling objective, such as predicting the next word in a sequence drawn from a large dataset of text. This dataset can contain documents in many languages, but is in practice dominated by English text.[36] After this pre-training, they are fine-tuned on another task, usually to follow instructions.[39] Since they are not trained on translation, they also do not feature an encoder-decoder architecture. Instead, they just consist of a transformer's decoder. In order to be competitive on the machine translation task, LLMs need to be much larger than other NMT systems. E.g., GPT-3 has 175 billion parameters,[40]: 5 while mBART has 680 million[34]: 727 and the original transformer-big has “only” 213 million.[31]: 9 This means that they are computationally more expensive to train and use. A generative LLM can be prompted in a zero-shot fashion by just asking it to translate a text into another language without giving any further examples in the prompt. Or one can include one or several example translations in the prompt before asking to translate the text in question. This is then called one-shot or few-shot learning, respectively. For example, the following prompts were used by Hendy et al. (2023) for zero-shot and one-shot translation.

Neural machine translation (NMT) is an approach to machine translation that uses an artificial neural network to predict the likelihood of a sequence of words, typically modeling entire sentences in a single integrated model.
It is the dominant approach today[1]: 293 [2]: 1 and can produce translations that rival human translations when translating between high-resource languages under specific conditions.[3] However, there still remain challenges, especially with languages where less high-quality data is available,[4][5][1]: 293 and with domain shift between the data a system was trained on and the texts it is supposed to translate.[1]: 293 NMT systems also tend to produce fairly literal translations.
NMT has overcome several challenges that were present in statistical machine translation (SMT):
NMT's full reliance on continuous representation of tokens overcame sparsity issues caused by rare words or phrases. Models were able to generalize more effectively.[18]: 1 [37]: 900–901
The limited n-gram length used in SMT's n-gram language models caused a loss of context. NMT systems overcome this by not having a hard cut-off after a fixed number of tokens and by using attention to choosing which tokens to focus on when generating the next token.[37]: 900–901
End-to-end training of a single model improved translation performance and also simplified the whole process.
[citation needed]
The huge n-gram models (up to 7-gram) used in SMT required large amounts of memory,[38]: 88 whereas NMT requires less.
As outlined in the history section above, instead of using an NMT system that is trained on parallel text, one can also prompt a generative LLM to translate a text. These models differ from an encoder-decoder NMT system in a number of ways:[35]: 1
Generative language models are not trained on the translation task, let alone on a parallel dataset. Instead, they are trained on a language modeling objective, such as predicting the next word in a sequence drawn from a large dataset of text. This dataset can contain documents in many languages, but is in practice dominated by English text.[36] After this pre-training, they are fine-tuned on another task, usually to follow instructions.[39]
Since they are not trained on translation, they also do not feature an encoder-decoder architecture. Instead, they just consist of a transformer's decoder.
In order to be competitive on the machine translation task, LLMs need to be much larger than other NMT systems. E.g., GPT-3 has 175 billion parameters,[40]: 5 while mBART has 680 million[34]: 727 and the original transformer-big has “only” 213 million.[31]: 9 This means that they are computationally more expensive to train and use.
A generative LLM can be prompted in a zero-shot fashion by just asking it to translate a text into another language without giving any further examples in the prompt. Or one can include one or several example translations in the prompt before asking to translate the text in question. This is then called one-shot or few-shot learning, respectively. For example, the following prompts were used by Hendy et al. (2023) for zero-shot and one-shot translation.


