![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)

































































































































































































































.jpeg?#)





-Pokemon-GO---Official-Gigantamax-Pokemon-Trailer-00-02-12.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)



























_Wavebreakmedia_Ltd_IFE-240611_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)














































































































![Apple Shares Official Trailer for 'Echo Valley' Starring Julianne Moore, Sydney Sweeney, Domhnall Gleeson [Video]](https://www.iclarified.com/images/news/97250/97250/97250-640.jpg)

























































































Fine-Tuning Models with Your Own Data, Effortlessly
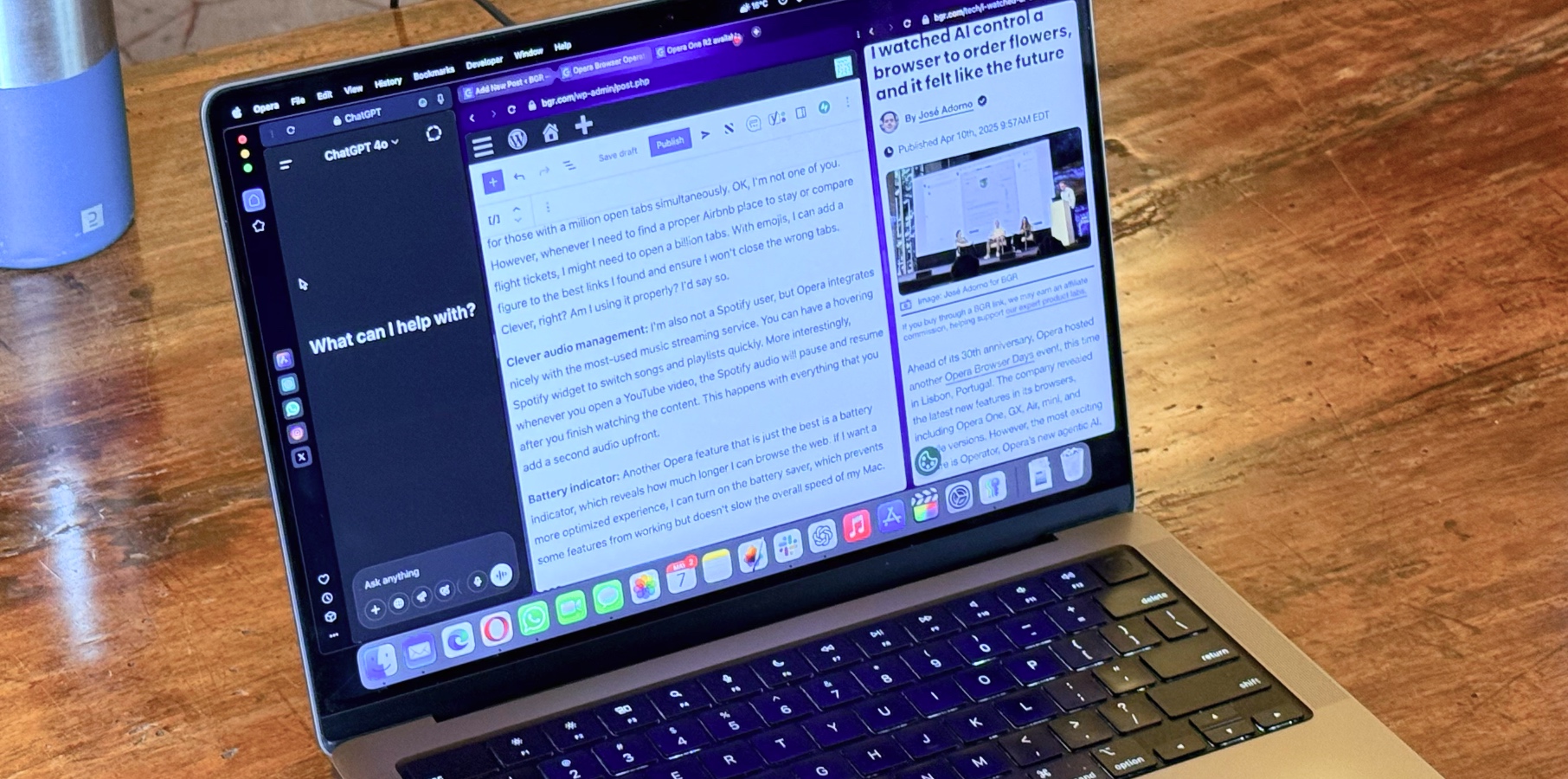
Most blog posts focus on using top-tier LLMs or setting up complex AI pipelines for large corporations. But what if your data is private, and you don’t have access to top-tier ML talent or massive infrastructure? In this article, we show how to fine-tune a model for mid-sized software development teams or IT support, using your own domain expertise. With Apache Answer and InstructLab, you can build a powerful, cost-effective AI solution tailored to your specific needs. InstructLab InstructLab is an open-source AI community project aimed at empowering individuals to shape the future of generative AI. It provides tools for users to fine-tune existing large language models (LLMs), such as Granite, using additional data sources. This allows LLMs to continuously gain new knowledge, filling in gaps from their initial training, including real-time updates on current events. Subject matter experts from any domain can contribute to enhancing the LLMs' knowledge. InstructLab’s collaborative platform fosters community-driven improvements and offers tools for experimenting with model updates and ensuring their quality. LAB: Large-Scale Alignment for ChatBots The taxonomy YAML in InstructLab is a structured file that contains a set of question-answer pairs, organized by domain, to represent specific skills or knowledge. Each YAML file includes metadata like version, task description, contributor info, and example prompts. InstructLab uses these YAML files to generate synthetic training data that fine-tunes open-weight models like Qwen or DeepSeek. By aligning the model with curated, domain-specific content, InstructLab helps improve accuracy and relevance in the model's responses across specialized topics. Apache Answer Apache Answer is similar to Stack Overflow in that it provides a platform for users to ask and answer questions, especially in technical or specialized domains. However, unlike Stack Overflow, Apache Answer is open source and can be fully self-hosted on-premises, giving organizations complete control over their data, customization, and user access. While Stack Overflow is a public, centralized platform mainly focused on general programming and tech topics, Apache Answer can be tailored to any industry or organization. It allows companies to build their own internal knowledge-sharing platforms—whether for software engineering teams, legal departments, medical institutions, or customer support operations. In essence, Apache Answer offers the same collaborative Q&A experience as Stack Overflow but with full ownership, flexibility, and adaptability for private or specialized use. Synthetic data Synthetic data generation is crucial for industries where real-world data cannot be used due to privacy or regulatory concerns. Apache Answer, a Q&A platform similar to StackOverflow, allows organizations to gather relevant industry-specific data and insights from codebases or domain experts. This data can be leveraged for generating high-quality synthetic datasets tailored to specific business needs. InstructLab enhances this process by fine-tuning models to produce contextually accurate synthetic data, ensuring it reflects real-world scenarios. Combined with RAG (Retrieval-Augmented Generation) and CAG (Cache-Augmented Generation), InstructLab enables both real-time and cached synthetic data generation. YAML files produced by Apache Answer contain structured question-answer data that can be used to fine-tune open-source language models. By feeding this data into training workflows, models like Qwen or DeepSeek can be aligned with specific domains or organizational knowledge, improving their accuracy and relevance. Example YAML Q&A RAG & CAG RAG (Retrieval-Augmented Generation) is an AI method that finds the most up-to-date information from external sources every time a question is asked. It combines a search system with a language model so the answers are both current and accurate. CAG (Cache-Augmented Generation) is different. It collects and stores all the needed information in advance. The model then uses this stored data to give fast answers without needing to search each time. With RAG, InstructLab helps improve the model’s ability to follow instructions after retrieving fresh information. Since RAG fetches real-time data, the model needs to blend that information into a clear, helpful response. InstructLab’s fine-tuning methods make the model better at using that external content effectively. With CAG, where information is pre-loaded into a cache, InstructLab helps train the model to give accurate and helpful answers from that fixed data. It can improve how well the model uses the cached knowledge by fine-tuning it on examples that mirror expected questions and answers, ensuring faster and more relevant results. In short, InstructLab makes models better at following instructions and delivering useful answers — whether the data comes in r

Most blog posts focus on using top-tier LLMs or setting up complex AI pipelines for large corporations. But what if your data is private, and you don’t have access to top-tier ML talent or massive infrastructure? In this article, we show how to fine-tune a model for mid-sized software development teams or IT support, using your own domain expertise. With Apache Answer and InstructLab, you can build a powerful, cost-effective AI solution tailored to your specific needs.
InstructLab
InstructLab is an open-source AI community project aimed at empowering individuals to shape the future of generative AI. It provides tools for users to fine-tune existing large language models (LLMs), such as Granite, using additional data sources. This allows LLMs to continuously gain new knowledge, filling in gaps from their initial training, including real-time updates on current events. Subject matter experts from any domain can contribute to enhancing the LLMs' knowledge. InstructLab’s collaborative platform fosters community-driven improvements and offers tools for experimenting with model updates and ensuring their quality.
LAB: Large-Scale Alignment for ChatBots
The taxonomy YAML in InstructLab is a structured file that contains a set of question-answer pairs, organized by domain, to represent specific skills or knowledge. Each YAML file includes metadata like version, task description, contributor info, and example prompts.
InstructLab uses these YAML files to generate synthetic training data that fine-tunes open-weight models like Qwen or DeepSeek. By aligning the model with curated, domain-specific content, InstructLab helps improve accuracy and relevance in the model's responses across specialized topics.
Apache Answer
Apache Answer is similar to Stack Overflow in that it provides a platform for users to ask and answer questions, especially in technical or specialized domains. However, unlike Stack Overflow, Apache Answer is open source and can be fully self-hosted on-premises, giving organizations complete control over their data, customization, and user access.
While Stack Overflow is a public, centralized platform mainly focused on general programming and tech topics, Apache Answer can be tailored to any industry or organization. It allows companies to build their own internal knowledge-sharing platforms—whether for software engineering teams, legal departments, medical institutions, or customer support operations.
In essence, Apache Answer offers the same collaborative Q&A experience as Stack Overflow but with full ownership, flexibility, and adaptability for private or specialized use.
Synthetic data
Synthetic data generation is crucial for industries where real-world data cannot be used due to privacy or regulatory concerns. Apache Answer, a Q&A platform similar to StackOverflow, allows organizations to gather relevant industry-specific data and insights from codebases or domain experts. This data can be leveraged for generating high-quality synthetic datasets tailored to specific business needs.
InstructLab enhances this process by fine-tuning models to produce contextually accurate synthetic data, ensuring it reflects real-world scenarios. Combined with RAG (Retrieval-Augmented Generation) and CAG (Cache-Augmented Generation), InstructLab enables both real-time and cached synthetic data generation.
YAML files produced by Apache Answer contain structured question-answer data that can be used to fine-tune open-source language models. By feeding this data into training workflows, models like Qwen or DeepSeek can be aligned with specific domains or organizational knowledge, improving their accuracy and relevance.
RAG & CAG
RAG (Retrieval-Augmented Generation) is an AI method that finds the most up-to-date information from external sources every time a question is asked. It combines a search system with a language model so the answers are both current and accurate.
CAG (Cache-Augmented Generation) is different. It collects and stores all the needed information in advance. The model then uses this stored data to give fast answers without needing to search each time.
With RAG, InstructLab helps improve the model’s ability to follow instructions after retrieving fresh information. Since RAG fetches real-time data, the model needs to blend that information into a clear, helpful response. InstructLab’s fine-tuning methods make the model better at using that external content effectively.
With CAG, where information is pre-loaded into a cache, InstructLab helps train the model to give accurate and helpful answers from that fixed data. It can improve how well the model uses the cached knowledge by fine-tuning it on examples that mirror expected questions and answers, ensuring faster and more relevant results.
In short, InstructLab makes models better at following instructions and delivering useful answers — whether the data comes in real-time (RAG) or from a pre-built cache (CAG).

Deployment
InstructLab can be installed locally using pip or the uv package manager, making it easy to set up for individual use or testing. Alternatively, it can run inside a Docker container, providing a consistent environment for development and deployment. For scalable production environments, InstructLab can also be deployed on Kubernetes, leveraging its orchestration capabilities to handle scaling and resource management efficiently. This flexibility ensures it adapts to various workflows, from local experimentation to large-scale distributed deployments.
To deploy InstructLab on Kubernetes, use a Makefile to define and manage Kubernetes resources like Deployments and ConfigMaps as multi-line variables. Dynamically generate labels and annotations using Git metadata and environment variables. Validate configurations, enforce constraints, and apply manifests with kubectl. This approach avoids Helm's complexity while maintaining flexibility and transparency.
Time to replace Helm: Back to the Future
git clone https://github.com/avkcode/InstructLab.git
Using kubectl:
kubectl apply -f instructlab.yaml
Using make:
make =>
InstructLab Management System
Available targets:
Deployment:
deploy - Deploy InstructLab with ConfigMap
undeploy - Remove InstructLab deployment
Interaction:
logs - View container logs
status - Show deployment status
Utility:
help - Show this help message
With tools like Apache Answer and InstructLab, you can fine-tune models using your domain knowledge without needing vast resources. You don't need to be a large corporation or have a huge ML team to harness the power of AI for your specific needs.