



















































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






















































































































































![API design for precomputation cache [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)























































































































_NicoElNino_Alamy.png?width=1280&auto=webp&quality=80&disable=upscale#)
_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




























































































![Apple appealing $570M EU fine, White House says it won’t be tolerated [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/Apple-says-570M-EU-fine-is-unfair-White-House-says-it-wont-be-tolerated.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)
















![At Least Three iPhone 17 Models to Feature 12GB RAM [Kuo]](https://www.iclarified.com/images/news/97122/97122/97122-640.jpg)

![Dummy Models Showcase 'Unbelievably' Thin iPhone 17 Air Design [Images]](https://www.iclarified.com/images/news/97114/97114/97114-640.jpg)

























































































































Medical record automation: How a leading underwriting provider transformed their document review process
See how intelligent automation helped a leading underwriter process medical records faster, free up doctors’ time, and streamline life expectancy calculations.


Life insurance companies rely on accurate medical underwriting to determine policy pricing and risk. These calculations come from specialized underwriting firms that analyze patients' medical records in detail. As healthcare digitization has surged from 10% in 2010 to 96% in 2023, these firms now face overwhelming volumes of complex medical documents.
One leading life settlement underwriter found their process breaking under new pressures. Their two-part workflow — an internal team classified documents before doctors reviewed them to calculate life expectancy — was struggling to keep up as their business grew and healthcare documentation became increasingly complex. Medical experts were spending more time sorting through documents instead of analyzing medical histories, creating a growing backlog and rising costs.
This bottleneck threatened their competitive position in an industry projected to grow at twice its historical rate. With accurate underwriting directly impacting policy pricing, even small errors could lead to millions in losses. Now, as the medical industry simultaneously faces worsening workforce shortages, they needed a solution that could transform their document processing while maintaining the precision their business depends on.
This is a story of how they did it.
When medical record volumes get out of hand
Processing 200+ patient case files weekly might sound manageable. However, each case contained a patient's entire medical history — from doctor visits and lab results to hospital stays and specialist consultations. These files ranged from 400 to 10,000 pages per patient. But volume wasn't the only challenge for the medical underwriting provider.
Their business faced mounting pressure from multiple directions. Growing industry volumes meant they had more cases to process. On the flip side, the healthcare industry staffing shortages meant they had to pay doctors and other medical experts top dollars. Their existing manual workflow simply couldn't scale to meet these demands. It was made worse by the fact that they had to maintain near-perfect document classification accuracy for reliable life expectancy calculations.
The business impact was evident:
- Slower processing times meant delayed underwriting decisions
- Inaccurate life expectancy calculations resulted in millions in mispriced policies
- Potentially losing business to more agile competitors
- Higher processing costs directly affected profitability
- Rising costs as doctors spent time on paperwork instead of analysis
Their medical experts' time was their most valuable resource. And yet, despite the 2-step workflow, the sheer volume of documents forced these highly trained professionals to act as expensive document sorters rather than applying their expertise to risk assessment.
The math was simple: every hour doctors spent organizing papers instead of analyzing medical conditions cost the company significantly. This not only increased costs but also limited the number of cases they could handle, directly constraining revenue growth.
What makes healthcare document processing complicated
Let's break down their workflow to understand why their medical record processing workflow was particularly challenging. It began with document classification — sorting hundreds to thousands of pages into categories like lab reports, ECG reports, and chart notes. This critical first step was performed by their six-member team.
Each member could process ~400 digital pages per hour. Meaning, a single case file of 2,000 pages would take over 5 hours to complete. Also, the speed tends to vary heavily based on the complexity of the documents and the capability of the employee.

The process was labor-intensive and time-consuming. With electronic medical records coming from over 230 different systems, each with its own formats and structures, the team had to deal with a lot of variation. It also made automation through traditional template-based data extraction nearly impossible.
The complexity stemmed from how medical information is structured:
- Critical details are spread across multiple pages
- Information needs chronological ordering
- Context from previous pages is often required
- Dates are sometimes missing or implied
- Duplicate pages with slight variations
- Each healthcare provider uses different documentation methods
After classification, the team would manually identify pages containing information relevant to life expectancy calculation and discard irrelevant ones. This meant their staff needed to have an understanding of medical terminology and the significance of various test results and diagnoses. There was very little margin for error because even the slightest errors or omissions could lead to incorrect calculations downstream.
The documents would then be sent to doctors for life expectancy calculation. Doctors mostly did this during their non-clinical hours, which already made them a scarce resource. To make matters worse, despite having employees to handle initial classification, doctors were still forced to spend significant time extracting and verifying data from medical documents because only they possessed the specialized medical knowledge needed to correctly interpret complex medical terminology, lab values, and clinical findings.
Some case files were huge — reaching beyond 10,000 pages. Just imagine the sheer patience and attention to detail required from the team and doctors sifting through all that. That's why when the firm was looking for automation solutions, there was a strong emphasis on achieving nearly 100% classification accuracy, self-learning data extraction, and reducing person-hours.
How the underwriter implemented intelligent document processing for medical records
Medical record volumes were growing, and doctor review costs were mounting. The underwriting team knew they needed to automate their process. But with life expectancy calculations dependent on precise medical details, they couldn't risk any drop in accuracy during the transition.
Their requirements were specific and demanding:
- Ability to process thousands of pages of medical records daily
- Understanding of complex medical relationships across documents
- Classification accuracy had to be near-perfect
- Quick and secure processing without compromising quality
- Integrate out-of-the-box with Amazon S3
That’s when their VP of Operations reached out to us at Nanonets. They discovered that we could help classify medical records with high accuracy, provide a filtered view of significant pages, extract data key points, and ensure seamless data flows within the workflow. This convinced them we could handle their unique challenges.
Here's what the new automated medical records automation workflow looked like:

1. Document preparation
- The internal staff combines all medical records— lab reports, ECG, chart notes, and other miscellaneous documents — for each patient into a single file
- Each patient is assigned a unique number
- A folder with this number is created in the S3 input folder
- 7-10 such cases are uploaded daily
Note: This approach ensures secure handling of patient information and maintains clear organization throughout the process.
2. Document import
- The system checks for new files every hour
- Each case can contain 2000-10,000 pages of medical records
- Files are readied for secured processing through our platform
Note: This automated monitoring ensures consistent processing times and helps maintain the 24-hour turnaround requirement.
3. Document classification
Our AI model analyzes each page based on carefully drafted natural language prompts that help identify medical document types. These prompts guide the AI in understanding the specific characteristics of lab reports, ECG reports, and chart notes.
The classification process involves:
- Identifying document types based on content and structure
- Understanding medical context and terminology
- Maintaining document relationships and chronological order
- Recognizing when context from previous pages is needed
Note: The prompts are continuously refined based on feedback and new document types, ensuring the system maintains high classification accuracy.
4. Data extraction
Our system handles three main document types: lab reports, ECG reports, and chart notes. We have two specialized extraction models to process these documents – one for lab/ECG data and another for chart notes.
Model 1 extracts approximately 50 fields from lab reports and ECG data, including patient name, blood glucose level, creatinine value, glomerular filtration rate, hemoglobin value, prostate specific antigen, white blood cell count, hepatitis value, cholesterol value, and many other critical lab measurements.
Model 2 processes chart notes to extract 13 key fields including blood pressure, heartbeat rate, O2 delivery, O2 flow rate, temperature, date of birth, gender, height, weight, and smoking status. Each data point is linked to its source page and document for verification.
5. Data export
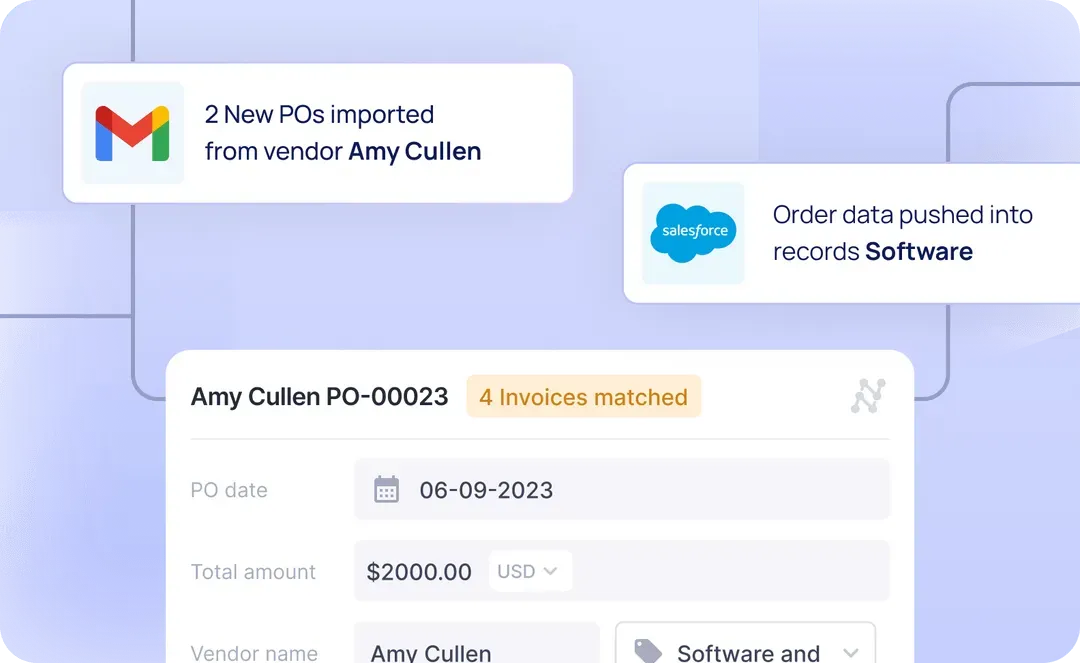
The extracted information is exported as three separate CSV files back to the S3 Bucket — one each for document classification, lab results and ECG, and chart notes.
The classification CSV contains file names, page numbers, classifications, and links to access the original pages. The lab results and ECG CSV contain extracted medical values and measurements, while the chart notes CSV contains relevant medical information from doctors' notes.
In each file name, an identifier, like 'lab results' and 'ECG' or 'chart notes', will be automatically added to identify the content type. And for consistency, CSV files are generated for all categories, even when no relevant pages are found in a case document. Each patient's data will be stored in the Export folder on the S3 bucket under the same identifying number.
6. Validation
The CSV outputs are imported into their internal application, where a two-member validation team (reduced from the original six) reviews the automated classifications. Here, they can compare the extracted data against the original documents, making the verification process quick and efficient.
Once the data is validated, the doctors are notified. They can go ahead to analyze medical histories and calculate life expectancy. Instead of spending hours organizing and reviewing documents, they now work with structured, verified information at their fingertips.
Note: For security and compliance reasons, all processed files are automatically purged from Nanonets servers after 21 days.
The impact of automated medical record processing
With structured data and an efficient validation process, the underwriting provider has been able to minimize the operational bottlenecks involved in the process.
Here’s a quick overview of how much they have been able to achieve within just a month of implementation:
- Four members on the data validation team were reassigned to other roles, so validation now runs smoothly with just 2 people
- Classification accuracy maintained at 97-99%
- Automated workflow is handling ~20% of the total workload
- Complete data classification and extraction for each case file within 24 hours
- Achieve a 5X reduction in the number of pages doctors need to review per case to compute life expectancy
- Freed medical experts to focus on their core expertise
These numbers don't tell the whole story. Before automation, doctors had to sift through thousands of pages because they were the only ones with the necessary context to understand patient data. Now doctors get exactly what they need – detailed medical histories sorted chronologically that are ready for analysis. It's a complete shift from sorting papers to doing actual medical analysis.
This change means they can handle more cases without having to hire more expensive doctors. That's a huge advantage, especially with healthcare facing staff shortages while the industry continues to grow.
Looking ahead
This successful implementation has helped the underwriting provider understand what's possible with intelligent document processing. They now want to scale their medical record processing to cover all ~200 cases weekly. That's not all. They're already exploring how to automate other document-heavy workflows, like trust deed processing.
Thinking about what this means for your organization? The time to modernize document processing is now. Healthcare documentation is becoming more complex, with a 41% growth in high-acuity care and rising chronic condition management. Add to this the growing staffing challenges in healthcare, and it's clear— if you don't modernize, your organization will struggle to keep up.
Want to see similar results with your medical record processing? Let's talk about how Nanonets can help. Schedule a demo now.