

















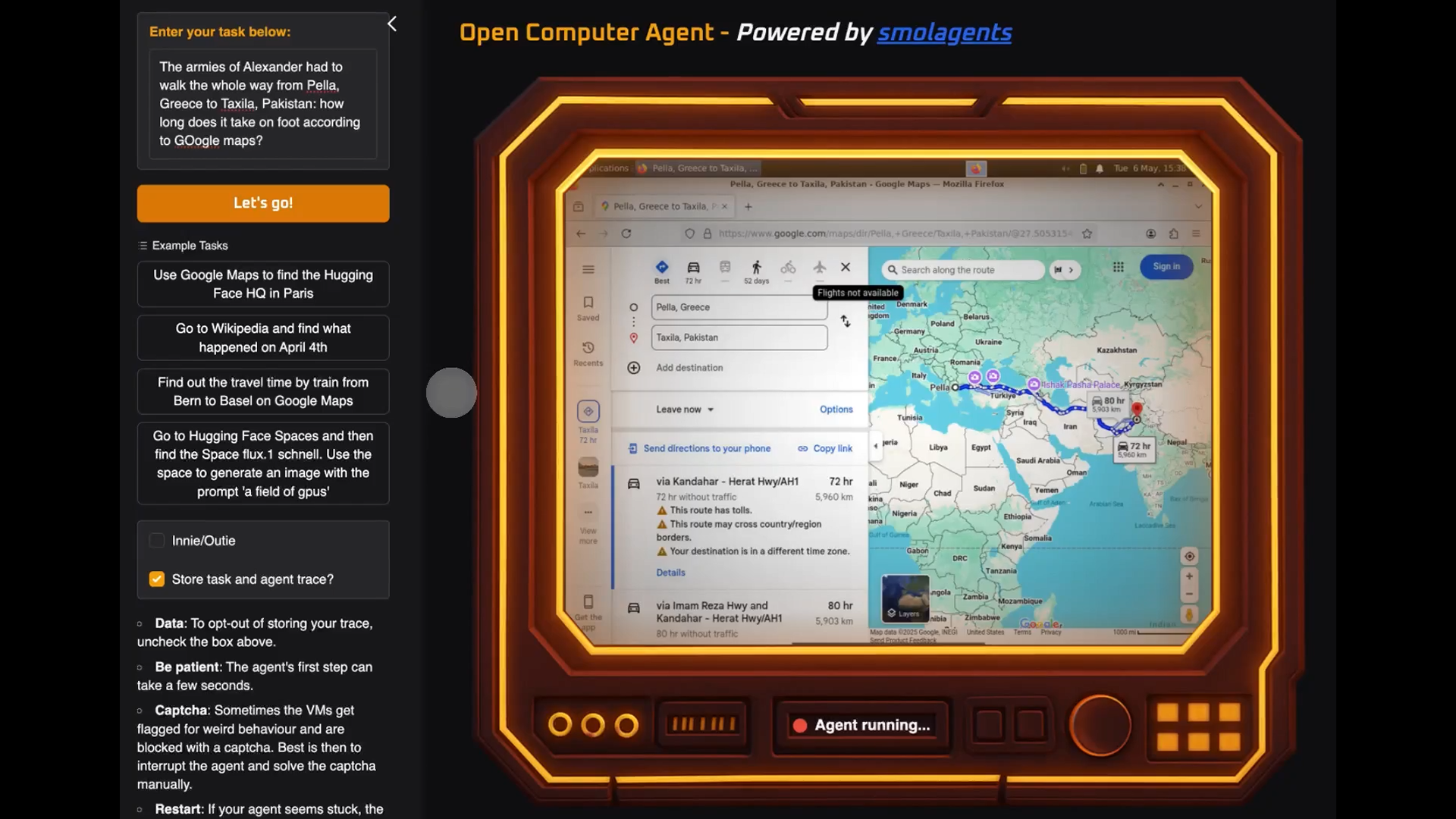

























































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)
































































































































![Ditching a Microsoft Job to Enter Startup Purgatory with Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)



























































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)



































































![[Exclusive] Infinix GT DynaVue: a Prototype that could change everything!](https://www.gizchina.com/wp-content/uploads/images/2025/05/Screen-Shot-2025-05-10-at-16.07.40-PM-copy.png)





























































































-xl.jpg)



























![New iPad 11 (A16) On Sale for Just $277.78! [Lowest Price Ever]](https://www.iclarified.com/images/news/97273/97273/97273-640.jpg)

![Apple Foldable iPhone to Feature New Display Tech, 19% Thinner Panel [Rumor]](https://www.iclarified.com/images/news/97271/97271/97271-640.jpg)


























































































Speech Recognition API for Voice Input
Comprehensive Guide to Speech Recognition API for Voice Input in JavaScript Historical and Technical Context Evolution of Speech Recognition Technologies The journey of speech recognition technology started as early as the 1950s, predominantly focusing on isolated word recognition. Early systems, such as IBM's "Shoebox," recognized a mere 16 words. The evolution accelerated with the advent of hidden Markov models (HMM) in the 1980s, which allowed for continuous speech recognition. The 1990s saw the introduction of statistically based systems, leveraging vast amounts of data to improve accuracy. Fast forward to the 21st century, we witness the proliferation of deep learning techniques, particularly the use of recurrent neural networks (RNN) and convolutional neural networks (CNN), which have drastically improved recognition accuracy. All these advancements have led to the creation of platforms and APIs that allow developers to integrate voice recognition into applications seamlessly. Introduction to the Web Speech API The Web Speech API, emerging in the early 2010s as part of the W3C Web Real-Time Communications (WebRTC) initiatives, provides a simple way to incorporate speech recognition and synthesis into web applications. The Speech Recognition API, a subset of this specification, allows developers to convert spoken words into text, enabling hands-free interactions. Architectural Overview The Web Speech API is composed of two main components: Speech Recognition: Converts spoken language into text. Speech Synthesis: Converts text into spoken language (Text-to-Speech). In this article, we will focus extensively on the Speech Recognition aspect, discussing its intricacies, capabilities, and limitations. Getting Started with the Speech Recognition API Basic Setup The Speech Recognition API utilizes the SpeechRecognition interface, available in modern browsers. Here's a basic implementation: // Check if SpeechRecognition is supported const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition; if (!SpeechRecognition) { console.error('Speech Recognition is not supported in this browser.'); } else { const recognition = new SpeechRecognition(); recognition.lang = 'en-US'; // Set your preferred language recognition.interimResults = true; // Get results while user is speaking recognition.maxAlternatives = 5; // Limit the number of alternatives for recognition recognition.onstart = () => { console.log('Voice recognition started. Speak into the microphone.'); }; recognition.onresult = (event) => { const transcript = event.results[0][0].transcript; console.log(`Recognized: ${transcript}`); }; recognition.onend = () => { console.log('Voice recognition ended.'); }; recognition.onerror = (event) => { console.error(`Error occurred in recognition: ${event.error}`); }; recognition.start(); // Start listening } In-Depth Features Continuous Recognition: By default, the API stops listening after a result is recognized. Setting recognition.continuous = true; allows it to listen continuously. Recording Language and Accents: Set recognition.lang = 'fr-FR'; to use different languages or dialects. Handling Interim Results: Utilizing interim results can enhance user experience by providing feedback as the user speaks. Voice Input Commands: Integration with command recognition can provide further controls. E.g., integrating if (transcript.includes('play music')) { playMusic(); }. Advanced Code Example Consider a scenario where you want to transcribe a conversation with commands to control UI elements. This necessitates advanced processing: const recognition = new SpeechRecognition(); recognition.continuous = true; recognition.interimResults = true; let finalTranscript = ''; recognition.onresult = (event) => { for (let i = event.resultIndex; i

Comprehensive Guide to Speech Recognition API for Voice Input in JavaScript
Historical and Technical Context
Evolution of Speech Recognition Technologies
The journey of speech recognition technology started as early as the 1950s, predominantly focusing on isolated word recognition. Early systems, such as IBM's "Shoebox," recognized a mere 16 words. The evolution accelerated with the advent of hidden Markov models (HMM) in the 1980s, which allowed for continuous speech recognition. The 1990s saw the introduction of statistically based systems, leveraging vast amounts of data to improve accuracy.
Fast forward to the 21st century, we witness the proliferation of deep learning techniques, particularly the use of recurrent neural networks (RNN) and convolutional neural networks (CNN), which have drastically improved recognition accuracy. All these advancements have led to the creation of platforms and APIs that allow developers to integrate voice recognition into applications seamlessly.
Introduction to the Web Speech API
The Web Speech API, emerging in the early 2010s as part of the W3C Web Real-Time Communications (WebRTC) initiatives, provides a simple way to incorporate speech recognition and synthesis into web applications. The Speech Recognition API, a subset of this specification, allows developers to convert spoken words into text, enabling hands-free interactions.
Architectural Overview
The Web Speech API is composed of two main components:
- Speech Recognition: Converts spoken language into text.
- Speech Synthesis: Converts text into spoken language (Text-to-Speech).
In this article, we will focus extensively on the Speech Recognition aspect, discussing its intricacies, capabilities, and limitations.
Getting Started with the Speech Recognition API
Basic Setup
The Speech Recognition API utilizes the SpeechRecognition interface, available in modern browsers. Here's a basic implementation:
// Check if SpeechRecognition is supported
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
if (!SpeechRecognition) {
console.error('Speech Recognition is not supported in this browser.');
} else {
const recognition = new SpeechRecognition();
recognition.lang = 'en-US'; // Set your preferred language
recognition.interimResults = true; // Get results while user is speaking
recognition.maxAlternatives = 5; // Limit the number of alternatives for recognition
recognition.onstart = () => {
console.log('Voice recognition started. Speak into the microphone.');
};
recognition.onresult = (event) => {
const transcript = event.results[0][0].transcript;
console.log(`Recognized: ${transcript}`);
};
recognition.onend = () => {
console.log('Voice recognition ended.');
};
recognition.onerror = (event) => {
console.error(`Error occurred in recognition: ${event.error}`);
};
recognition.start(); // Start listening
}
In-Depth Features
Continuous Recognition: By default, the API stops listening after a result is recognized. Setting
recognition.continuous = true;allows it to listen continuously.Recording Language and Accents: Set
recognition.lang = 'fr-FR';to use different languages or dialects.Handling Interim Results: Utilizing interim results can enhance user experience by providing feedback as the user speaks.
Voice Input Commands: Integration with command recognition can provide further controls. E.g., integrating
if (transcript.includes('play music')) { playMusic(); }.
Advanced Code Example
Consider a scenario where you want to transcribe a conversation with commands to control UI elements. This necessitates advanced processing:
const recognition = new SpeechRecognition();
recognition.continuous = true;
recognition.interimResults = true;
let finalTranscript = '';
recognition.onresult = (event) => {
for (let i = event.resultIndex; i < event.results.length; ++i) {
const result = event.results[i];
if (result.isFinal) {
finalTranscript += result[0].transcript + " ";
updateDisplay(finalTranscript); // Custom function to update the UI
} else {
interimDisplay(result[0].transcript); // Show interim results
}
}
};
recognition.start();
function updateDisplay(transcript) {
console.log(`Final Transcript: ${transcript}`);
if (transcript.includes('change background')) {
document.body.style.backgroundColor = 'lightblue';
}
}
function interimDisplay(transcript) {
console.log(`Interim Transcript: ${transcript}`);
}
Edge Cases and Advanced Implementation Techniques
Handling Different Accents and Dialects
Different accents could affect speech recognition. Ensure that your application handles various languages and accents gracefully. Employ fallback strategies, such as leveraging user-selected language preferences or providing users with audio prompts.
Managing Background Noise
In a real-world scenario, background noise can significantly hinder recognition capabilities. Use methods to:
- Advise users on a quiet environment.
- Implement noise reduction algorithms before sending the audio to the recognition service.
Long-Running Sessions
When implementing long-running recognition sessions, handle unexpected interruptions or session expirations. Consider implementing a mechanism to automatically re-initiate recognition if it stops unexpectedly due to network issues or user disconnection.
Support for Multiple Languages
In applications requiring multilingual support, create a mechanism to switch languages dynamically based on user selection. Store frequently used terms for each language to improve recognition efficiency.
Performance Considerations and Optimization Strategies
A. Latency and Real-Time Processing
Real-time applications demand low latency. Optimize this by:
- Minimizing audio processing overhead.
- Using WebAssembly for intensive computations when necessary.
B. Network Dependency
The API often relies on internet connectivity for accurate results. Implement a strategy to fallback to offline speech recognition libraries like PocketSphinx or CMU Sphinx for a seamless experience when network connectivity is poor.
C. Resource Management
When multiple instances of the SpeechRecognition API are created, it can lead to resource-heavy sessions causing performance downgrades:
- Dispose of instances when not required.
- Monitor performance in metrics for effective resource utilization.
Comparing with Alternative Approaches
Other Voice Technologies
Google Cloud Speech-to-Text: Offers robust cloud-based recognition with more accuracy but requires an API key, introduces latency, and has associated costs.
Nuance: Provides advanced capabilities, particularly for specialized domains like healthcare but is enterprise-focused and potentially costly.
IBM Watson Speech to Text: Known for its customization but again requires cloud access.
Conclusion on Comparisons
While the Web Speech API is easy to integrate and free to use, applications requiring higher accuracy or customization might benefit from cloud services at the expense of complexity and cost. Evaluate based on your application's requirements.
Real-World Use Cases
Applications of the Speech Recognition API span multiple industries. Here are some common use cases:
- Assistive Technologies: Enabling those with disabilities to interact with computers hands-free, improving accessibility.
- Voice-Activated User Interfaces: Used in applications and smart devices (e.g., Google Home, Amazon Alexa) to enhance user experience through commands.
- Automotive Industry: Implementing voice commands for navigation systems allows for safer driving experiences without manual distractions.
- Voice Transcription Services: Automatically convert dictations or meetings into text documents, streamlining documentation processes in business settings.
Potential Pitfalls and Advanced Debugging Techniques
Common Pitfalls
- Inconsistent Transcription Quality: Speech recognition can sometimes provide inaccurate results, especially in noisy environments. Always log outputs to ascertain transcription accuracy.
- Ignoring Errors: Always ensure error handling is robust, logging the reasons for failures (e.g., network issues or unavailable languages) for easier debugging.
Debugging Techniques
- Verbose Logging: Consistently provide feedback from various events (start, result, error) to monitor performance.
- Testing in Various Environments: Simulate different environments such as quiet and noisy backgrounds, along with varying user accents to test recognition capabilities.
- User Feedback Cycles: Implement user feedback mechanisms to gather input on transcription accuracy, allowing for iterative improvements.
Conclusion
The Speech Recognition API in JavaScript is a powerful tool that can enhance user experience through voice-driven interactions. Understanding its intricacies, challenges, and how to navigate them ensures you can build efficient applications leveraging this powerful technology.
By mastering the techniques discussed in this guide, from fundamental implementations to advanced optimizations, developers can create dynamic applications that meet modern user demands while harnessing the evolving landscape of voice recognition technology.
References
- MDN Web Docs: Web Speech API
- W3C: Web Speech API
- Google Cloud Speech-to-Text Documentation
- Nuance Communications
- IBM Watson Speech to Text Documentation
This comprehensive exploration of the Speech Recognition API should serve both novice and senior developers effectively, providing a detail-oriented, practical, and engaging approach to voice input technology in web applications.



