













































































































































































![[The AI Show Episode 151]: Anthropic CEO: AI Will Destroy 50% of Entry-Level Jobs, Veo 3’s Scary Lifelike Videos, Meta Aims to Fully Automate Ads & Perplexity’s Burning Cash](https://www.marketingaiinstitute.com/hubfs/ep%20151%20cover.png)






































































































































































































































































_Andrea_Danti_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)















































































































![Apple AI Launch in China Delayed Amid Approval Roadblocks and Trade Tensions [Report]](https://www.iclarified.com/images/news/97500/97500/97500-640.jpg)































































Discover how ForkJoinPool powers Java's high-performance parallel processing
Recently, I optimized our transport operation plan Excel upload feature, boosting performance for logistics system administrators. This tool allows them to upload weekly transportation schedules that our system processes and registers. The upload includes critical validation checks: verifying vehicle numbers, preventing duplicate plans, and identifying scheduling conflicts. By implementing parallel processing for these validations, processing time significantly reduced, enabling logistics managers to finalize transportation plans more efficiently. To achieve this, I leveraged parallelStream, a powerful feature introduced in Java 8. While the specific performance metrics and a deep dive into parallelStream with JMH will be covered in a future post, this article focuses on ForkJoinPool, engine that parallelStream uses internally to work its parallel processing. What is ForkJoinPool? At its core, ForkJoinPool is a specialized ThreadPoolExecutor designed to efficiently run a large number of tasks using a pool of worker threads. It's built around the divide-and-conquer principle. Large tasks are recursively broken down into smaller, more manageable subtasks (the "fork" step). These subtasks are then processed independently by different threads. Once these smaller tasks complete, their results are progressively combined (the "join" step) to produce the final result of the original large task. This approach is particularly well-suited for CPU-intensive operations where work can be easily parallelized. The Work-Stealing Algorithm: Keeping Threads Busy One of the standout features of ForkJoinPool is its work-stealing algorithm, which significantly boosts efficiency. Here's how it works: Each worker thread in the ForkJoinPool maintains its own deque (double-ended queue) of tasks assigned to it. A thread primarily processes tasks from the head of its own deque. However, if a thread finishes all its tasks and becomes idle, it doesn't just sit there. Instead, it looks at the deques of other busy threads and "steals" a task from the tail of their deque. This work-stealing mechanism ensures that threads remain busy as long as there's work to be done anywhere in the pool. It provides excellent load balancing, maximizes CPU utilization, and helps improve overall throughput, especially for tasks with unpredictable execution times. ParallelStream and CommonPool When you use parallelStream() in Java 8 and later, you're implicitly using a ForkJoinPool. Specifically, parallelStream operations are executed on the static ForkJoinPool.commonPool(). The commonPool() is a JVM-managed, globally available instance of ForkJoinPool. It's convenient because you don't need to manually create, configure, or shut down the pool; the JVM handles its lifecycle. This makes it very easy to introduce parallelism into your applications. By default, the number of threads in the commonPool() (its parallelism level) is typically set to the number of available processor cores - 1. (Runtime.getRuntime().availableProcessors() - 1). The "minus one" is to leave a core for the main application thread or other non-ForkJoinPool tasks. However, if the system has only a single processor, the commonPool()'s parallelism will be 1. CommonPool is a Shared Resource It's crucial to note that the commonPool() is a shared resource throughout your application. Not only parallelStream but also CompletableFuture's asynchronous methods (like supplyAsync() and runAsync(Runnable)) use the commonPool() by default if no specific Executor is provided. Because it's shared, you need to be careful about the types of tasks you submit to it. ForkJoinPool is optimized for CPU-bound tasks – computations that keep the CPU busy. If you use the commonPool() for long-running I/O-bound tasks (e.g., network requests, database queries, file operations) where threads might block and wait for extended periods, you risk starving the pool. If all threads in the commonPool() become blocked on I/O operations, other parts of your application relying on it (including other parallelStream operations or CompletableFutures) will be unable to get processing time, leading to severe performance degradation or even deadlocks. For I/O-bound tasks, it's generally better to use a separate, dedicated ExecutorService (like a cached thread pool or a fixed-size thread pool configured for the expected number of blocking tasks) to avoid monopolizing the commonPool(). Conclusion In essence, ForkJoinPool provides a powerful and efficient framework for parallel task execution, especially for computational workloads. Understanding its mechanics, particularly the work-stealing algorithm and its use in the commonPool(), can help you write more performant and scalable Java applications.

Recently, I optimized our transport operation plan Excel upload feature, boosting performance for logistics system administrators. This tool allows them to upload weekly transportation schedules that our system processes and registers. The upload includes critical validation checks: verifying vehicle numbers, preventing duplicate plans, and identifying scheduling conflicts. By implementing parallel processing for these validations, processing time significantly reduced, enabling logistics managers to finalize transportation plans more efficiently.
To achieve this, I leveraged parallelStream, a powerful feature introduced in Java 8. While the specific performance metrics and a deep dive into parallelStream with JMH will be covered in a future post, this article focuses on ForkJoinPool, engine that parallelStream uses internally to work its parallel processing.
What is ForkJoinPool?
At its core, ForkJoinPool is a specialized ThreadPoolExecutor designed to efficiently run a large number of tasks using a pool of worker threads. It's built around the divide-and-conquer principle. Large tasks are recursively broken down into smaller, more manageable subtasks (the "fork" step). These subtasks are then processed independently by different threads. Once these smaller tasks complete, their results are progressively combined (the "join" step) to produce the final result of the original large task.
This approach is particularly well-suited for CPU-intensive operations where work can be easily parallelized.
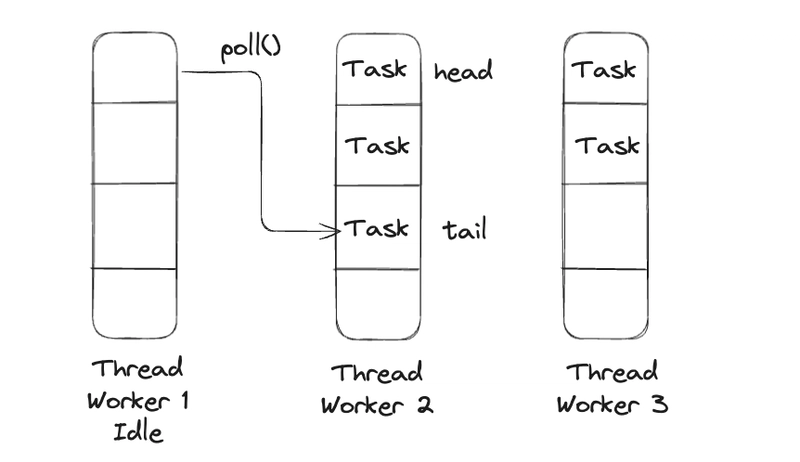
The Work-Stealing Algorithm: Keeping Threads Busy
One of the standout features of ForkJoinPool is its work-stealing algorithm, which significantly boosts efficiency. Here's how it works:
- Each worker thread in the ForkJoinPool maintains its own deque (double-ended queue) of tasks assigned to it.
- A thread primarily processes tasks from the head of its own deque.
- However, if a thread finishes all its tasks and becomes idle, it doesn't just sit there. Instead, it looks at the deques of other busy threads and "steals" a task from the tail of their deque.

This work-stealing mechanism ensures that threads remain busy as long as there's work to be done anywhere in the pool. It provides excellent load balancing, maximizes CPU utilization, and helps improve overall throughput, especially for tasks with unpredictable execution times.
ParallelStream and CommonPool
When you use parallelStream() in Java 8 and later, you're implicitly using a ForkJoinPool. Specifically, parallelStream operations are executed on the static ForkJoinPool.commonPool().
The commonPool() is a JVM-managed, globally available instance of ForkJoinPool. It's convenient because you don't need to manually create, configure, or shut down the pool; the JVM handles its lifecycle. This makes it very easy to introduce parallelism into your applications.
By default, the number of threads in the commonPool() (its parallelism level) is typically set to the number of available processor cores - 1.
(Runtime.getRuntime().availableProcessors() - 1).
The "minus one" is to leave a core for the main application thread or other non-ForkJoinPool tasks. However, if the system has only a single processor, the commonPool()'s parallelism will be 1.
CommonPool is a Shared Resource
It's crucial to note that the commonPool() is a shared resource throughout your application. Not only parallelStream but also CompletableFuture's asynchronous methods (like supplyAsync() and runAsync(Runnable)) use the commonPool() by default if no specific Executor is provided.
Because it's shared, you need to be careful about the types of tasks you submit to it. ForkJoinPool is optimized for CPU-bound tasks – computations that keep the CPU busy. If you use the commonPool() for long-running I/O-bound tasks (e.g., network requests, database queries, file operations) where threads might block and wait for extended periods, you risk starving the pool.
If all threads in the commonPool() become blocked on I/O operations, other parts of your application relying on it (including other parallelStream operations or CompletableFutures) will be unable to get processing time, leading to severe performance degradation or even deadlocks.
For I/O-bound tasks, it's generally better to use a separate, dedicated ExecutorService (like a cached thread pool or a fixed-size thread pool configured for the expected number of blocking tasks) to avoid monopolizing the commonPool().
Conclusion
In essence, ForkJoinPool provides a powerful and efficient framework for parallel task execution, especially for computational workloads. Understanding its mechanics, particularly the work-stealing algorithm and its use in the commonPool(), can help you write more performant and scalable Java applications.



