












































































































































































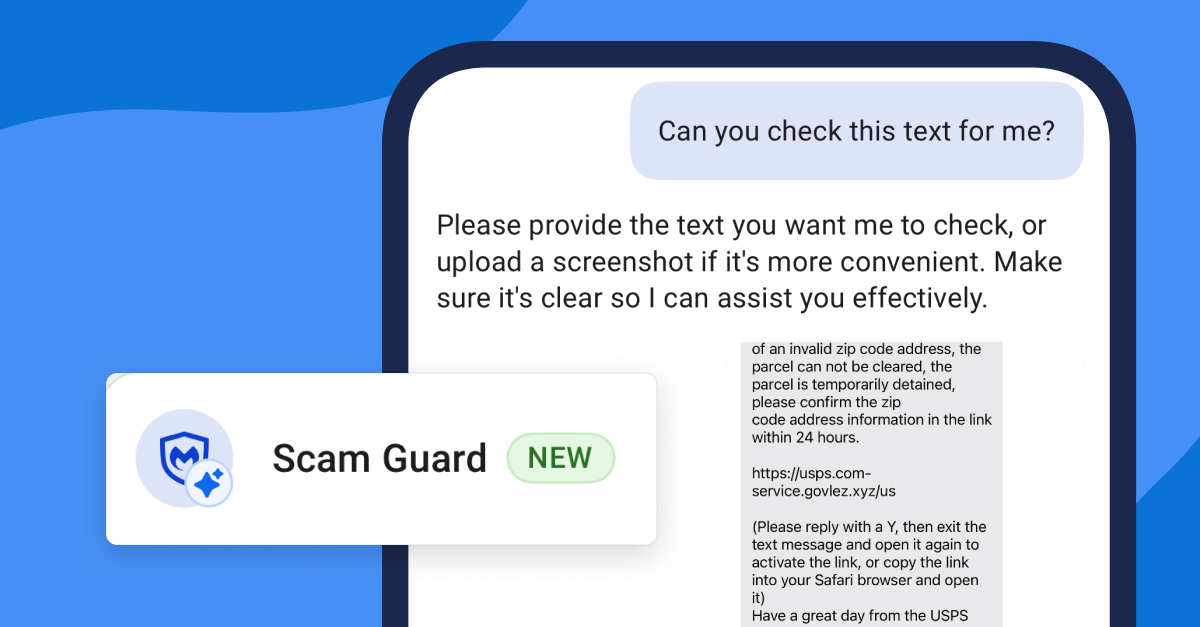
![[The AI Show Episode 151]: Anthropic CEO: AI Will Destroy 50% of Entry-Level Jobs, Veo 3’s Scary Lifelike Videos, Meta Aims to Fully Automate Ads & Perplexity’s Burning Cash](https://www.marketingaiinstitute.com/hubfs/ep%20151%20cover.png)




















































































































































![Z buffer problem in a 2.5D engine similar to monument valley [closed]](https://i.sstatic.net/OlHwug81.jpg)




























































































.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)




















_Kjetil_Kolbjornsrud_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)










































































































































































A Beginner’s Guide to Document Loaders in LangChain
When building with language models, we often obsess over prompts, model choices, and output formatting, but before any of that, there’s a quieter task that sets everything in motion: getting the right data in Large Language Models (LLMs) are powerful, but they need the right context to be truly useful. Whether you're building a smart chatbot, a document search tool, or an internal knowledge assistant, you’ll eventually need to bring in outside information. That could be anything from PDFs and web pages to spreadsheets or even internal company documents. This is where LangChain’s document loaders step in. Before we dive in, here’s something you’ll love: We are currently working on Langcasts.com, a resource crafted specifically for AI engineers, whether you're just getting started or already deep in the game. We'll be sharing guides, tips, hands-on walkthroughs, and extensive classes to help you master every piece of the puzzle. If you’d like to be notified the moment new materials drop, you can subscribe here to get updates directly. Document loaders act as a bridge between raw, unstructured data and the structured format that LangChain needs. They help you pull in content from different sources, like files, APIs, or online platforms, and turn it into something your LLM can process effectively. In this guide, we’ll explore what document loaders are, how they work, and how to use them in real-world projects. Let’s dive in. What Are Document Loaders? Document loaders are tools that help you bring external content into your LangChain application in a structured way. Their job is simple: take data from a source, like a PDF, website, or spreadsheet, and wrap it in a format LangChain can understand. Every piece of content a loader brings in is returned as a Document object. This object has two parts: page_content, which holds the text metadata, which includes useful details like where the data came from This structure keeps things clean and consistent, so that when you pass the document to an LLM or a vector store, everything works smoothly. There’s no need to manually parse or clean up your input data. Document loaders take care of the heavy lifting so you can focus on what your application is meant to do, like answer questions, summarize text, extract insights, or anything else your LLM is built for. Why Document Loaders Matter in AI Applications Document loaders may not steal the spotlight in AI applications, but they play a critical role behind the scenes. Here’s why they matter: Clean input leads to reliable output If your source data is a mess, the model's responses will be too. Loaders ensure your inputs are structured and clean. They bridge the gap between raw data and model-ready formats You might have a treasure trove of info in PDFs, cloud drives, or tools like Notion. Loaders bring that into your workflow. They reduce manual work Instead of writing a custom script every time you want to read a file, loaders give you a reusable, tested solution. Types of Document Loaders in LangChain Now that we’ve covered why document loaders matter, let’s look at what’s actually available in the LangChain toolkit. Loaders come in different shapes, each designed to handle a specific kind of source. Here’s a quick breakdown of the main types you’ll encounter: File-Based Loaders Useful when your data is stored locally. They support formats like PDF, DOCX, CSV, and plain text, making it easy to pull in documents from your machine. Web Loaders These are great when your source lives online. Just point to a URL, and LangChain handles the rest, pulling content from web pages, articles, or online resources. Cloud Storage Loaders For teams working in the cloud, these loaders fetch documents from services like Google Drive, S3, or Dropbox without the need for manual downloads. Third-Party Platform Loaders LangChain also connects with tools like Notion, Slack, and GitHub, so you can stream content straight from your team’s workspace or codebase. Custom Loaders If none of the built-ins fit your use case, you can define your own. LangChain makes it simple to build loaders tailored to niche or proprietary data sources. Each one is built to return structured Document objects, so once your content is in, it’s ready to move through your chain. Let’s see how to put one of these loaders to work, step by step. Using a Document Loader in Practice Let’s put document loaders to work with a real example using LangChain.js. Say you have a PDF you’d like to load into your app; maybe a research paper, product guide, or internal policy doc. Here’s how you can do that in JavaScript. Step 1: Install the necessary packages You'll need LangChain and a PDF parsing dependency: npm install langchain pdf-parse Step 2: Load the document LangChain.js provides a PDFLoader that works well with most PDF files. Here's how to use it:

When building with language models, we often obsess over prompts, model choices, and output formatting, but before any of that, there’s a quieter task that sets everything in motion: getting the right data in
Large Language Models (LLMs) are powerful, but they need the right context to be truly useful. Whether you're building a smart chatbot, a document search tool, or an internal knowledge assistant, you’ll eventually need to bring in outside information. That could be anything from PDFs and web pages to spreadsheets or even internal company documents. This is where LangChain’s document loaders step in.
Before we dive in, here’s something you’ll love:
We are currently working on Langcasts.com, a resource crafted specifically for AI engineers, whether you're just getting started or already deep in the game. We'll be sharing guides, tips, hands-on walkthroughs, and extensive classes to help you master every piece of the puzzle. If you’d like to be notified the moment new materials drop, you can subscribe here to get updates directly.
Document loaders act as a bridge between raw, unstructured data and the structured format that LangChain needs. They help you pull in content from different sources, like files, APIs, or online platforms, and turn it into something your LLM can process effectively.
In this guide, we’ll explore what document loaders are, how they work, and how to use them in real-world projects.
Let’s dive in.
What Are Document Loaders?
Document loaders are tools that help you bring external content into your LangChain application in a structured way. Their job is simple: take data from a source, like a PDF, website, or spreadsheet, and wrap it in a format LangChain can understand.
Every piece of content a loader brings in is returned as a Document object. This object has two parts:
-
page_content, which holds the text -
metadata, which includes useful details like where the data came from
This structure keeps things clean and consistent, so that when you pass the document to an LLM or a vector store, everything works smoothly.
There’s no need to manually parse or clean up your input data. Document loaders take care of the heavy lifting so you can focus on what your application is meant to do, like answer questions, summarize text, extract insights, or anything else your LLM is built for.
Why Document Loaders Matter in AI Applications
Document loaders may not steal the spotlight in AI applications, but they play a critical role behind the scenes. Here’s why they matter:
-
Clean input leads to reliable output
If your source data is a mess, the model's responses will be too. Loaders ensure your inputs are structured and clean.
-
They bridge the gap between raw data and model-ready formats
You might have a treasure trove of info in PDFs, cloud drives, or tools like Notion. Loaders bring that into your workflow.
-
They reduce manual work
Instead of writing a custom script every time you want to read a file, loaders give you a reusable, tested solution.
Types of Document Loaders in LangChain
Now that we’ve covered why document loaders matter, let’s look at what’s actually available in the LangChain toolkit.
Loaders come in different shapes, each designed to handle a specific kind of source. Here’s a quick breakdown of the main types you’ll encounter:
-
File-Based Loaders
Useful when your data is stored locally. They support formats like PDF, DOCX, CSV, and plain text, making it easy to pull in documents from your machine.
-
Web Loaders
These are great when your source lives online. Just point to a URL, and LangChain handles the rest, pulling content from web pages, articles, or online resources.
-
Cloud Storage Loaders
For teams working in the cloud, these loaders fetch documents from services like Google Drive, S3, or Dropbox without the need for manual downloads.
-
Third-Party Platform Loaders
LangChain also connects with tools like Notion, Slack, and GitHub, so you can stream content straight from your team’s workspace or codebase.
-
Custom Loaders
If none of the built-ins fit your use case, you can define your own. LangChain makes it simple to build loaders tailored to niche or proprietary data sources.
Each one is built to return structured Document objects, so once your content is in, it’s ready to move through your chain.
Let’s see how to put one of these loaders to work, step by step.
Using a Document Loader in Practice
Let’s put document loaders to work with a real example using LangChain.js. Say you have a PDF you’d like to load into your app; maybe a research paper, product guide, or internal policy doc.
Here’s how you can do that in JavaScript.
Step 1: Install the necessary packages
You'll need LangChain and a PDF parsing dependency:
npm install langchain pdf-parse
Step 2: Load the document
LangChain.js provides a PDFLoader that works well with most PDF files. Here's how to use it:
import { PDFLoader } from "langchain/document_loaders/fs/pdf";
const loader = new PDFLoader("example.pdf");
const documents = await loader.load();
// Let's look at the first document
console.log(documents[0].pageContent);
console.log(documents[0].metadata);
Each Document contains:
-
pageContent: the extracted text -
metadata: info like page number or file path
Step 3: Plug it into your chain
Now that your content is loaded and structured, you can:
- Send it to an embedding model
- Use it in a retrieval-augmented generation setup
- Preprocess it for chunking or summarization
This single step of getting your data in, makes the rest of your AI workflow possible.
Scaling Up: Working with Multiple or Large Files
Once you’ve mastered loading a single document, the next step is scaling, it could mean loading an entire folder or managing files too large to process in one go.
LangChain makes this surprisingly manageable.
Loading Multiple Files from a Directory
You can loop through a folder and apply a loader to each file. Here's a simple pattern using Node’s file system (fs)module:
import fs from "fs";
import path from "path";
import { PDFLoader } from "langchain/document_loaders/fs/pdf";
const folderPath = "./documents";
const loadDocuments = async () => {
const files = fs.readdirSync(folderPath);
const allDocs = [];
for (const file of files) {
const fullPath = path.join(folderPath, file);
const loader = new PDFLoader(fullPath);
const docs = await loader.load();
allDocs.push(...docs);
}
return allDocs;
};
const documents = await loadDocuments();
console.log(`Loaded ${documents.length} pages from folder.`);
This is perfect for batch-loading files for training, indexing, or search use cases.
Splitting Large Documents
LangChain doesn’t just load but it also helps you chunk large documents. Large documents can overwhelm models, so breaking them into smaller, meaningful pieces is key.
Here’s how to do it:
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const splitDocs = await splitter.splitDocuments(documents);
console.log(`Split into ${splitDocs.length} chunks`);
This prepares your data for embedding, search, or efficient retrieval, without cutting sentences off mid-thought.
Best Practices for Using Document Loaders
Working with document loaders gets easier with experience, but a few habits can help you avoid messy surprises and scale with confidence.
Here are some things to keep in mind:
-
Always validate your source content
Garbage in, garbage out. Check for missing files, corrupt formats, or content that can’t be parsed before loading.
-
Choose loaders based on your data source
Don’t force a PDF loader to read a
.docxor scrape a webpage manually. Use the right loader, it saves time and keeps your output consistent. -
Chunk before you embed
LLMs work best with focused context. Use text splitters to break long documents into smaller chunks before passing them to an embedding model or chain.
-
Keep metadata intact
Most loaders attach useful details like page number, file name, or URL. Hold onto that. It’s gold for tracing responses or building search interfaces later.
-
Batch intelligently
If you're processing hundreds of files, batch them in groups and watch for memory spikes. A simple loop with pauses or async handling can go a long way.
-
Build for change
Assume your data source will evolve. Whether that’s new formats or dynamic URLs, writing flexible loader logic from day one keeps you future-proof.
Document loaders may not be the flashiest part of working with LLMs, but they’re the quiet engine behind any meaningful interaction with real-world data. Once you understand how to use them well, you unlock the ability to bring your knowledge, files, and systems into your AI workflows, cleanly and confidently.
Whether you're loading a single PDF or syncing a thousand documents from the cloud, LangChain gives you the tools to do it right. Start small. Try loading a file today. Watch how it fits into your chain. From there, scale as your project grows.
The real power of AI isn’t just in generating text, it’s in helping you work with your own.



