












































































































































































![[The AI Show Episode 151]: Anthropic CEO: AI Will Destroy 50% of Entry-Level Jobs, Veo 3’s Scary Lifelike Videos, Meta Aims to Fully Automate Ads & Perplexity’s Burning Cash](https://www.marketingaiinstitute.com/hubfs/ep%20151%20cover.png)

















































































































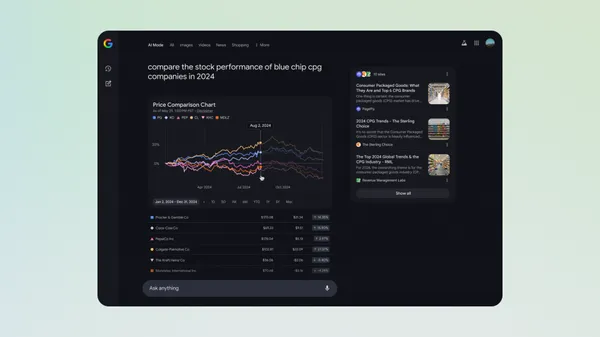






























































































































































































































































![Apple Shares Official Trailer for 'The Wild Ones' [Video]](https://www.iclarified.com/images/news/97515/97515/97515-640.jpg)


































































We Crashed the Network And It Was Glorious
At the recently concluded Africa Tech Summit, everything was buzzing the energy, the innovation and quite frustratingly the network outages. If you arrived early, the connection worked seamlessly and as always you don't notice until the unthinkable. By mid-morning, things went downhill fast. Why does this happen so often at tech events? and of-cause not just tech events. The answer, in many cases, is a form of accidental DoS (Denial of Service) not the malicious kind but a simple case of too many devices trying to connect to limited infrastructure. The Bottleneck: Overloaded “Busters” In my country, we call base stations "busters". These are the network nodes (usually wireless access points or cellular base stations) responsible for routing data to and from devices. Each base station has a limit to how many devices (or nodes) it can handle efficiently. Once that number is exceeded, it starts dropping connections, delaying packets and making your browser feel like it's loading over a 2G network. Why not just increase the capacity? Scaling Isn't That Simple Here’s where scaling comes in and why it's not just a plug-and-play solution: 1. Vertical Scaling (Scaling Up) Upgrading the base station with more powerful hardware, more memory, better antennas and higher bandwidth. But there’s a physical and regulatory limit to how much you can upgrade. Plus, vertical scaling still doesn't address distribution or redundancy. 2. Horizontal Scaling (Scaling Out) Adding more base stations to distribute the load sounds ideal. But here’s the catch: base stations need to coordinate handovers as people move around. Devices automatically shift from one to another based on signal strength a process called handover. When coverage areas overlap poorly or handover logic isn’t well-tuned, it leads to instability. Devices “ping-pong piki piki ponki” between stations or cling to weak connections. 3. Load Balancing Load balancing works great in data centers. At tech events? You’ve got a chaotic mix of smartphones, laptops, wearables, all running different OSes, aggressively scanning for connections. Real-time balancing at this scale is complex and expensive especially for a short-term event. Could It Be About Optimizing Software? Here’s another angle worth considering: Could better software design reduce the strain on infrastructure? What if apps were built to batch requests, defer syncs, or default to offline-first? One app polling every second seems harmless until a thousand people run it at once. It’s not just the network hardware sometimes, it’s how we write the code. What Actually Helped Us Thankfully, we were ready: most of our event resources were offline-first. No internet? No problem. Our demos, presentations and apps didn’t rely on live network calls. That saved us. What Could Be Done Better? Some practical solutions for tech events: Deploy mobile base stations Telecoms can bring in trucks equipped with temporary base stations to provide extra coverage. A good example being during the Safari Rally Kenya. Predict device density Use historical data or real-time tracking to estimate device load per area and allocate resources dynamically. Segment the network Create separate networks for attendees, staff, and demos to reduce congestion. Final Thoughts DoS at tech events isn't always about hackers, sometimes it’s just too many people trying to do too many things over too little infrastructure. Understanding the limits of scaling and the nature of wireless networking can help us prepare smarter. If you’re organizing or attending a tech event, remember: offline-first is your best friend and having a few extra “busters” wouldn’t hurt either... or so you think. Think not why the network failed, think how you can design to thrive when it does. Resilience isn’t just about having more resources, it’s about being ready when they’re gone.

At the recently concluded Africa Tech Summit, everything was buzzing the energy, the innovation and quite frustratingly the network outages. If you arrived early, the connection worked seamlessly and as always you don't notice until the unthinkable. By mid-morning, things went downhill fast. Why does this happen so often at tech events? and of-cause not just tech events.
The answer, in many cases, is a form of accidental DoS (Denial of Service) not the malicious kind but a simple case of too many devices trying to connect to limited infrastructure.
The Bottleneck: Overloaded “Busters”
In my country, we call base stations "busters". These are the network nodes (usually wireless access points or cellular base stations) responsible for routing data to and from devices.
Each base station has a limit to how many devices (or nodes) it can handle efficiently. Once that number is exceeded, it starts dropping connections, delaying packets and making your browser feel like it's loading over a 2G network.
Why not just increase the capacity?
Scaling Isn't That Simple
Here’s where scaling comes in and why it's not just a plug-and-play solution:
1. Vertical Scaling (Scaling Up)
Upgrading the base station with more powerful hardware, more memory, better antennas and higher bandwidth. But there’s a physical and regulatory limit to how much you can upgrade. Plus, vertical scaling still doesn't address distribution or redundancy.
2. Horizontal Scaling (Scaling Out)
Adding more base stations to distribute the load sounds ideal. But here’s the catch: base stations need to coordinate handovers as people move around. Devices automatically shift from one to another based on signal strength a process called handover.
When coverage areas overlap poorly or handover logic isn’t well-tuned, it leads to instability. Devices “ping-pong piki piki ponki” between stations or cling to weak connections.
3. Load Balancing
Load balancing works great in data centers. At tech events? You’ve got a chaotic mix of smartphones, laptops, wearables, all running different OSes, aggressively scanning for connections.
Real-time balancing at this scale is complex and expensive especially for a short-term event.
Could It Be About Optimizing Software?
Here’s another angle worth considering:
Could better software design reduce the strain on infrastructure?
What if apps were built to batch requests, defer syncs, or default to offline-first? One app polling every second seems harmless until a thousand people run it at once.
It’s not just the network hardware sometimes, it’s how we write the code.
What Actually Helped Us
Thankfully, we were ready: most of our event resources were offline-first.
No internet? No problem. Our demos, presentations and apps didn’t rely on live network calls. That saved us.
What Could Be Done Better?
Some practical solutions for tech events:
Deploy mobile base stations
Telecoms can bring in trucks equipped with temporary base stations to provide extra coverage. A good example being during the Safari Rally Kenya.Predict device density
Use historical data or real-time tracking to estimate device load per area and allocate resources dynamically.Segment the network
Create separate networks for attendees, staff, and demos to reduce congestion.
Final Thoughts
DoS at tech events isn't always about hackers, sometimes it’s just too many people trying to do too many things over too little infrastructure.
Understanding the limits of scaling and the nature of wireless networking can help us prepare smarter.
If you’re organizing or attending a tech event, remember:
offline-first is your best friend and having a few extra “busters” wouldn’t hurt either... or so you think.
Think not why the network failed, think how you can design to thrive when it does.
Resilience isn’t just about having more resources, it’s about being ready when they’re gone.



