![[The AI Show Episode 154]: AI Answers: The Future of AI Agents at Work, Building an AI Roadmap, Choosing the Right Tools, & Responsible AI Use](https://www.marketingaiinstitute.com/hubfs/ep%20154%20cover.png)
![How to Create Your Own AI Toolkit with Taylor Radey [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/MAICON-Speaker_Series-Taylor.png)
![[The AI Show Episode 153]: OpenAI Releases o3-Pro, Disney Sues Midjourney, Altman: “Gentle Singularity” Is Here, AI and Jobs & News Sites Getting Crushed by AI Search](https://www.marketingaiinstitute.com/hubfs/ep%20153%20cover.png)




























































































































![From Therapist to six figure freelance dev [Podcast #176]](https://cdn.hashnode.com/res/hashnode/image/upload/v1750249813414/8cb0019f-db6d-48af-9d20-d0ea3a4040b5.png?#)














































.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)
























![GrandChase tier list of the best characters available [June 2025]](https://media.pocketgamer.com/artwork/na-33057-1637756796/grandchase-ios-android-3rd-anniversary.jpg?#)

































































_Frank_Peters_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





























































































![Apple tells students ‘how to convince your parents to get you a Mac’ [Video]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/06/screenshot-2025-06-20-at-09.14.21.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)



![Nothing Headphone (1) leak allegedly shows their unique, translucent design [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/06/Nothing-Headphone-1-cropped.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)














![Oakley and Meta Launch Smart Glasses for Athletes With AI, 3K Camera, More [Video]](https://www.iclarified.com/images/news/97665/97665/97665-640.jpg)

![How to Get Your Parents to Buy You a Mac, According to Apple [Video]](https://www.iclarified.com/images/news/97671/97671/97671-640.jpg)
![Foxconn to Build New iPhone Enclosure Factory in India With $250M Investment [Report]](https://www.iclarified.com/images/news/97673/97673/97673-640.jpg)
















![New accessibility settings announced for Steam Big Picture Mode and SteamOS [Beta]](https://www.ghacks.net/wp-content/uploads/2025/06/New-accessibility-settings-announced-for-Steam-Big-Picture-Mode-and-SteamOS.jpg)









































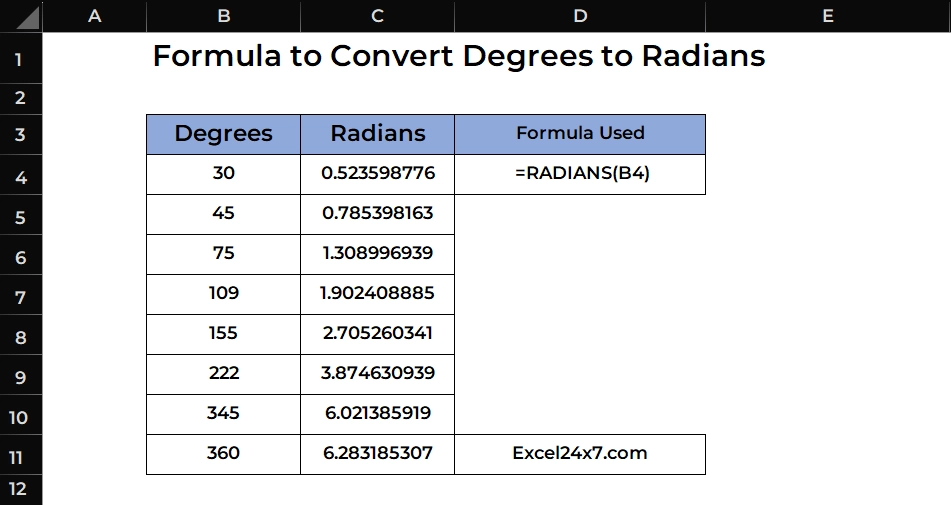
Scaling patterns in Kubernetes: VPA, HPA and KEDA
I've been working with a few pod scaling options in past but last year I started working with KEDA. So, I thought to write post to explain possible options in pod autoscaling. On the other side, manually adjusting parameters is not only slow but also inefficient. If you decide to allocate too little resource and you'll deliver subpar user experience or can experience application outages. If you over-provision resources "just in case" and you'll waste money and resources. That's where Kubernetes autoscaling comes to the rescue and deliver the right resources when required. Understanding Kubernetes Pod Autoscaling Fundamentals Autoscaling in Kubernetes means dynamically allocating cluster resources like CPU and memory to your applications based on real-time demand. This ensures applications have the right amount of resources to handle varying levels of load, directly improving application performance and availability. Key Benefits of Autoscaling: Cost Efficiency: Pay only for the resources you need instead of over-provisioning Environmental Impact: Reduced power consumption and carbon emissions through better resource alignment Time Savings: Automates manual resource adjustment tasks, freeing up valuable DevOps time Performance Optimization: Ensures applications maintain optimal performance under varying loads The Three Pillars of Kubernetes Autoscaling Kubernetes offers three primary autoscaling mechanisms, each serving different purposes: Vertical Pod Autoscaler (VPA) - Adjusts resource requests and limits within individual pods Horizontal Pod Autoscaler (HPA) - Scales the number of pod replicas up or down *Kubernetes Event-Driven Autoscaler *(KEDA) - Scales based on external events and custom metrics Let's explore each of them one by one. Vertical Pod Autoscaler (VPA): Right-sizing Your Pods What is VPA? The Vertical Pod Autoscaler automatically adjusts the CPU and memory requests and limits of individual containers within pods based on historical usage patterns. Instead of scaling the number of pods, VPA makes your existing pods "beefier" or "leaner" based on their actual resource needs. How VPA Works VPA operates through three core components: Recommender: Calculates optimal resource values based on historical metrics from the Kubernetes Metrics Server, analyzing up to 8 days of data to generate recommendations. Updater: Monitors recommendation changes and evicts pods when resource adjustments are needed, forcing replacement with updated allocations. Admission Webhook: Intercepts new pod deployments and injects updated resource values based on VPA recommendations. When to Use VPA VPA is ideal for: Stateful applications that can't be easily scaled horizontally Resource optimization scenarios where you need to fine-tune individual pod resources Applications with unpredictable resource patterns that traditional static allocation can't handle Cost optimization efforts to eliminate resource waste. VPA configuration example apiVersion: autoscaling.k8s.io/v1 kind: VerticalPodAutoscaler metadata: name: my-app-vpa spec: targetRef: apiVersion: "apps/v1" kind: "Deployment" name: "my-app" updatePolicy: updateMode: "Auto" resourcePolicy: containerPolicies: - containerName: '*' maxAllowed: cpu: 1 memory: 500Mi minAllowed: cpu: 100m memory: 50Mi Challenges with VPA Despite its benefits, VPA has several limitations: Incompatibility with HPA: Cannot run both tools together for CPU/memory-based scaling Limited historical data: Only stores 8 days of metrics, losing data on pod restarts Service disruption: Pod evictions cause momentary service interruptions No time-based controls: Pod evictions can happen at any time, including peak hours Cluster-wide configuration: Limited per-workload customization options Horizontal Pod Autoscaler (HPA): Scaling Out Your Application What is HPA? HPA automatically scales the number of pod replicas in a Deployment, ReplicaSet, or StatefulSet based on observed metrics like CPU utilization, memory usage, or custom metrics. It's the most fundamental and widely-used autoscaling pattern in Kubernetes. How HPA Overcomes VPA Challenges While VPA adjusts resources within pods, HPA takes a different approach: No service disruption: Scaling replicas doesn't require pod eviction Works with stateless applications: Perfect for horizontally scalable workloads Predictable scaling: Based on well-understood metrics like CPU and memory Mature and stable: Built-in Kubernetes feature with extensive community support When to Use HPA HPA is perfect for: Stateless applications where pods are interchangeable Predictable workloads with clear load patterns Web applications that experience traffic variations Microservices that can benefit from horizontal scaling apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: my-app-hpa spec: scaleTargetRef: apiVers

I've been working with a few pod scaling options in past but last year I started working with KEDA. So, I thought to write post to explain possible options in pod autoscaling. On the other side, manually adjusting parameters is not only slow but also inefficient. If you decide to allocate too little resource and you'll deliver subpar user experience or can experience application outages. If you over-provision resources "just in case" and you'll waste money and resources. That's where Kubernetes autoscaling comes to the rescue and deliver the right resources when required.
Understanding Kubernetes Pod Autoscaling Fundamentals
Autoscaling in Kubernetes means dynamically allocating cluster resources like CPU and memory to your applications based on real-time demand. This ensures applications have the right amount of resources to handle varying levels of load, directly improving application performance and availability.
Key Benefits of Autoscaling:
Cost Efficiency: Pay only for the resources you need instead of over-provisioning
Environmental Impact: Reduced power consumption and carbon emissions through better resource alignment
Time Savings: Automates manual resource adjustment tasks, freeing up valuable DevOps time
Performance Optimization: Ensures applications maintain optimal performance under varying loads
The Three Pillars of Kubernetes Autoscaling
Kubernetes offers three primary autoscaling mechanisms, each serving different purposes:
Vertical Pod Autoscaler (VPA) - Adjusts resource requests and limits within individual pods
Horizontal Pod Autoscaler (HPA) - Scales the number of pod replicas up or down
*Kubernetes Event-Driven Autoscaler *(KEDA) - Scales based on external events and custom metrics
Let's explore each of them one by one.
Vertical Pod Autoscaler (VPA): Right-sizing Your Pods
What is VPA?
The Vertical Pod Autoscaler automatically adjusts the CPU and memory requests and limits of individual containers within pods based on historical usage patterns. Instead of scaling the number of pods, VPA makes your existing pods "beefier" or "leaner" based on their actual resource needs.
How VPA Works
VPA operates through three core components:
Recommender: Calculates optimal resource values based on historical metrics from the Kubernetes Metrics Server, analyzing up to 8 days of data to generate recommendations.
Updater: Monitors recommendation changes and evicts pods when resource adjustments are needed, forcing replacement with updated allocations.
Admission Webhook: Intercepts new pod deployments and injects updated resource values based on VPA recommendations.
When to Use VPA
VPA is ideal for:
- Stateful applications that can't be easily scaled horizontally
- Resource optimization scenarios where you need to fine-tune individual pod resources
- Applications with unpredictable resource patterns that traditional static allocation can't handle
- Cost optimization efforts to eliminate resource waste.
VPA configuration example
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-app-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: "Deployment"
name: "my-app"
updatePolicy:
updateMode: "Auto"
resourcePolicy:
containerPolicies:
- containerName: '*'
maxAllowed:
cpu: 1
memory: 500Mi
minAllowed:
cpu: 100m
memory: 50Mi
Challenges with VPA
Despite its benefits, VPA has several limitations:
Incompatibility with HPA: Cannot run both tools together for CPU/memory-based scaling
Limited historical data: Only stores 8 days of metrics, losing data on pod restarts
Service disruption: Pod evictions cause momentary service interruptions
No time-based controls: Pod evictions can happen at any time, including peak hours
Cluster-wide configuration: Limited per-workload customization options
Horizontal Pod Autoscaler (HPA): Scaling Out Your Application
What is HPA?
HPA automatically scales the number of pod replicas in a Deployment, ReplicaSet, or StatefulSet based on observed metrics like CPU utilization, memory usage, or custom metrics. It's the most fundamental and widely-used autoscaling pattern in Kubernetes.
How HPA Overcomes VPA Challenges
While VPA adjusts resources within pods, HPA takes a different approach:
No service disruption: Scaling replicas doesn't require pod eviction
Works with stateless applications: Perfect for horizontally scalable workloads
Predictable scaling: Based on well-understood metrics like CPU and memory
Mature and stable: Built-in Kubernetes feature with extensive community support
When to Use HPA
HPA is perfect for:
- Stateless applications where pods are interchangeable
- Predictable workloads with clear load patterns
- Web applications that experience traffic variations
- Microservices that can benefit from horizontal scaling
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
HPA Limitations
While HPA is powerful, it has constraints:
- Limited to resource metrics: Basic HPA only works with CPU/memory metrics
- Not suitable for event-driven workloads: Can't scale based on queue lengths or custom events
- Reactive scaling: Only responds after metrics breach thresholds
- No scale-to-zero: Cannot scale down to zero replicas
KEDA: Event-Driven Autoscaling for Modern Applications
What is KEDA?
Kubernetes Event-Driven Autoscaling (KEDA) extends Kubernetes' native autoscaling capabilities to allow applications to scale based on events from various sources like message queues, databases, or custom metrics. KEDA graduated as a CNCF project, highlighting its importance in the cloud-native ecosystem.
How KEDA Overcomes HPA Limitations
KEDA addresses several HPA shortcomings:
- Event-driven scaling: Scales based on queue lengths, database records, HTTP requests, and more
- Scale-to-zero capability: Can scale applications down to zero when no events are present
- Rich ecosystem: Supports 50+ event sources including Kafka, RabbitMQ, Azure Service Bus, AWS SQS
- Custom metrics: Works with any metric source through external scalers

When to Use KEDA
KEDA excels in:
- Event-driven architectures with message queues and event buses
- Serverless-style workloads that benefit from scale-to-zero
- Batch processing jobs triggered by data availability
- IoT applications processing sensor data streams Machine learning pipelines processing inference requests
KEDA configuration example
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: rabbitmq-scaler
spec:
scaleTargetRef:
name: message-processor
triggers:
- type: rabbitmq
metadata:
protocol: amqp
queueName: work-queue
mode: QueueLength
value: "5"
KEDA vs HPA: Key Differences

Choosing the Right Autoscaling Strategy
Use VPA When:
- You have stateful applications that can't scale horizontally
- Resource optimization is your primary concern You need to fine-tune individual pod resources Applications have unpredictable resource usage patterns
Use HPA When:
- You have stateless, horizontally scalable applications
- Traditional web applications with predictable load patterns
- Simple microservices that scale based on CPU/memory
- You need a proven, stable autoscaling solution
Use KEDA When:
- Building event-driven or serverless-style applications
- Processing messages from queues or streams
- Need to scale based on custom or external metrics
- Cost optimization through scale-to-zero is important
Real-World Implementation Scenarios
Scenario 1: E-commerce Platform
- Frontend services: HPA for web servers based on CPU utilization
- Order processing: KEDA for scaling based on order queue length
- Database connections: VPA for optimizing connection pool resources
Scenario 2: IoT Data Pipeline
- Data ingestion: KEDA scaling based on message queue depth
- Stream processing: HPA for consistent throughput requirements
- Analytics services: VPA for memory-intensive data processing
Scenario 3: Machine Learning Platform
- Model serving: HPA for inference API endpoints
- Training jobs: KEDA triggered by training request queues
- Feature processing: VPA for compute-intensive transformations
Best Practices and Recommendations
- Start Simple: Begin with HPA for basic scaling needs, then add KEDA for event-driven requirements
- Monitor and Adjust: Continuously monitor scaling behavior and adjust thresholds
- Combine Strategies: Use different autoscalers for different components of your application
- Set Resource Limits: Always define appropriate resource limits to prevent runaway scaling
- Test Thoroughly: Validate autoscaling behavior under various load conditions
Conclusion
Kubernetes autoscaling is not a one-size-fits-all solution. The choice between VPA, HPA, and KEDA depends on your specific application requirements, architecture patterns, and operational needs. VPA optimizes resource utilization within pods, HPA provides reliable horizontal scaling for traditional workloads, and KEDA enables sophisticated event-driven scaling for modern cloud-native applications.
By understanding the strengths and limitations of each approach, you can design a comprehensive autoscaling strategy that optimizes both performance and cost while maintaining the reliability your applications demand.
If you are looking for a more deep dive course and hands on labs on Kubernetes Autoscaling and KEDA, you can checkout official LinuxFoundation course for no cost.