













































































































































































![[The AI Show Episode 154]: AI Answers: The Future of AI Agents at Work, Building an AI Roadmap, Choosing the Right Tools, & Responsible AI Use](https://www.marketingaiinstitute.com/hubfs/ep%20154%20cover.png)
![How to Create Your Own AI Toolkit with Taylor Radey [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/MAICON-Speaker_Series-Taylor.png)
![[The AI Show Episode 153]: OpenAI Releases o3-Pro, Disney Sues Midjourney, Altman: “Gentle Singularity” Is Here, AI and Jobs & News Sites Getting Crushed by AI Search](https://www.marketingaiinstitute.com/hubfs/ep%20153%20cover.png)
































































































































































































![GrandChase tier list of the best characters available [June 2025]](https://media.pocketgamer.com/artwork/na-33057-1637756796/grandchase-ios-android-3rd-anniversary.jpg?#)

































































_Frank_Peters_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)











































































































![Apple Weighs Acquisition of AI Startup Perplexity in Internal Talks [Report]](https://www.iclarified.com/images/news/97674/97674/97674-640.jpg)
![Oakley and Meta Launch Smart Glasses for Athletes With AI, 3K Camera, More [Video]](https://www.iclarified.com/images/news/97665/97665/97665-640.jpg)

![How to Get Your Parents to Buy You a Mac, According to Apple [Video]](https://www.iclarified.com/images/news/97671/97671/97671-640.jpg)



















![New accessibility settings announced for Steam Big Picture Mode and SteamOS [Beta]](https://www.ghacks.net/wp-content/uploads/2025/06/New-accessibility-settings-announced-for-Steam-Big-Picture-Mode-and-SteamOS.jpg)















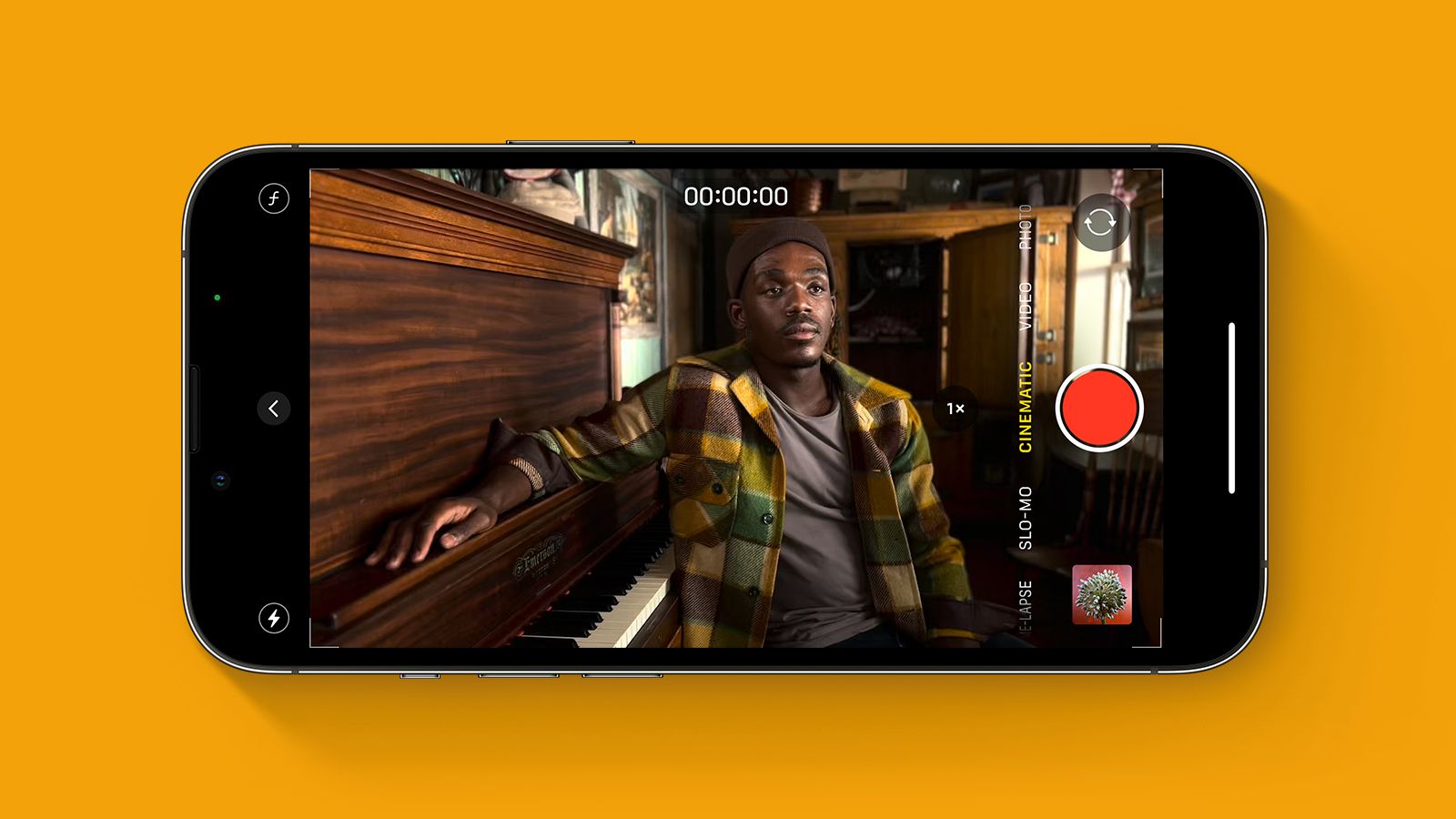
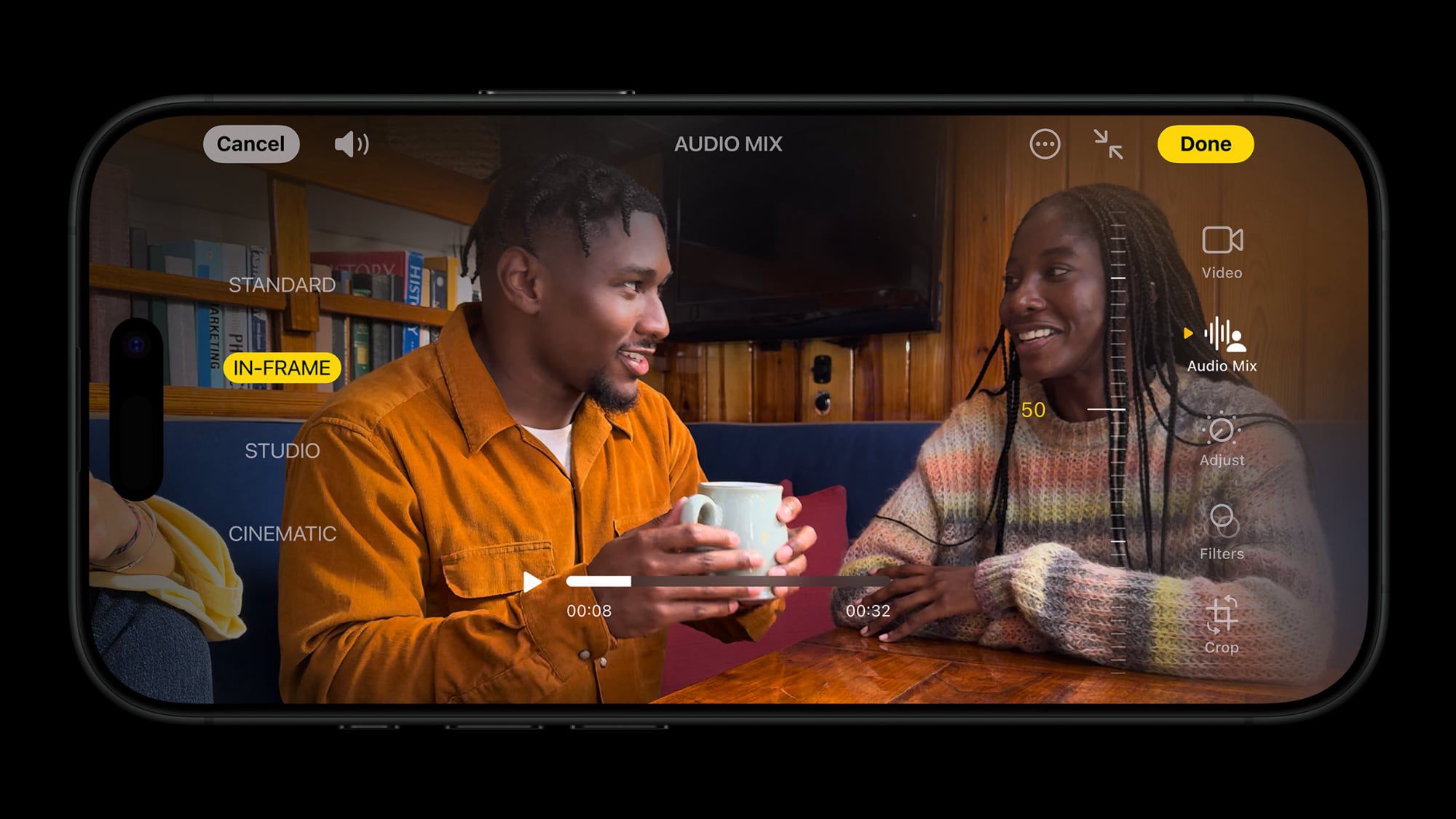





















Kafka Fundamentals: kafka log segment
Kafka Log Segments: A Deep Dive for Production Engineers 1. Introduction Imagine a financial trading platform where order events must be processed in strict sequence, even across multiple microservices. A single out-of-order message can lead to significant financial discrepancies. Or consider a global CDC (Change Data Capture) pipeline replicating database changes across continents, requiring high availability and minimal data loss. These scenarios, and countless others powering real-time data platforms, rely heavily on the correct functioning and optimization of Kafka’s core storage mechanism: the log segment. Kafka’s success stems from its ability to handle high-throughput, low-latency data streams. This is achieved through a distributed, partitioned, and replicated log. Understanding the internal workings of the log segment – how data is written, read, and managed – is crucial for building reliable, scalable, and performant Kafka-based systems. This post dives deep into Kafka log segments, covering architecture, configuration, failure modes, and operational best practices. 2. What is "kafka log segment" in Kafka Systems? A Kafka log segment is a contiguous, ordered sequence of messages within a Kafka partition. Each partition is logically divided into multiple log segments. These segments are immutable files of a fixed size (default 1GB, configurable via log.segment.bytes in server.properties). When a segment fills up, Kafka automatically rolls over to a new segment. Log segments are fundamental to Kafka’s architecture. Producers append messages to the end of the log. Consumers read messages sequentially from the log, tracking their position via offsets. Brokers store and serve these segments, replicating them across multiple brokers for fault tolerance. Introduced in KIP-27, the shift from ZooKeeper to Kafka Raft (KRaft) fundamentally changes how log segments are managed. KRaft eliminates the dependency on ZooKeeper for metadata management, directly embedding metadata within the Kafka brokers themselves. This simplifies the architecture and improves scalability. Prior to KRaft, ZooKeeper managed the active controller, which was responsible for segment management. Key configuration flags impacting log segments: log.segment.bytes: Segment size in bytes. log.retention.hours: Retention time for log segments. log.cleanup.policy: Cleanup policy (delete or compact). log.compression.type: Compression codec (gzip, snappy, lz4, zstd). 3. Real-World Use Cases Out-of-Order Message Handling: In financial applications, strict ordering is paramount. Log segments guarantee message order within a partition. Applications can leverage this by partitioning data based on a key that ensures related events land in the same partition. Multi-Datacenter Replication: MirrorMaker 2 (MM2) replicates topics across datacenters. Efficient log segment handling is critical for minimizing replication lag and ensuring data consistency. Optimizing segment size and compression can significantly impact replication throughput. Consumer Lag Monitoring & Backpressure: High consumer lag indicates consumers can’t keep up with the incoming data rate. Monitoring log segment growth and consumer offsets helps identify bottlenecks and implement backpressure mechanisms. Event Sourcing: Log segments serve as the immutable event store in event-sourced systems. Retention policies and compaction strategies are crucial for managing the size of the event log. CDC Replication: Capturing database changes and replicating them to data lakes or other systems requires a reliable and scalable message streaming platform. Log segments provide the foundation for this replication. 4. Architecture & Internal Mechanics graph LR A[Producer] --> B(Kafka Broker 1); A --> C(Kafka Broker 2); A --> D(Kafka Broker 3); B --> E{Partition Leader}; C --> E; D --> E; E --> F[Log Segment 1]; E --> G[Log Segment 2]; E --> H[Log Segment N]; I[Consumer] --> B; I --> C; I --> D; subgraph Kafka Cluster B C D end style E fill:#f9f,stroke:#333,stroke-width:2px The diagram illustrates a simplified Kafka topology. Producers send messages to brokers. Each partition is replicated across multiple brokers. One broker is designated as the partition leader. Messages are appended to log segments on the leader, which then replicate those segments to the followers. Consumers read from any broker, but the leader handles all writes. The controller (in ZooKeeper mode) or the KRaft quorum manages the lifecycle of log segments, including rollover and cleanup. Replication ensures data durability. The ISR (In-Sync Replicas) list determines which replicas are considered up-to-date. Messages are only considered committed once they are replicated to a sufficient number of ISRs (controlled by min.insync.replic

Kafka Log Segments: A Deep Dive for Production Engineers
1. Introduction
Imagine a financial trading platform where order events must be processed in strict sequence, even across multiple microservices. A single out-of-order message can lead to significant financial discrepancies. Or consider a global CDC (Change Data Capture) pipeline replicating database changes across continents, requiring high availability and minimal data loss. These scenarios, and countless others powering real-time data platforms, rely heavily on the correct functioning and optimization of Kafka’s core storage mechanism: the log segment.
Kafka’s success stems from its ability to handle high-throughput, low-latency data streams. This is achieved through a distributed, partitioned, and replicated log. Understanding the internal workings of the log segment – how data is written, read, and managed – is crucial for building reliable, scalable, and performant Kafka-based systems. This post dives deep into Kafka log segments, covering architecture, configuration, failure modes, and operational best practices.
2. What is "kafka log segment" in Kafka Systems?
A Kafka log segment is a contiguous, ordered sequence of messages within a Kafka partition. Each partition is logically divided into multiple log segments. These segments are immutable files of a fixed size (default 1GB, configurable via log.segment.bytes in server.properties). When a segment fills up, Kafka automatically rolls over to a new segment.
Log segments are fundamental to Kafka’s architecture. Producers append messages to the end of the log. Consumers read messages sequentially from the log, tracking their position via offsets. Brokers store and serve these segments, replicating them across multiple brokers for fault tolerance.
Introduced in KIP-27, the shift from ZooKeeper to Kafka Raft (KRaft) fundamentally changes how log segments are managed. KRaft eliminates the dependency on ZooKeeper for metadata management, directly embedding metadata within the Kafka brokers themselves. This simplifies the architecture and improves scalability. Prior to KRaft, ZooKeeper managed the active controller, which was responsible for segment management.
Key configuration flags impacting log segments:
-
log.segment.bytes: Segment size in bytes. -
log.retention.hours: Retention time for log segments. -
log.cleanup.policy: Cleanup policy (delete or compact). -
log.compression.type: Compression codec (gzip, snappy, lz4, zstd).
3. Real-World Use Cases
- Out-of-Order Message Handling: In financial applications, strict ordering is paramount. Log segments guarantee message order within a partition. Applications can leverage this by partitioning data based on a key that ensures related events land in the same partition.
- Multi-Datacenter Replication: MirrorMaker 2 (MM2) replicates topics across datacenters. Efficient log segment handling is critical for minimizing replication lag and ensuring data consistency. Optimizing segment size and compression can significantly impact replication throughput.
- Consumer Lag Monitoring & Backpressure: High consumer lag indicates consumers can’t keep up with the incoming data rate. Monitoring log segment growth and consumer offsets helps identify bottlenecks and implement backpressure mechanisms.
- Event Sourcing: Log segments serve as the immutable event store in event-sourced systems. Retention policies and compaction strategies are crucial for managing the size of the event log.
- CDC Replication: Capturing database changes and replicating them to data lakes or other systems requires a reliable and scalable message streaming platform. Log segments provide the foundation for this replication.
4. Architecture & Internal Mechanics
graph LR
A[Producer] --> B(Kafka Broker 1);
A --> C(Kafka Broker 2);
A --> D(Kafka Broker 3);
B --> E{Partition Leader};
C --> E;
D --> E;
E --> F[Log Segment 1];
E --> G[Log Segment 2];
E --> H[Log Segment N];
I[Consumer] --> B;
I --> C;
I --> D;
subgraph Kafka Cluster
B
C
D
end
style E fill:#f9f,stroke:#333,stroke-width:2px
The diagram illustrates a simplified Kafka topology. Producers send messages to brokers. Each partition is replicated across multiple brokers. One broker is designated as the partition leader. Messages are appended to log segments on the leader, which then replicate those segments to the followers. Consumers read from any broker, but the leader handles all writes.
The controller (in ZooKeeper mode) or the KRaft quorum manages the lifecycle of log segments, including rollover and cleanup. Replication ensures data durability. The ISR (In-Sync Replicas) list determines which replicas are considered up-to-date. Messages are only considered committed once they are replicated to a sufficient number of ISRs (controlled by min.insync.replicas). Schema Registry integrates by validating messages against defined schemas before they are written to the log segments.
5. Configuration & Deployment Details
server.properties (Broker Configuration):
log.segment.bytes=1073741824 # 1GB
log.retention.hours=168 # 7 days
log.cleanup.policy=delete # Delete old segments
log.compression.type=zstd # Use Zstandard compression
consumer.properties (Consumer Configuration):
fetch.min.bytes=16384 # Minimum bytes to fetch
fetch.max.wait.ms=500 # Max wait time for fetch
max.poll.records=500 # Max records to poll per iteration
CLI Examples:
- Create a topic:
kafka-topics.sh --create --topic my-topic --partitions 3 --replication-factor 3 --bootstrap-server localhost:9092 - Describe a topic:
kafka-topics.sh --describe --topic my-topic --bootstrap-server localhost:9092 - Configure a topic:
kafka-configs.sh --alter --entity-type topics --entity-name my-topic --add-config retention.ms=604800000 --bootstrap-server localhost:9092(set retention to 7 days)
6. Failure Modes & Recovery
- Broker Failure: If a broker fails, the controller (or KRaft quorum) elects a new leader for the affected partitions. Consumers can continue reading from the remaining replicas.
- Rebalance: Consumer rebalances can cause temporary disruptions in message processing. Minimizing rebalance frequency (e.g., using static membership) is crucial.
- Message Loss: If a message is not replicated to enough ISRs before a broker failure, it can be lost. Idempotent producers and transactional guarantees prevent duplicate messages but don’t recover lost messages.
- ISR Shrinkage: If the number of ISRs falls below
min.insync.replicas, writes are blocked until the ISR is restored. - Log Segment Corruption: Rare, but possible. Kafka detects corruption and attempts to recover from replicas.
Recovery Strategies:
- Idempotent Producers: Ensure exactly-once semantics by assigning a producer ID and sequence number to each message.
- Transactional Guarantees: Group messages into transactions for atomic writes.
- Offset Tracking: Consumers track their progress by committing offsets.
- Dead Letter Queues (DLQs): Route failed messages to a DLQ for investigation.
7. Performance Tuning
- Throughput: Achievable throughput varies based on hardware, network, and configuration. Typical throughput ranges from 100MB/s to several GB/s per broker.
-
linger.ms: Increase this value to batch messages, improving throughput at the cost of increased latency. -
batch.size: Larger batch sizes generally improve throughput but can increase memory usage. -
compression.type: Zstd offers a good balance between compression ratio and performance. -
fetch.min.bytes&replica.fetch.max.bytes: Adjust these values to optimize fetch requests.
Tail log pressure (the rate at which new data is written to the log) can impact latency. Monitoring disk I/O and optimizing segment size are crucial for mitigating tail log pressure.
8. Observability & Monitoring
Critical Metrics:
- Consumer Lag: The difference between the latest offset and the consumer’s current offset.
- Replication In-Sync Count: The number of replicas in the ISR.
- Request/Response Time: Latency of producer and consumer requests.
- Queue Length: Length of the request queue on brokers.
- Log Segment Size: Monitor segment growth to anticipate disk space issues.
Tools:
- Prometheus: Collect Kafka JMX metrics.
- Grafana: Visualize Kafka metrics.
- Kafka Manager/Kafka Tool: GUI tools for managing and monitoring Kafka clusters.
Alerting:
- Alert on high consumer lag.
- Alert on low ISR count.
- Alert on high request latency.
- Alert on disk space utilization.
9. Security and Access Control
- SASL/SSL: Encrypt communication between clients and brokers.
- SCRAM: Authentication mechanism for SASL.
- ACLs: Control access to topics and consumer groups.
- Kerberos: Authentication protocol for SASL.
- Audit Logging: Track access and modifications to Kafka resources.
10. Testing & CI/CD Integration
- Testcontainers: Spin up ephemeral Kafka instances for integration tests.
- Embedded Kafka: Run Kafka within the test process.
- Consumer Mock Frameworks: Simulate consumer behavior for testing producer logic.
- Schema Compatibility Tests: Ensure schema evolution doesn’t break existing consumers.
- Throughput Tests: Verify that the Kafka cluster can handle the expected load.
11. Common Pitfalls & Misconceptions
- Incorrect Partitioning: Leads to uneven data distribution and hot spots.
- Small Segment Size: Causes frequent rollovers and increased metadata overhead.
- Insufficient Replication Factor: Reduces fault tolerance.
- Ignoring Consumer Lag: Results in data loss or processing delays.
- Misconfigured Retention Policies: Leads to excessive disk usage or premature data deletion.
Example Logging (Broker): [2023-10-27 10:00:00,000] WARN [Controller id=1] Controller failed to elect new leader for partition my-topic-0 (Leader election failed due to no available replicas)
12. Enterprise Patterns & Best Practices
- Shared vs. Dedicated Topics: Consider the trade-offs between resource utilization and isolation.
- Multi-Tenant Cluster Design: Use resource quotas and ACLs to isolate tenants.
- Retention vs. Compaction: Choose the appropriate cleanup policy based on data usage patterns.
- Schema Evolution: Use a Schema Registry and backward-compatible schemas.
- Streaming Microservice Boundaries: Design microservices to consume and produce events from well-defined Kafka topics.
13. Conclusion
Kafka log segments are the bedrock of a reliable, scalable, and performant real-time data platform. A deep understanding of their architecture, configuration, and operational characteristics is essential for building and maintaining production-grade Kafka systems. Prioritizing observability, building internal tooling, and continuously refining topic structure will unlock the full potential of Kafka and enable your organization to harness the power of real-time data. Next steps should include implementing comprehensive monitoring and alerting, automating log segment management, and exploring advanced features like tiered storage.


