![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)



























































































































![From Accountant to Data Engineer with Alyson La [Podcast #168]](https://cdn.hashnode.com/res/hashnode/image/upload/v1744420903260/fae4b593-d653-41eb-b70b-031591aa2f35.png?#)







































































































.png?#)





































_John_Williams_RF_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



.webp?#)
.webp?#)























































































![One UI 8 leak shows off that Samsung’s Android 16 update will be small [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/12/Recents-app-menu-in-One-UI-7.0.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)














![Apple Takes Global Smartphone Lead in Q1 2025 with iPhone 16e Launch [Chart]](https://www.iclarified.com/images/news/97004/97004/97004-640.jpg)

![iPadOS 19 Will Be More Like macOS [Gurman]](https://www.iclarified.com/images/news/97001/97001/97001-640.jpg)























































































































Behind the Curtain: How Modern Text-to-Speech AI Works
I would like to apologize for being a bit disconnected from everyone on Dev.to for the last couple of weeks. Having recently started a new role as CTO of BCA Research, I have been heads down getting a handle on all the really interesting projects we have going on here. I have recently been looking at some Text to Speech services like 11 Labs (https://elevenlabs.io/) and Speechify (https://speechify.com/) to see how I could incorporate this into my blogging. I was really curious to see how these models worked under the hood and thought it would be useful to share some of my findings. The Two-Stage Architecture At first glance, converting text to speech might seem straightforward, but the process involves sophisticated AI systems that mimic the complex mechanisms of human speech production. Looking at the diagram below, you can see the intricate pipeline that transforms simple text input into natural-sounding audio. Modern TTS systems typically operate in two distinct stages: Text-to-Features: Converting text into audio representations (spectrograms) Features-to-Waveform: Transforming these representations into actual sound waves This separation allows each component to specialize in solving different aspects of the speech generation problem. The first part handles linguistic understanding and speech planning, while the second focuses on the acoustic properties that make speech sound natural. The components shown in the diagram work together seamlessly to produce increasingly human-like results that were impossible just a few years ago. Stage 1: From Text to Audio Features Before any audio is generated, the text undergoes preprocessing. This includes normalizing numbers and abbreviations (changing "123" to "one hundred twenty-three"), and converting graphemes (written letters) to phonemes (speech sounds). The core of the first stage is the acoustic model. As shown in the diagram, this process begins with the input text being converted into character embeddings - numerical representations that capture the meaning and context of each character. These embeddings flow through convolutional layers and a bidirectional LSTM network, which processes the text sequence and captures contextual relationships. A critical component is the attention mechanism (shown as "Location Sensitive Attention" in the diagram), which helps the model focus on relevant parts of the input text as it generates each part of the speech. This mechanism is particularly important for proper pronunciation, emphasis, and timing. After processing through the attention-equipped neural network, the output is projected to create a mel spectrogram - a visual representation of sound frequencies over time that captures the essential characteristics of speech. This spectrogram serves as an acoustic blueprint for the final audio. Stage 2: From Features to Waveforms The second stage uses a neural vocoder like WaveNet or WaveGlow to convert the mel spectrogram into actual audio waveforms. In our diagram, this is represented by the "WaveNet MoL" component. Traditional approaches used simple algorithms that often produced mechanical-sounding speech. Modern neural vocoders, however, can generate remarkably natural sounds that capture the nuances of human speech, including proper breathing patterns and subtle voice characteristics. The key innovation in newer vocoders like WaveGlow is their ability to generate audio in parallel rather than sequentially. This parallelization dramatically improves generation speed - from kilohertz rates to megahertz rates - making real-time speech synthesis possible even on consumer hardware. Recent Innovations What particularly fascinates me about platforms like 11 Labs is their breakthrough in voice cloning technology. With just minutes of sample audio, these systems can now create a digital version of virtually any voice. As I explore implementing these capabilities as part of my blogging, I'm seeing firsthand how this could transform content consumption for busy readers. The technology has advanced dramatically beyond the robotic voices many of us remember from just a few years ago. Today's AI-generated speech is increasingly indistinguishable from human voices, opening up new possibilities for content creation, accessibility, and user experience. I'll be continuing to experiment with these technologies and would love to hear if any of you have integrated speech synthesis into your own projects. The line between synthetic and human speech continues to blur, and I'm excited to be part of the journey in applying these innovations to create more engaging and accessible content. References: https://developer.nvidia.com/blog/generate-natural-sounding-speech-from-text-in-real-time/ https://arxiv.org/abs/1712.05884 https://arxiv.org/abs/1811.00002
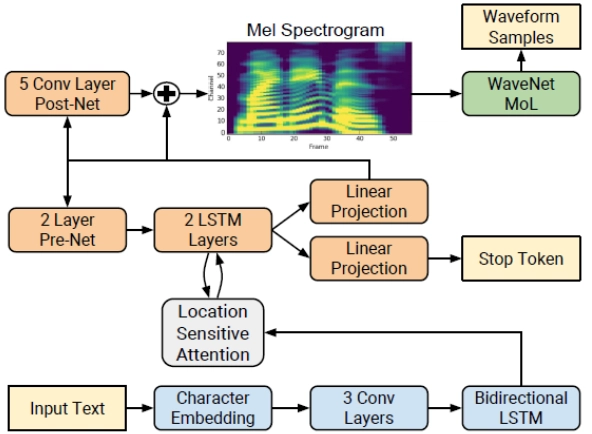
I would like to apologize for being a bit disconnected from everyone on Dev.to for the last couple of weeks. Having recently started a new role as CTO of BCA Research, I have been heads down getting a handle on all the really interesting projects we have going on here. I have recently been looking at some Text to Speech services like 11 Labs (https://elevenlabs.io/) and Speechify (https://speechify.com/) to see how I could incorporate this into my blogging. I was really curious to see how these models worked under the hood and thought it would be useful to share some of my findings.
The Two-Stage Architecture
At first glance, converting text to speech might seem straightforward, but the process involves sophisticated AI systems that mimic the complex mechanisms of human speech production. Looking at the diagram below, you can see the intricate pipeline that transforms simple text input into natural-sounding audio.
Modern TTS systems typically operate in two distinct stages:
- Text-to-Features: Converting text into audio representations (spectrograms)
- Features-to-Waveform: Transforming these representations into actual sound waves
This separation allows each component to specialize in solving different aspects of the speech generation problem. The first part handles linguistic understanding and speech planning, while the second focuses on the acoustic properties that make speech sound natural. The components shown in the diagram work together seamlessly to produce increasingly human-like results that were impossible just a few years ago.
Stage 1: From Text to Audio Features
Before any audio is generated, the text undergoes preprocessing. This includes normalizing numbers and abbreviations (changing "123" to "one hundred twenty-three"), and converting graphemes (written letters) to phonemes (speech sounds).
The core of the first stage is the acoustic model. As shown in the diagram, this process begins with the input text being converted into character embeddings - numerical representations that capture the meaning and context of each character. These embeddings flow through convolutional layers and a bidirectional LSTM network, which processes the text sequence and captures contextual relationships.
A critical component is the attention mechanism (shown as "Location Sensitive Attention" in the diagram), which helps the model focus on relevant parts of the input text as it generates each part of the speech. This mechanism is particularly important for proper pronunciation, emphasis, and timing.
After processing through the attention-equipped neural network, the output is projected to create a mel spectrogram - a visual representation of sound frequencies over time that captures the essential characteristics of speech. This spectrogram serves as an acoustic blueprint for the final audio.
Stage 2: From Features to Waveforms
The second stage uses a neural vocoder like WaveNet or WaveGlow to convert the mel spectrogram into actual audio waveforms. In our diagram, this is represented by the "WaveNet MoL" component.
Traditional approaches used simple algorithms that often produced mechanical-sounding speech. Modern neural vocoders, however, can generate remarkably natural sounds that capture the nuances of human speech, including proper breathing patterns and subtle voice characteristics.
The key innovation in newer vocoders like WaveGlow is their ability to generate audio in parallel rather than sequentially. This parallelization dramatically improves generation speed - from kilohertz rates to megahertz rates - making real-time speech synthesis possible even on consumer hardware.
Recent Innovations
What particularly fascinates me about platforms like 11 Labs is their breakthrough in voice cloning technology. With just minutes of sample audio, these systems can now create a digital version of virtually any voice. As I explore implementing these capabilities as part of my blogging, I'm seeing firsthand how this could transform content consumption for busy readers. The technology has advanced dramatically beyond the robotic voices many of us remember from just a few years ago. Today's AI-generated speech is increasingly indistinguishable from human voices, opening up new possibilities for content creation, accessibility, and user experience.
I'll be continuing to experiment with these technologies and would love to hear if any of you have integrated speech synthesis into your own projects. The line between synthetic and human speech continues to blur, and I'm excited to be part of the journey in applying these innovations to create more engaging and accessible content.