








































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)















































































































![Why modern UI is rarely written in C++? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)












![From Accountant to Data Engineer with Alyson La [Podcast #168]](https://cdn.hashnode.com/res/hashnode/image/upload/v1744420903260/fae4b593-d653-41eb-b70b-031591aa2f35.png?#)



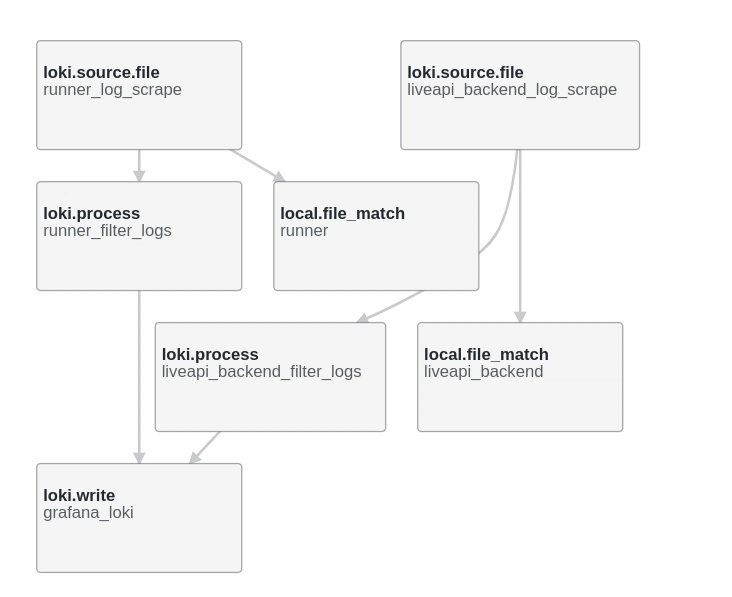

































































































.png?#)
















































































































































![Apple Posts Full First Episode of 'Your Friends & Neighbors' on YouTube [Video]](https://www.iclarified.com/images/news/96990/96990/96990-640.jpg)

![Apple May Implement Global iPhone Price Increases to Mitigate Tariff Impacts [Report]](https://www.iclarified.com/images/news/96987/96987/96987-640.jpg)





















































































































Are You Sure Your Posterior Makes Sense?
A detailed guide on how to use diagnostics to evaluate the performance of MCMC samplers The post Are You Sure Your Posterior Makes Sense? appeared first on Towards Data Science.

Introduction
Parameter estimation has been for decades one of the most important topics in statistics. While frequentist approaches, such as Maximum Likelihood Estimations, used to be the gold standard, the advance of computation has opened space for Bayesian methods. Estimating posterior distributions with Mcmc samplers became increasingly common, but reliable inferences depend on a task that is far from trivial: making sure that the sampler — and the processes it executes under the hood — worked as expected. Keeping in mind what Lewis Caroll once wrote: “If you don’t know where you’re going, any road will take you there.”
This article is meant to help data scientists evaluate an often overlooked aspect of Bayesian parameter estimation: the reliability of the sampling process. Throughout the sections, we combine simple analogies with technical rigor to ensure our explanations are accessible to data scientists with any level of familiarity with Bayesian methods. Although our implementations are in Python with PyMC, the concepts we cover are useful to anyone using an MCMC algorithm, from Metropolis-Hastings to NUTS.
Key Concepts
No data scientist or statistician would disagree with the importance of robust parameter estimation methods. Whether the objective is to make inferences or conduct simulations, having the capacity to model the data generation process is a crucial part of the process. For a long time, the estimations were mainly performed using frequentist tools, such as Maximum Likelihood Estimations (MLE) or even the famous Least Squares optimization used in regressions. Yet, frequentist methods have clear shortcomings, such as the fact that they are focused on point estimates and do not incorporate prior knowledge that could improve estimates.
As an alternative to these tools, Bayesian methods have gained popularity over the past decades. They provide statisticians not only with point estimates of the unknown parameter but also with confidence intervals for it, all of which are informed by the data and by the prior knowledge researchers held. Originally, Bayesian parameter estimation was done through an adapted version of Bayes’ theorem focused on unknown parameters (represented as θ) and known data points (represented as x). We can define P(θ|x), the posterior distribution of a parameter’s value given the data, as:
\[ P(\theta|x) = \frac{P(x|\theta) P(\theta)}{P(x)} \]
In this formula, P(x|θ) is the likelihood of the data given a parameter value, P(θ) is the prior distribution over the parameter, and P(x) is the evidence, which is computed by integrating all possible values of the prior:
\[ P(x) = \int_\theta P(x, \theta) d\theta \]
In some cases, due to the complexity of the calculations required, deriving the posterior distribution analytically was not possible. However, with the advance of computation, running sampling algorithms (especially MCMC ones) to estimate posterior distributions has become easier, giving researchers a powerful tool for situations where analytical posteriors are not trivial to find. Yet, with such power also comes a large amount of responsibility to ensure that results make sense. This is where sampler diagnostics come in, offering a set of valuable tools to gauge 1) whether an MCMC algorithm is working well and, consequently, 2) whether the estimated distribution we see is an accurate representation of the real posterior distribution. But how can we know so?
How samplers work
Before diving into the technicalities of diagnostics, we shall cover how the process of sampling a posterior (especially with an MCMC sampler) works. In simple terms, we can think of a posterior distribution as a geographical area we haven’t been to but need to know the topography of. How can we draw an accurate map of the region?
One of our favorite analogies comes from Ben Gilbert. Suppose that the unknown region is actually a house whose floorplan we wish to map. For some reason, we cannot directly visit the house, but we can send bees inside with GPS devices attached to them. If everything works as expected, the bees will fly around the house, and using their trajectories, we can estimate what the floor plan looks like. In this analogy, the floor plan is the posterior distribution, and the sampler is the group of bees flying around the house.
The reason we are writing this article is that, in some cases, the bees won’t fly as expected. If they get stuck in a certain room for some reason (because someone dropped sugar on the floor, for example), the data they return won’t be representative of the entire house; rather than visiting all rooms, the bees only visited a few, and our picture of what the house looks like will ultimately be incomplete. Similarly, when a sampler does not work correctly, our estimation of the posterior distribution is also incomplete, and any inference we draw based on it is likely to be wrong.
Monte Carlo Markov Chain (MCMC)
In technical terms, we call an MCMC process any algorithm that undergoes transitions from one state to another with certain properties. Markov Chain refers to the fact that the next state only depends on the current one (or that the bee’s next location is only influenced by its current place, and not by all of the places where it has been before). Monte Carlo means that the next state is chosen randomly. MCMC methods like Metropolis-Hastings, Gibbs sampling, Hamiltonian Monte Carlo (HMC), and No-U-Turn Sampler (NUTS) all operate by constructing Markov Chains (a sequence of steps) that are close to random and gradually explore the posterior distribution.
Now that you understand how a sampler works, let’s dive into a practical scenario to help us explore sampling problems.
Case Study
Imagine that, in a faraway nation, a governor wants to understand more about public annual spending on healthcare by mayors of cities with less than 1 million inhabitants. Rather than looking at sheer frequencies, he wants to understand the underlying distribution explaining expenditure, and a sample of spending data is about to arrive. The problem is that two of the economists involved in the project disagree about how the model should look.
Model 1
The first economist believes that all cities spend similarly, with some variation around a certain mean. As such, he creates a simple model. Although the specifics of how the economist chose his priors are irrelevant to us, we do need to keep in mind that he is trying to approximate a Normal (unimodal) distribution.
\[
x_i \sim \text{Normal}(\mu, \sigma^2) \text{ i.i.d. for all } i \\
\mu \sim \text{Normal}(10, 2) \\
\sigma^2 \sim \text{Uniform}(0,5)
\]
Model 2
The second economist disagrees, arguing that spending is more complex than his colleague believes. He believes that, given ideological differences and budget constraints, there are two kinds of cities: the ones that do their best to spend very little and the ones that are not afraid of spending a lot. As such, he creates a slightly more complex model, using a mixture of normals to reflect his belief that the true distribution is bimodal.
\[
x_i \sim \text{Normal-Mixture}([\omega, 1-\omega], [m_1, m_2], [s_1^2, s_2^2]) \text{ i.i.d. for all } i\\
m_j \sim \text{Normal}(2.3, 0.5^2) \text{ for } j = 1,2 \\
s_j^2 \sim \text{Inverse-Gamma}(1,1) \text{ for } j=1,2 \\
\omega \sim \text{Beta}(1,1)
\]
After the data arrives, each economist runs an MCMC algorithm to estimate their desired posteriors, which will be a reflection of reality (1) if their assumptions are true and (2) if the sampler worked correctly. The first if, a discussion about assumptions, shall be left to the economists. However, how can they know whether the second if holds? In other words, how can they be sure that the sampler worked correctly and, as a consequence, their posterior estimations are unbiased?
Sampler Diagnostics
To evaluate a sampler’s performance, we can explore a small set of metrics that reflect different parts of the estimation process.
Quantitative Metrics
R-hat (Potential Scale Reduction Factor)
In simple terms, R-hat evaluates whether bees that started at different places have all explored the same rooms at the end of the day. To estimate the posterior, an MCMC algorithm uses multiple chains (or bees) that start at random locations. R-hat is the metric we use to assess the convergence of the chains. It measures whether multiple MCMC chains have mixed well (i.e., if they have sampled the same topography) by comparing the variance of samples within each chain to the variance of the sample means across chains. Intuitively, this means that
\[
\hat{R} = \sqrt{\frac{\text{Variance Between Chains}}{\text{Variance Within Chains}}}
\]
If R-hat is close to 1.0 (or below 1.01), it means that the variance within each chain is very similar to the variance between chains, suggesting that they have converged to the same distribution. In other words, the chains are behaving similarly and are also indistinguishable from one another. This is precisely what we see after sampling the posterior of the first model, shown in the last column of the table below:

The r-hat from the second model, however, tells a different story. The fact we have such large r-hat values indicates that, at the end of the sampling process, the different chains had not converged yet. In practice, this means that the distribution they explored and returned was different, or that each bee created a map of a different room of the house. This fundamentally leaves us without a clue of how the pieces connect or what the complete floor plan looks like.

Given our R-hat readouts were large, we know something went wrong with the sampling process in the second model. However, even if the R-hat had turned out within acceptable levels, this does not give us certainty that the sampling process worked. R-hat is just a diagnostic tool, not a guarantee. Sometimes, even if your R-hat readout is lower than 1.01, the sampler might not have properly explored the full posterior. This happens when multiple bees start their exploration in the same room and remain there. Likewise, if you’re using a small number of chains, and if your posterior happens to be multimodal, there is a probability that all chains started in the same mode and failed to explore other peaks.
The R-hat readout reflects convergence, not completion. In order to have a more comprehensive idea, we need to check other diagnostic metrics as well.
Effective Sample Size (ESS)
When explaining what MCMC was, we mentioned that “Monte Carlo” refers to the fact that the next state is chosen randomly. This does not necessarily mean that the states are fully independent. Even though the bees choose their next step at random, these steps are still correlated to some extent. If a bee is exploring a living room at time t=0, it will probably still be in the living room at time t=1, even though it is in a different part of the same room. Due to this natural connection between samples, we say these two data points are autocorrelated.
Due to their nature, MCMC methods inherently produce autocorrelated samples, which complicates statistical analysis and requires careful evaluation. In statistical inference, we often assume independent samples to ensure that the estimates of uncertainty are accurate, hence the need for uncorrelated samples. If two data points are too similar to each other, the correlation reduces their effective information content. Mathematically, the formula below represents the autocorrelation function between two time points (t1 and t2) in a random process:
\[
R_{XX}(t_1, t_2) = E[X_{t_1} \overline{X_{t_2}}]
\]
where E is the expected value operator and X-bar is the complex conjugate. In MCMC sampling, this is crucial because high autocorrelation means that new samples don’t teach us anything different from the old ones, effectively reducing the sample size we have. Unsurprisingly, the metric that reflects this is called Effective Sample Size (ESS), and it helps us determine how many truly independent samples we have.
As hinted previously, the effective sample size accounts for autocorrelation by estimating how many truly independent samples would provide the same information as the autocorrelated samples we have. Mathematically, for a parameter θ, the ESS is defined as:
\[
ESS = \frac{n}{1 + 2 \sum_{k=1}^{\infty} \rho(\theta)_k}
\]
where n is the total number of samples and ρ(θ)k is the autocorrelation at lag k for parameter θ.
Typically, for ESS readouts, the higher, the better. This is what we see in the readout for the first model. Two common ESS variations are Bulk-ESS, which assesses mixing in the central part of the distribution, and Tail-ESS, which focuses on the efficiency of sampling the distribution’s tails. Both inform us if our model accurately reflects the central tendency and credible intervals.

In contrast, the readouts for the second model are very bad. Typically, we want to see readouts that are at least 1/10 of the total sample size. In this case, given each chain sampled 2000 observations, we should expect ESS readouts of at least 800 (from the total size of 8000 samples across 4 chains of 2000 samples each), which is not what we observe.

Visual Diagnostics
Apart from the numerical metrics, our understanding of sampler performance can be deepened through the use of diagnostic plots. The main ones are rank plots, trace plots, and pair plots.
Rank Plots
A rank plot helps us identify whether the different chains have explored all of the posterior distribution. If we once again think of the bee analogy, rank plots tell us which bees explored which parts of the house. Therefore, to evaluate whether the posterior was explored equally by all chains, we observe the shape of the rank plots produced by the sampler. Ideally, we want the distribution of all chains to look roughly uniform, like in the rank plots generated after sampling the first model. Each color below represents a chain (or bee):
![]()
Under the hood, a rank plot is produced with a simple sequence of steps. First, we run the sampler and let it sample from the posterior of each parameter. In our case, we are sampling posteriors for parameters m and s of the first model. Then, parameter by parameter, we get all samples from all chains, put them together, and order them from smallest to largest. We then ask ourselves, for each sample, what was the chain where it came from? This will allow us to create plots like the ones we see above.
In contrast, bad rank plots are easy to spot. Unlike the previous example, the distributions from the second model, shown below, are not uniform. From the plots, what we interpret is that each chain, after beginning at different random locations, got stuck in a region and did not explore the entirety of the posterior. Consequently, we cannot make inferences from the results, as they are unreliable and not representative of the true posterior distribution. This would be equivalent to having four bees that started at different rooms of the house and got stuck somewhere during their exploration, never covering the entirety of the property.
![]()
KDE and Trace Plots
Similar to R-hat, trace plots help us assess the convergence of MCMC samples by visualizing how the algorithm explores the parameter space over time. PyMC provides two types of trace plots to diagnose mixing issues: Kernel Density Estimate (KDE) plots and iteration-based trace plots. Each of these serves a distinct purpose in evaluating whether the sampler has properly explored the target distribution.
The KDE plot (usually on the left) estimates the posterior density for each chain, where each line represents a separate chain. This allows us to check whether all chains have converged to the same distribution. If the KDEs overlap, it suggests that the chains are sampling from the same posterior and that mixing has occurred. On the other hand, the trace plot (usually on the right) visualizes how parameter values change over MCMC iterations (steps), with each line representing a different chain. A well-mixed sampler will produce trace plots that look noisy and random, with no clear structure or separation between chains.
Using the bee analogy, trace plots can be thought of as snapshots of the “features” of the house at different locations. If the sampler is working correctly, the KDEs in the left plot should align closely, showing that all bees (chains) have explored the house similarly. Meanwhile, the right plot should show highly variable traces that blend together, confirming that the chains are actively moving through the space rather than getting stuck in specific regions.

However, if your sampler has poor mixing or convergence issues, you will see something like the figure below. In this case, the KDEs will not overlap, meaning that different chains have sampled from different distributions rather than a shared posterior. The trace plot will also show structured patterns instead of random noise, indicating that chains are stuck in different regions of the parameter space and failing to fully explore it.

By using trace plots alongside the other diagnostics, you can identify sampling issues and determine whether your MCMC algorithm is effectively exploring the posterior distribution.
Pair Plots
A third kind of plot that is often useful for diagnostic are pair plots. In models where we want to estimate the posterior distribution of multiple parameters, pair plots allow us to observe how different parameters are correlated. To understand how such plots are formed, think again about the bee analogy. If you imagine that we’ll create a plot with the width and length of the house, each “step” that the bees take can be represented by an (x, y) combination. Likewise, each parameter of the posterior is represented as a dimension, and we create scatter plots showing where the sampler walked using parameter values as coordinates. Here, we are plotting each unique pair (x, y), resulting in the scatter plot you see in the middle of the image below. The one-dimensional plots you see on the edges are the marginal distributions over each parameter, giving us additional information on the sampler’s behavior when exploring them.
Take a look at the pair plot from the first model.

Each axis represents one of the two parameters whose posteriors we are estimating. For now, let’s focus on the scatter plot in the middle, which shows the parameter combinations sampled from the posterior. The fact we have a very even distribution means that, for any particular value of m, there was a range of values of s that were equally likely to be sampled. Additionally, we don’t see any correlation between the two parameters, which is usually good! There are cases when we would expect some correlation, such as when our model involves a regression line. However, in this instance, we have no reason to believe two parameters should be highly correlated, so the fact we don’t observe unusual behavior is positive news.
Now, take a look at the pair plots from the second model.

Given that this model has five parameters to be estimated, we naturally have a greater number of plots since we are analyzing them pair-wise. However, they look odd compared to the previous example. Namely, rather than having an even distribution of points, the samples here either seem to be divided across two regions or seem somewhat correlated. This is another way of visualizing what the rank plots have shown: the sampler did not explore the full posterior distribution. Below we isolated the top left plot, which contains the samples from m0 and m1. Unlike the plot from model 1, here we see that the value of one parameter greatly influences the value of the other. If we sampled m1 around 2.5, for example, m0 is likely to be sampled from a very narrow range around 1.5.

Certain shapes can be observed in problematic pair plots relatively frequently. Diagonal patterns, for example, indicate a high correlation between parameters. Banana shapes are often connected to parametrization issues, often being present in models with tight priors or constrained parameters. Funnel shapes might indicate hierarchical models with bad geometry. When we have two separate islands, like in the plot above, this can indicate that the posterior is bimodal AND that the chains haven’t mixed well. However, keep in mind that these shapes might indicate problems, but not necessarily do so. It’s up to the data scientist to examine the model and determine which behaviors are expected and which ones are not!
Some Fixing Techniques
When your diagnostics indicate sampling problems — whether concerning R-hat values, low ESS, unusual rank plots, separated trace plots, or strange parameter correlations in pair plots — several strategies can help you address the underlying issues. Sampling problems typically stem from the target posterior being too complex for the sampler to explore efficiently. Complex target distributions might have:
- Multiple modes (peaks) that the sampler struggles to move between
- Irregular shapes with narrow “corridors” connecting different regions
- Areas of drastically different scales (like the “neck” of a funnel)
- Heavy tails that are difficult to sample accurately
In the bee analogy, these complexities represent houses with unusual floor plans — disconnected rooms, extremely narrow hallways, or areas that change dramatically in size. Just as bees might get trapped in specific regions of such houses, MCMC chains can get stuck in certain areas of the posterior.


To help the sampler in its exploration, there are simple strategies we can use.
Strategy 1: Reparameterization
Reparameterization is particularly effective for hierarchical models and distributions with challenging geometries. It involves transforming your model’s parameters to make them easier to sample. Back to the bee analogy, imagine the bees are exploring a house with a peculiar layout: a spacious living room that connects to the kitchen through a very, very narrow hallway. One aspect we hadn’t mentioned before is that the bees have to fly in the same way through the entire house. That means that if we dictate the bees should use large “steps,” they will explore the living room very well but hit the walls in the hallway head-on. Likewise, if their steps are small, they will explore the narrow hallway well, but take forever to cover the entire living room. The difference in scales, which is natural to the house, makes the bees’ job more difficult.
A classic example that represents this scenario is Neal’s funnel, where the scale of one parameter depends on another:
\[
p(y, x) = \text{Normal}(y|0, 3) \times \prod_{n=1}^{9} \text{Normal}(x_n|0, e^{y/2})
\]

We can see that the scale of x is dependent on the value of y. To fix this problem, we can separate x and y as independent standard Normals and then transform these variables into the desired funnel distribution. Instead of sampling directly like this:
\[
\begin{align*}
y &\sim \text{Normal}(0, 3) \\
x &\sim \text{Normal}(0, e^{y/2})
\end{align*}
\]
You can reparameterize to sample from standard Normals first:
\[
y_{raw} \sim \text{Standard Normal}(0, 1) \\
x_{raw} \sim \text{Standard Normal}(0, 1) \\
\\
y = 3y_{raw} \\
x = e^{y/2} x_{raw}
\]
This technique separates the hierarchical parameters and makes sampling more efficient by eliminating the dependency between them.
Reparameterization is like redesigning the house such that instead of forcing the bees to find a single narrow hallway, we create a new layout where all passages have similar widths. This helps the bees use a consistent flying pattern throughout their exploration.
Strategy 2: Handling Heavy-tailed Distributions
Heavy-tailed distributions like Cauchy and Student-T present challenges for samplers and the ideal step size. Their tails require larger step sizes than their central regions (similar to very long hallways that require the bees to travel long distances), which creates a challenge:
- Small step sizes lead to inefficient sampling in the tails
- Large step sizes cause too many rejections in the center

Reparameterization solutions include:
- For Cauchy: Defining the variable as a transformation of a Uniform distribution using the Cauchy inverse CDF
- For Student-T: Using a Gamma-Mixture representation
Strategy 3: Hyperparameter Tuning
Sometimes the solution lies in adjusting the sampler’s hyperparameters:
- Increase total iterations: The simplest approach — give the sampler more time to explore.
- Increase target acceptance rate (adapt_delta): Reduce divergent transitions (try 0.9 instead of the default 0.8 for complex models, for example).
- Increase max_treedepth: Allow the sampler to take more steps per iteration.
- Extend warmup/adaptation phase: Give the sampler more time to adapt to the posterior geometry.
Remember that while these adjustments may improve your diagnostic metrics, they often treat symptoms rather than underlying causes. The previous strategies (reparameterization and better proposal distributions) typically offer more fundamental solutions.
Strategy 4: Better Proposal Distributions
This solution is for function fitting processes, rather than sampling estimations of the posterior. It basically asks the question: “I’m currently here in this landscape. Where should I jump to next so that I explore the full landscape, or how do I know that the next jump is the jump I should make?” Thus, choosing a good distribution means making sure that the sampling process explores the full parameter space instead of just a specific region. A good proposal distribution should:
- Have substantial probability mass where the target distribution does.
- Allow the sampler to make jumps of the appropriate size.
One common choice of the proposal distribution is the Gaussian (Normal) distribution with mean μ and standard deviation σ — the scale of the distribution that we can tune to decide how far to jump from the current position to the next position. If we choose the scale for the proposal distribution to be too small, it might either take too long to explore the entire posterior or it will get stuck in a region and never explore the full distribution. But if the scale is too large, you might never get to explore some regions, jumping over them. It’s like playing ping-pong where we only reach the two edges but not the middle.
Improve Prior Specification
When all else fails, reconsider your model’s prior specifications. Vague or weakly informative priors (like uniformly distributed priors) can sometimes lead to sampling difficulties. More informative priors, when justified by domain knowledge, can help guide the sampler toward more reasonable regions of the parameter space. Sometimes, despite your best efforts, a model may remain challenging to sample effectively. In such cases, consider whether a simpler model might achieve similar inferential goals while being more computationally tractable. The best model is often not the most complex one, but the one that balances complexity with reliability. The table below shows the summary of fixing strategies for different issues.
Diagnostic Signal Potential Issue Recommended Fix High R-hat Poor mixing between chains Increase iterations, adjust the step size Low ESS High autocorrelation Reparameterization, increase adapt_delta Non-uniform rank plots Chains stuck in different regions Better proposal distribution, start with multiple chains Separated KDEs in trace plots Chains exploring different distributions Reparameterization Funnel shapes in pair plots Hierarchical model issues Non-centered reparameterization Disjoint clusters in pair plots Multimodality with poor mixing Adjusted distribution, simulated annealing
Conclusion
Assessing the quality of MCMC sampling is crucial for ensuring reliable inference. In this article, we explored key diagnostic metrics such as R-hat, ESS, rank plots, trace plots, and pair plots, discussing how each helps determine whether the sampler is performing properly.
If there’s one takeaway we want you to keep in mind it’s that you should always run diagnostics before drawing conclusions from your samples. No single metric provides a definitive answer — each serves as a tool that highlights potential issues rather than proving convergence. When problems arise, strategies such as reparameterization, hyperparameter tuning, and prior specification can help improve sampling efficiency.
By combining these diagnostics with thoughtful modeling decisions, you can ensure a more robust analysis, reducing the risk of misleading inferences due to poor sampling behavior.
References
B. Gilbert, Bob’s bees: the importance of using multiple bees (chains) to judge MCMC convergence (2018), Youtube
Chi-Feng, MCMC demo (n.d.), GitHub
D. Simpson, Maybe it’s time to let the old ways die; or We broke R-hat so now we have to fix it. (2019), Statistical Modeling, Causal Inference, and Social Science
M. Taboga, Markov Chain Monte Carlo (MCMC) methods (2021), Lectures on probability theory and mathematical Statistics. Kindle Direct Publishing.
T. Wiecki, MCMC Sampling for Dummies (2024), twecki.io
Stan User’s Guide, Reparametrization (n.d.), Stan Documentation
The post Are You Sure Your Posterior Makes Sense? appeared first on Towards Data Science.


