










































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)








































































































































































































































.png?#)








-Baldur’s-Gate-3-The-Final-Patch---An-Animated-Short-00-03-43.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

























_Aleksey_Funtap_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)









































































































![Apple's Foldable iPhone May Cost Between $2100 and $2300 [Rumor]](https://www.iclarified.com/images/news/97028/97028/97028-640.jpg)
![Apple Releases Public Betas of iOS 18.5, iPadOS 18.5, macOS Sequoia 15.5 [Download]](https://www.iclarified.com/images/news/97024/97024/97024-640.jpg)
![Apple to Launch In-Store Recycling Promotion Tomorrow, Up to $20 Off Accessories [Gurman]](https://www.iclarified.com/images/news/97023/97023/97023-640.jpg)
























































































































The Story Behind K2 Mode and How It Works
I’m Yan Zhulanow, and I lead the Kotlin Analysis API team. Last year, we made a series of announcements about Kotlin K2 mode in IntelliJ IDEA. Now, as K2 mode is about to become the default, I am thrilled to tell you more about everything we had to go through to make this release happen. […]

I’m Yan Zhulanow, and I lead the Kotlin Analysis API team. Last year, we made a series of announcements about Kotlin K2 mode in IntelliJ IDEA. Now, as K2 mode is about to become the default, I am thrilled to tell you more about everything we had to go through to make this release happen.
Even before the Kotlin language got its name, we had already started to work on the compiler. But we wouldn’t be JetBrains if we didn’t think ahead about how to support a new programming language in an IDE. It was clear from day one that Kotlin should have a proper IntelliJ IDEA plugin.
Easy to say, hard to achieve. For everything to work correctly, both the compiler and the IDE need to understand the programming language perfectly. Those who haven’t worked much with compilers or language tooling may assume it’s all about sharing a parser. In fact, parsers for a statically-typed language are usually the simplest components. Type and call resolution, type inference of various kinds, countless static checks – these are just some of the interesting things that happen inside a semantic code analyzer on top of the produced AST.
By semantic information, I mean all knowledge about declarations that isn’t explicitly stated in the source code. When you declare the `String` return type, you assume it’s just a `String` from the Kotlin standard library. But the compiler doesn’t make assumptions – it analyzes any declarations and imports to find that the reference indeed points to `kotlin.String`. Similarly, when you call `println()`, it’s a relatively straightforward affair for the user, but the compiler needs to search high and low to collect all candidates and choose the most suitable overload.
So, a semantic analyzer is quite a sophisticated piece of software. What makes implementing it even more challenging is supporting myriad corner cases that are barely present in the language specification. This exact reason makes undertaking two separate (but consistent) analyzer implementations, for the compiler and the IDE, much more than “just” double work. Furthermore, it’s not just a one-time effort – as the language evolves, its new features must be supported exactly in the same way. Otherwise, the IDE might show errors on compilable code, or vice versa.
We had to create semantic analyzers for languages such as Java or Rust for IntelliJ IDEA by ourselves, as embedding compilers of those was impossible (or, at least, impractical). However, with Kotlin, it was different. Being the language designers, we had the ability to build the semantic analyzer from scratch to make it work both in the compiler and the IDE.
To make supporting languages easier, IntelliJ IDEA offers a handy framework for generic code analysis. We tore it off, together with the Java code analyzer (to make Java/Kotlin cross-referencing possible), built a compiler on top, and used it as a core of the Kotlin IDE plugin. This approach worked incredibly well for us. We instantly had new language features supported in the IDE, so that we could focus on inspections, refactorings, and other neat features you now use every day.
The team actively experimented with various language features, deciding on the ideal feature combo. That sometimes caused a bit of turbulence in the compiler codebase. At the same time, features of the IDE plugin often requested more and more sacred knowledge about the code, so the compiler had to offer a way to get it. But, as we developed those in the same repository, cross-refactorings rarely were a problem. Instead, people on both ends could improve the code analyzer as everyone was dealing with the same API. Efficient collaboration was priceless, as back then, in 2014, we barely had 20 people working on the whole Kotlin project.
Over time, more and more IDE functionality became dependent on the compiler’s internals. There could have been a turning point where we decided to build a stricter API. But when the compiler became stable enough, the IDE support was full of features, too. On top of that, we had no issues with the existing code at the time, so making such a huge refactoring sounded unreasonable.
The appearance of the K2 Kotlin compiler turned the tables, though. K2 brings a drastically more robust and performant analysis engine, so we were tempted to incorporate it into the IDE as early as possible. However, as we heavily depended on the old compiler, all IDE features needed to be rewritten or at least get a good shake-up.
Of course, the fact that we would need to actively develop K2 didn’t come as a surprise to us. We were eager to improve performance and fix numerous bugs on the IDE side, but our hands were often tied owing to the shortcomings of the old compiler’s architecture. While the transition to K2 entailed an overwhelming amount of work, we were rather looking forward to it. In any case, we didn’t have much in the way of alternatives, as all emerging Kotlin language features were only developed for K2.
Sharing is hard
When we talk about “sharing an analysis engine”, it might conjure images of a black box that does some magic with the AST and outputs the results. In reality, use cases between the compiler and IDE are so different that efficient analysis of the code requires fine-grained control over the process.
For example, let’s see how code is analyzed in them. The compiler has a rather linear flow – it takes the module sources, analyzes them together, and produces some output (i.e. `.class` files). On the other hand, in the IDE, code is usually analyzed on demand. Say, the user activates an autocompletion popup, and to show parameter types for the suggested functions, the IDE will trigger parameter resolution. However, function bodies won’t be analyzed, as the IDE doesn’t need them for autocompletion.
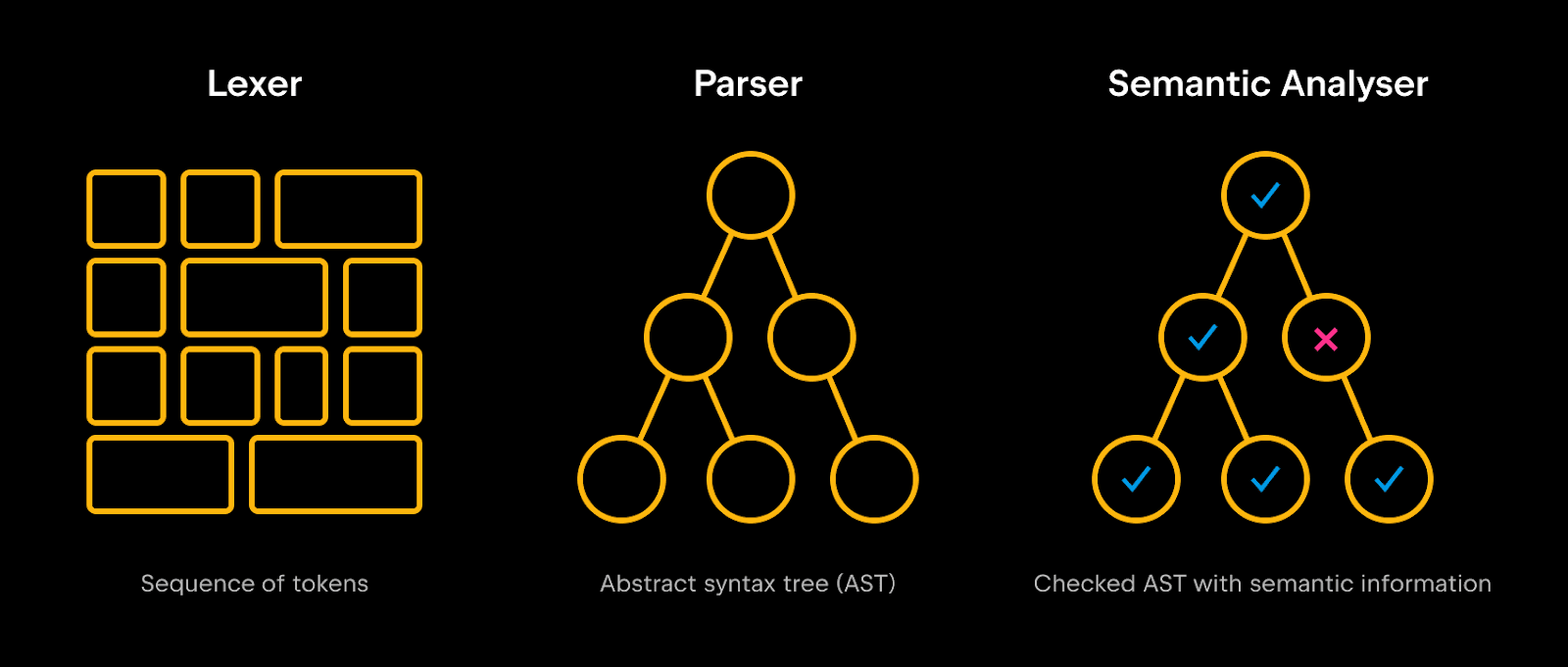
Then, the compiler analyzes all the files in a module. However, it never works with multiple modules at once because module dependencies are handled by a build system. In the IDE, though, all files in a project are visible at once, and the programmer can freely navigate around. Not to mention, the IDE needs to be fast, so it caches as many analysis results as possible. Each time the programmer types a letter, parts of that collected information might have to be discarded.
These were just a couple of conceptual differences between code analysis in compilers and in IDEs – there are many more. Still, the point is clear: the compiler needs quick batch processing, while the IDE typically wants to analyze as little code as possible.
How things worked before
In the now-obsolete compiler, we wrapped parts of the compiler logic into lazy blocks to make code analysis in the IDE efficient. It sounded natural at the time – when the IDE requests semantic information for a declaration, it will be automatically computed and cached. Lazy blocks could depend on other blocks, creating a sophisticated graph.
To simplify the initial implementation, all the laziness happened under a single shared lock. Even that simple solution seemed quick enough in practice. At the same time, we understood we could decide to improve that part, so we introduced StorageManager, an abstraction layer for deferred computations. A close analogy will be a custom `lazy` property delegate that accepts an executor for the passed lambdas.
Well, performance issues started to appear years later as Kotlin projects became larger and IntelliJ IDEA got lots of new features. But we’ve got a fancy API, StorageManager, so we can build a better, multi-threaded implementation of it, right? Well, not quite – too many places throughout the compiler means that no more than one thread can reach those places at the same time. By replacing the caching, we only got sporadic errors instead of a performance boost. Essentially, we got an abstraction that nobody respected.
In addition, implicit laziness might look elegant at first sight, but it made the compiler code much less friendly when it came to debugging and optimization. When you can’t precisely track what’s resolved and what isn’t, it’s harder to understand why the analyzer ended up being in some weird inconsistent state. And, as underlying logic is uncontrollable, covering it with tests also becomes challenging.
Could we have done better from the very beginning? Yes, for sure we could have. Still, the old compiler served us faithfully for more than 10 years. During that time, the Kotlin team gathered a lot of experience on how to share the code analyzer for our language efficiently. We knew what worked well – and what didn’t – and were fully prepared for the hard work that lay ahead.
A new approach
We spent a great deal of time ensuring that the new code analyzer works both in the compiler and the IDE in the best way possible.
In the K2 compiler, we dropped all implicit laziness. Instead, we split code analysis into a sequence of phases, each analyzing a specific part of source code. For example, the SUPER_TYPES phase computes supertypes of classes, and TYPES handles signature types (such as parameter and explicit return types of functions). Each phase gradually enriches the AST with chunks of semantic information.
Clear separation between phases greatly simplifies the compiler architecture. But it’s the IDE where the new architecture really shines. A phase may run not only on a file, but also on individual declarations. So, when the IDE requests some semantic data, the declaration is simply resolved up to the phase that provides that data.
A declaration usually doesn’t come alone – it depends on other declarations. In the following example, the compiler needs to resolve Array and String classes, as well as getOrNull and println library calls:
fun main(args: Array) { val name = args.getOrNull(0) ?: "Anonymous" println("Hello, $name!") }
We’re on a happy path here, as all these declarations come from a library, and for library declarations, we can get all semantic information straight away. But if any of those happened to be in sources, we would also have to analyze them. This would have resulted in an avalanche of implicit computations in the old compiler. In K2 mode, again, we simply instruct the compiler to resolve the dependent declaration to a specific phase, after which we have all the semantic information we need. For declarations with a specified return type, it would be CONTRACTS.
In other words, a declaration can only be in one of a few fixed states – either unresolved or resolved up to a specific phase. Such an approach secures the on-demand behavior for the IDE, but provides much more predictability than the old solution. Furthermore, seeing as we can now keep track of all resolution operations, we can precisely cover lazy resolution in tests.
The new laziness architecture isn’t the only plausible change we made. The K2 compiler still uses a single thread, as in complex projects, parallel compilation of different modules often makes use of multiple cores anyway. However, all resolution logic is concurrency-tolerant now, so we can finally analyze multiple declarations simultaneously. The global lock is no more!
At this point, a curious reader might ask: how can we resolve two declarations that point to each other in parallel? Well, in most cases, nothing special really happens. Say we have two functions that call each other; body analysis of both functions will require analysis of the other function’s signature (as we need to know parameter types for call resolution), but the bodies themselves are not interconnected.
However, in a few phases, a loop may indeed happen. Let’s assume we have two functions with implicit return types, and those functions point to each other:
fun foo() = bar() fun bar() = foo()
This is obviously an invalid piece of code – but the IDE still needs to understand it correctly to report the recursion in type checking! If we request full analysis for both functions at the same time, one worker will have to wait until the other declaration analysis is complete. Still, such loops are not so common, and in most cases, code analysis happens fully in parallel, including the most expensive BODY_RESOLVE phase.
Parallel code analysis doesn’t simply make the IDE faster – it enables new behaviors. For example, if you ran Find Usages on a really huge codebase, it could take quite some time to collect all the results. With the old K1 Kotlin plugin, you could barely use the IDE – code highlighting didn’t work, the completion popup was sluggish, etc. Now you understand that all this happened because Find Usages held a global resolution lock. With K2 mode, no matter what features you activate, all of them will be able to run simultaneously.
The Analysis API
Switching to the K2 compiler brought us huge benefits, some of which we have yet to use fully. However, migrating existing features wasn’t easy at all – remember, all of them were built on top of the old compiler’s internals. Ultimately, we had to rewrite code highlighting entirely, auto-completion, numerous refactorings and inspections, and many more parts of Kotlin support in IntelliJ IDEA.
But even if we forget the K2 transition story for a second, the situation we were in was far from ideal.
- Compiler abstractions leaked too many things that were only needed for code analysis. At the same time, simple data retrieval was clunky. The compiler carried the semantic parts of AST around, but the IDE had to fetch chunks of it explicitly. Also, because of implicit laziness, even more ceremony was sometimes required to force everything to be calculated.
- Historically, the Kotlin compiler heavily embraced the idea “code is the documentation”. It was rare to find comments explaining use cases of methods and classes, let alone any relevant formal contracts.
- Some time ago, the Kotlin plugin moved to the IntelliJ IDEA repository and became a natural part of the IDE. It greatly helped us in the development of new IDE features, but then we lost an easy way to refactor the compiler. Indeed, we now had to change the code in two products with different release cycles. Thankfully, the compiler team was already busy with K2 at the time, so changes in the obsolete compiler were limited.
Besides the Kotlin support itself, IntelliJ IDEA bundles various plugins that depend on Kotlin, such as Spring, DevKit, or Ktor. All those also required migration, but we could either do that ourselves or provide in-house guidance. But there are also hundreds of brave developers from the Kotlin community who built their plugins on top of the chaotic compiler APIs. For us, the mentioned issues were rather an inconvenience, but for a person who doesn’t work with Kotlin on a daily basis, it was a nightmare.
So, together with Kotlin K2 mode, we developed a library designed specifically for on-demand code analysis – the Kotlin Analysis API. It encapsulates all complex resolution logic and provides documented abstractions with clear and predictable behavior. As a user, you only request pieces of semantic code information you’re interested in, and the library takes care of all lazy and parallel analysis, together with caching the results.
For instance, to get an expression type, you only need to call the KtExpression.expressionType extension property provided by the library. If the type isn’t yet known, the body of the containing declaration will be automatically analyzed.
fun KtExpression.hasStringType(): Boolean {
analyze(this) {
return expressionType == builtinTypes.string
}
}
Before, you needed to specify explicitly which declaration to resolve, get an opaque container with all semantic information that was collected during code analysis, and fetch an expression type from it. You could also find nothing there if lazy resolution avoided computing that type for some reason. The Migrating from K1 documentation article tells more on the API differences.
Today, the Analysis API offers backward compatibility for its core API, which is aligned with IntelliJ IDEA’s policies. We also built a documentation website with guides on using the library and how to migrate your existing code from the legacy API. Furthermore, we approached maintainers of all plugins on JetBrains Marketplace that used the old Kotlin compiler, and we’re happy to see that almost all plugins already migrated to the Analysis API. Thank you!
What’s next?
Together with IntelliJ IDEA 2025.1, we are making Kotlin K2 mode the default one, but our work doesn’t stop here. Even though the code is well-tested, there’s still a lot of new code that needs to be battle-tested in production. So, if you find that something works incorrectly, don’t hesitate to contact us:
- YouTrack: Create a KTIJ ticket to report an issue or a bug. The most efficient way to get the problem fixed
- Slack: #intellij channel in Kotlin Slack to ask your questions
- Email: k2-mode-feedback@jetbrains.com to provide more general feedback.
We are eager for feedback and will try our best to make the Kotlin IDE experience as pleasurable as the laws of physics allow us to!



