











































































































































































![How to Use AI as a Productivity Tool with Mike Kaput [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/v2MAICON-Speaker_Series.png)
![[The AI Show Episode 152]: ChatGPT Connectors, AI-Human Relationships, New AI Job Data, OpenAI Court-Ordered to Keep ChatGPT Logs & WPP’s Large Marketing Model](https://www.marketingaiinstitute.com/hubfs/ep%20152%20cover.png)















































































































































![Designing a Robust Modular Hardware-Oriented Application in C++ [closed]](https://i.sstatic.net/f2sQd76t.webp)










































































































_Alexander-Yakimov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Zoonar_GmbH_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




















































































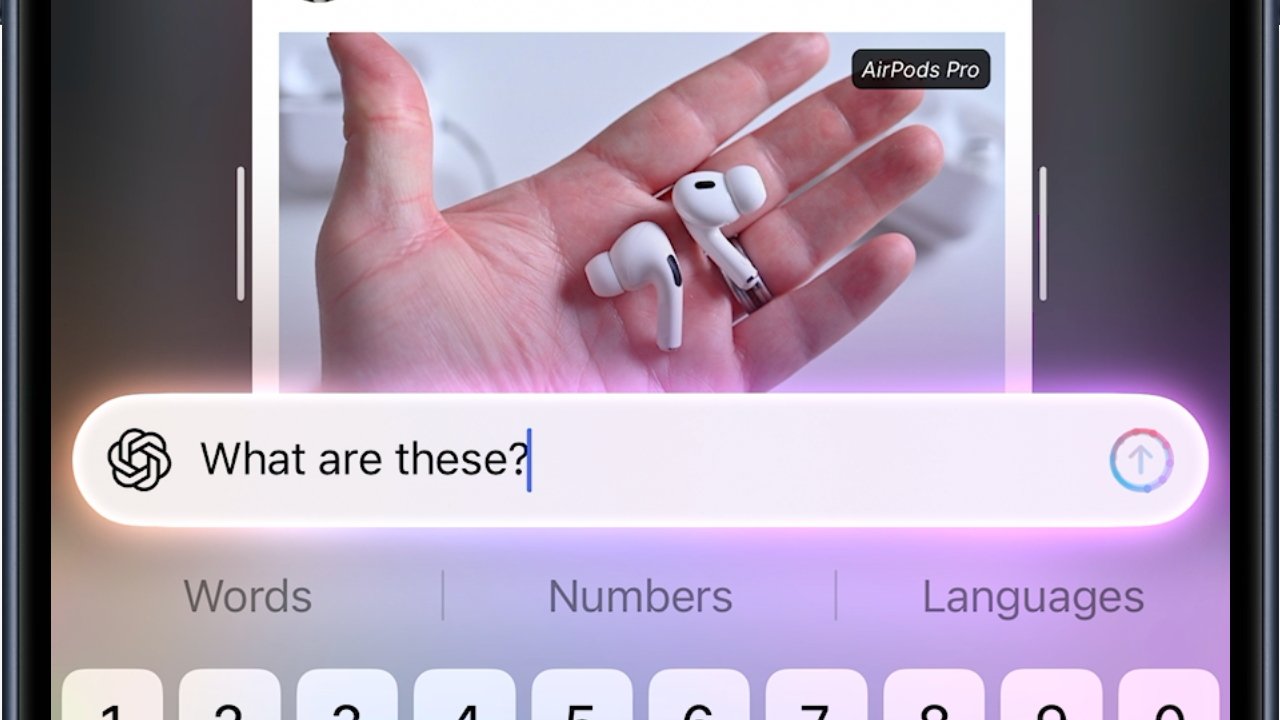

























![AirPods Pro 3 Not Launching Until 2026 [Pu]](https://www.iclarified.com/images/news/97620/97620/97620-640.jpg)
![Apple Releases First Beta of iOS 18.6 and iPadOS 18.6 to Developers [Download]](https://www.iclarified.com/images/news/97626/97626/97626-640.jpg)
![Apple Seeds watchOS 11.6 Beta to Developers [Download]](https://www.iclarified.com/images/news/97627/97627/97627-640.jpg)
![Apple Seeds tvOS 18.6 Beta to Developers [Download]](https://www.iclarified.com/images/news/97628/97628/97628-640.jpg)




















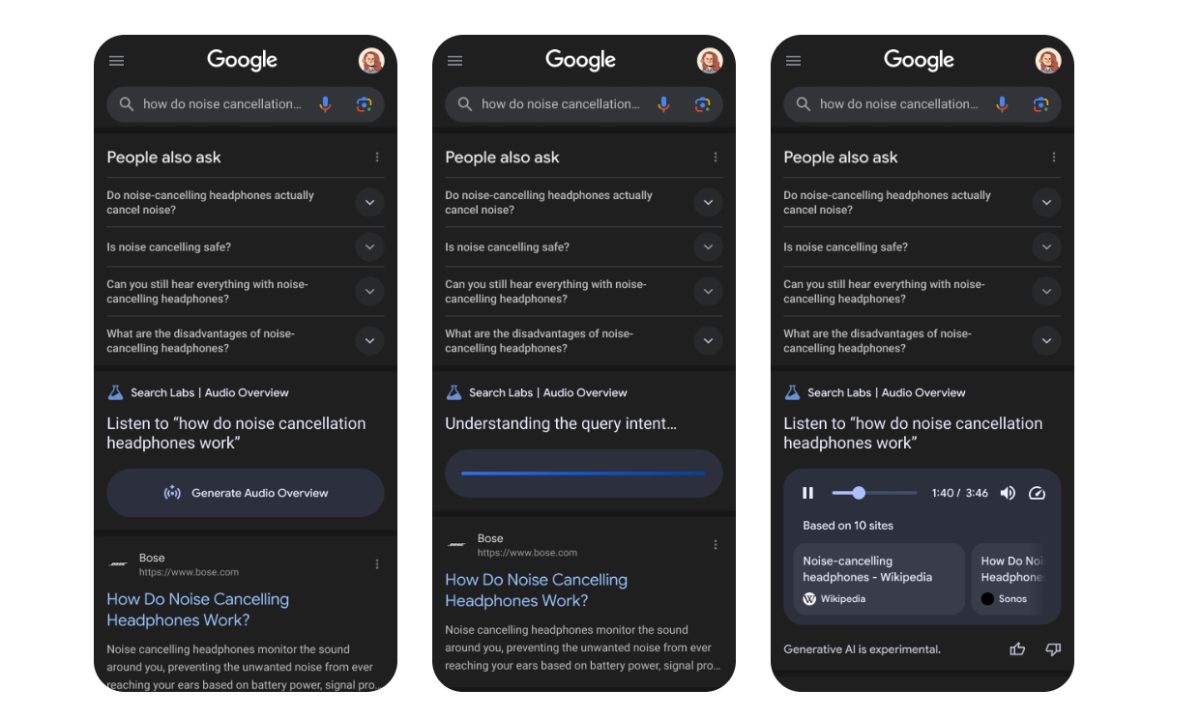















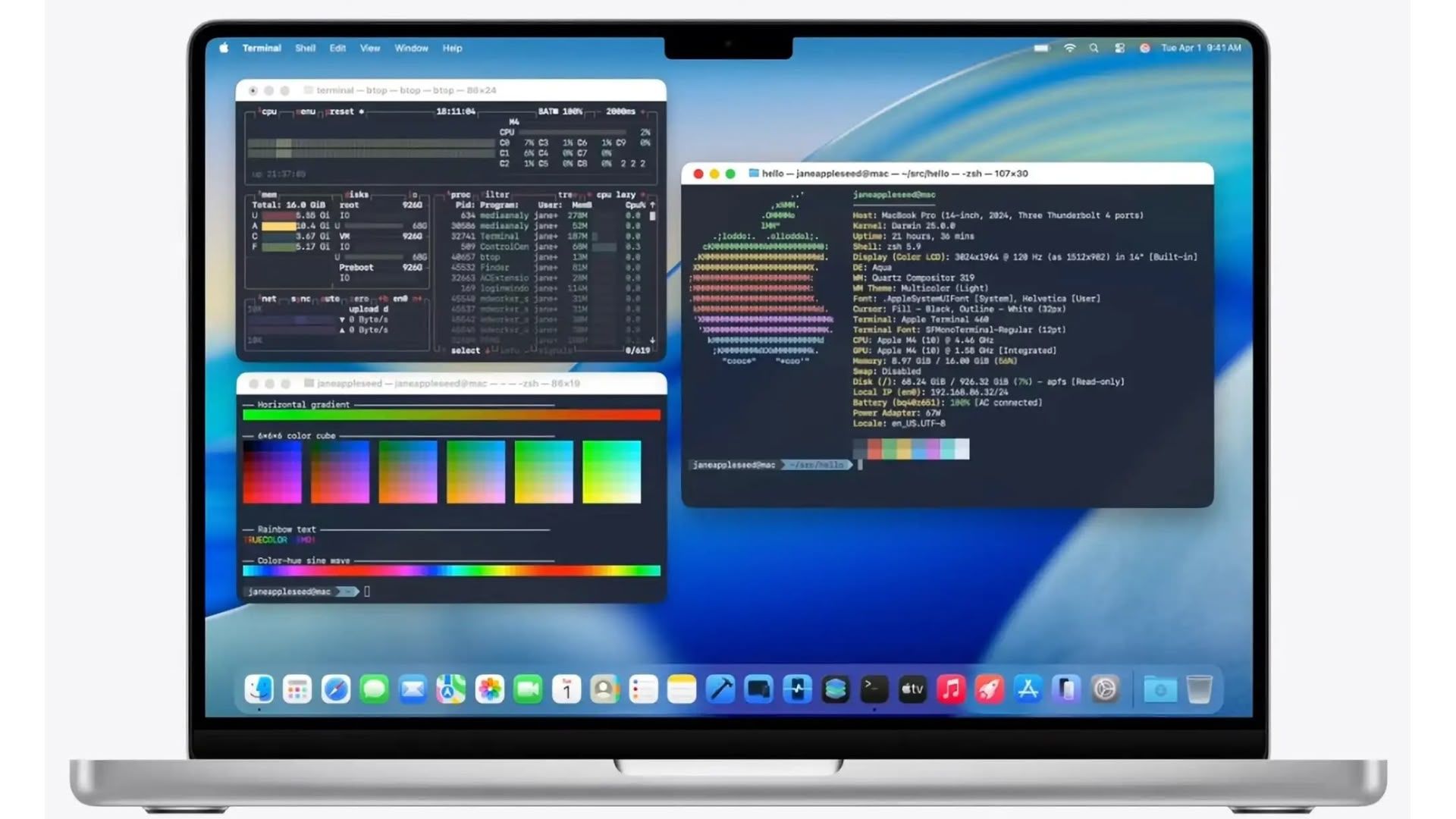
























From Notebook to Model: A Practical Guide to Jupyter for Machine Learning
Intro Want to train a model without installing a hulking IDE or writing a separate script for every experiment? Jupyter notebooks let you mix runnable code, notes, and pretty plots in one share‑able file. In this guide we’ll spin up a notebook, load data, build a logistic regression classifier, and visualize the results. No sweat! tldr; We’ll install Jupyter with pip, crack open a notebook, wrangle a CSV in pandas, train & evaluate a scikit‑learn model, and chart its performance. All inside a single .ipynb. You’ll finish with a repeatable workflow you can fork for any ML idea. Setting Up / Prerequisites Python ≥ 3.9 (use pyenv or the official installer) pip or conda package manager Virtual environment (e.g., python -m venv venv or conda create -n ml-jupyter python=3.11) A terminal with git (optional, for dataset download) The following Python packages: pip install jupyterlab pandas scikit-learn matplotlib seaborn Why Jupyter Rocks (and How to Use it Well) Jupyter isn't just a place to run Python. It's a digital lab notebook built for messy, iterative exploration. You don't have to write a full script before running your code. Instead, you write and run cells one at a time, keeping results visible as you go. Tip: Think of each cell as a test tube: Mix something new, see what happens, make notes, then move on. Some key notebook best-practices: Break work into small cells - Each step (importing, loading data, preprocessing, training, etc.) should be its own cell. This helps with debugging and lets you rerun only the parts you need. Use markdown cells to narrate - Don't just write code, explain it! You can use markdown cells to add headings, lists.... Markdown and even LaTeX math for formulas. Restart & run all often - Use Kernal -> Restart Kernal and Run All Cells to ensure your notebook runs from top to bottom. Name your notebooks clearly - Use descriptive names like edh-staple-classifier.ipynb so you can find them later. Implementation Steps Launch Jupyter Before you write a single line of Python you need a notebook server running. jupyter lab boots up a lightweight web server on localhost:8888 (or the next free port) and opens your default browser. From here every notebook lives in the directory you launched the command from, so start it at the root of your project folder. Tip: If you prefer the classic interface, swap lab for notebook. Add --port 9000. jupyter lab # or: jupyter notebook Create a Notebook In the Jupyter UI choose File → New → Notebook and select Python 3. A new tab appears with an empty code cell and an auto‑generated filename like Untitled.ipynb. Rename it to something memorable (e.g., edh-staple-classifier.ipynb) so future‑you can find it quickly. Note: Every notebook is tied to a kernel. A kernal is an active Python process that keeps variables in memory between cell runs. Import Libraries Your first code cell should gather every library you’ll need. Keeping imports together makes it easier to debug missing packages and rerun the whole notebook end‑to‑end. Notice we pull in matplotlib before seaborn; the latter piggybacks on the former for plotting. import pandas as pd from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report, confusion_matrix import matplotlib.pyplot as plt import seaborn as sns Tip: Add %reload_ext autoreload and %autoreload 2 if you’re developing helper modules alongside the notebook. Jupyter will hot‑reload them on every cell run. Load & Inspect Data Jupyter automatically renders pandas DataFrames as slick HTML tables, so a simple df.head() becomes an instant mini‑dashboard. Always eyeball the first few rows and call df.info() to catch missing values or wonky dtypes before you train. df = pd.read_csv('cards.csv') # sample MTG card dataset display(df.head()) df.info() Gotcha: If your CSV lives on the web, read it directly with pd.read_csv('https://...')—no download step required! Pre‑process Features Feature engineering is where ML wins or loses. Here we cherry‑pick three already‑encoded columns and split the data 80/20 into training and test sets. Setting random_state locks in determinism so a colleague can reproduce your exact split. X = df[['mana_value', 'type_encoded', 'color_identity_encoded']] y = df['is_edh_staple'] X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y ) Tip: Use stratify=y when your classes are imbalanced to preserve the same positive/negative ratio in both splits. Train the Model Logistic regression is fast, interpretable, and perfect for a binary “staple or not” task. Crank max_iter up if the default 100 iterations fails to converge. model = LogisticRegression(max_iter=1000) model.fit(X_train, y_train)

Intro
Want to train a model without installing a hulking IDE or writing a separate script for every experiment? Jupyter notebooks let you mix runnable code, notes, and pretty plots in one share‑able file. In this guide we’ll spin up a notebook, load data, build a logistic regression classifier, and visualize the results. No sweat!
tldr; We’ll install Jupyter with pip, crack open a notebook, wrangle a CSV in pandas, train & evaluate a scikit‑learn model, and chart its performance. All inside a single
.ipynb. You’ll finish with a repeatable workflow you can fork for any ML idea.
Setting Up / Prerequisites
-
Python≥ 3.9 (use pyenv or the official installer) -
piporcondapackage manager -
Virtual environment(e.g.,python -m venv venvorconda create -n ml-jupyter python=3.11) - A terminal with
git(optional, for dataset download) - The following Python packages:
pip install jupyterlab pandas scikit-learn matplotlib seaborn
Why Jupyter Rocks (and How to Use it Well)
Jupyter isn't just a place to run Python. It's a digital lab notebook built for messy, iterative exploration. You don't have to write a full script before running your code. Instead, you write and run cells one at a time, keeping results visible as you go.
Tip: Think of each cell as a test tube: Mix something new, see what happens, make notes, then move on.
Some key notebook best-practices:
-
Break work into small cells- Each step (importing, loading data, preprocessing, training, etc.) should be its own cell. This helps with debugging and lets you rerun only the parts you need. -
Use markdown cells to narrate- Don't just write code, explain it! You can use markdown cells to add headings, lists.... Markdown and even LaTeX math for formulas. -
Restart & run all often- UseKernal -> Restart Kernal and Run All Cellsto ensure your notebook runs from top to bottom. -
Name your notebooks clearly- Use descriptive names likeedh-staple-classifier.ipynbso you can find them later.
Implementation Steps
Launch Jupyter
Before you write a single line of Python you need a notebook server running. jupyter lab boots up a lightweight web server on localhost:8888 (or the next free port) and opens your default browser. From here every notebook lives in the directory you launched the command from, so start it at the root of your project folder.
Tip: If you prefer the classic interface, swap
labfornotebook. Add--port 9000.
jupyter lab # or: jupyter notebook
Create a Notebook
In the Jupyter UI choose File → New → Notebook and select Python 3. A new tab appears with an empty code cell and an auto‑generated filename like Untitled.ipynb. Rename it to something memorable (e.g., edh-staple-classifier.ipynb) so future‑you can find it quickly.
Note: Every notebook is tied to a kernel. A kernal is an active Python process that keeps variables in memory between cell runs.
Import Libraries
Your first code cell should gather every library you’ll need. Keeping imports together makes it easier to debug missing packages and rerun the whole notebook end‑to‑end. Notice we pull in matplotlib before seaborn; the latter piggybacks on the former for plotting.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
Tip: Add
%reload_ext autoreloadand%autoreload 2if you’re developing helper modules alongside the notebook. Jupyter will hot‑reload them on every cell run.
Load & Inspect Data
Jupyter automatically renders pandas DataFrames as slick HTML tables, so a simple df.head() becomes an instant mini‑dashboard. Always eyeball the first few rows and call df.info() to catch missing values or wonky dtypes before you train.
df = pd.read_csv('cards.csv') # sample MTG card dataset
display(df.head())
df.info()
Gotcha: If your CSV lives on the web, read it directly with
pd.read_csv('https://...')—no download step required!
Pre‑process Features
Feature engineering is where ML wins or loses. Here we cherry‑pick three already‑encoded columns and split the data 80/20 into training and test sets. Setting random_state locks in determinism so a colleague can reproduce your exact split.
X = df[['mana_value', 'type_encoded', 'color_identity_encoded']]
y = df['is_edh_staple']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
Tip: Use
stratify=ywhen your classes are imbalanced to preserve the same positive/negative ratio in both splits.
Train the Model
Logistic regression is fast, interpretable, and perfect for a binary “staple or not” task. Crank max_iter up if the default 100 iterations fails to converge.
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
Heads‑up: After training, check
model.coef_to see which features push predictions higher or lower—handy for blog post anecdotes.
Evaluate Performance
Next we generate a classification report and plot a confusion matrix. The heatmap gives an at‑a‑glance view of false positives vs false negatives.
preds = model.predict(X_test)
print(classification_report(y_test, preds))
cm = confusion_matrix(y_test, preds)
plt.figure(figsize=(4, 4))
sns.heatmap(cm, annot=True, fmt='d', cbar=False)
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
plt.show()
Note: If recall is more valuable than precision for your use‑case, focus on the lower row of the matrix.
Iterate & Document
Notebooks shine at rapid experimentation. Duplicate a cell, tweak a hyper‑parameter, rerun, and stash results in a Markdown cell for future reference.
Workflow tip: Use
nbdimeto diff notebook versions in git or adopt the new.ipynbtext‑based format (jupyter nbconvert --to markdown) for readable PRs.
## Experiment 002 — Added stratification, accuracy +3.2 %
Next Steps
- Swap in more powerful algorithms (RandomForest, XGBoost).
- Perform hyper‑parameter tuning with
GridSearchCV. - Use JupyterLab extensions like
variable inspectorornbdimefor diffing. - Export your notebook to HTML or Markdown for sharing (File → Export).
- Push it to a GitHub repo and enable
Binderfor one‑click reproducibility.
Outro
Thanks for reading! If this guide levelled up your ML workflow, pass it on to your fellow data dabblers or drop a comment with what you built. Until next time. Happy modelling!

