














































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)





























































































































![From Accountant to Data Engineer with Alyson La [Podcast #168]](https://cdn.hashnode.com/res/hashnode/image/upload/v1744420903260/fae4b593-d653-41eb-b70b-031591aa2f35.png?#)





































































































.png?#)












































































































































![Apple Watch SE 2 On Sale for Just $169.97 [Deal]](https://www.iclarified.com/images/news/96996/96996/96996-640.jpg)

![Apple Posts Full First Episode of 'Your Friends & Neighbors' on YouTube [Video]](https://www.iclarified.com/images/news/96990/96990/96990-640.jpg)

























































































































Attacks via a New OAuth flow, Authorization Code Injection, and Whether HttpOnly, PKCE, and BFF Can Help
In this article, we’ll take a close look at an interesting attack vector targeting applications that use OAuth/OIDC. We’ll explore the required preconditions for this attack — and see that they might not be as unrealistic as they seem at first glance. We’ll also cover the Backend-for-Frontend (BFF) pattern and different ways to implement PKCE for confidential clients — and check whether these approaches actually help to mitigate the attack in question. Additionally, we’ll review other existing recommendations and proposed best practices, and think about further protection measures that can really make a difference. The article includes examples, diagrams, and even videos. This material will be useful both for application developers and for those who look at the system from the attacker’s perspective. Table of Contents Introduction Example of an attack Preconditions for the attack BFF is not a cure-all Will PKCE Help? PKCE for confidential clients Code verifier and code challenge generated on the client side Recommendations from BCP for OAuth 2.0 Security Reference to the attack in FAPI 2.0 Security Profile Relevance and applicability of the attack Protection measures Form Post Response Mode Additional protection measures Historical examples Conclusion Introduction A lot can be said about OAuth and OIDC security on the client side. Usually, we discuss secure token storage on the frontend so that an attacker who is able to execute malicious JavaScript on the application’s page can’t access them. I wrote about it at the beginning of 2023. Since then, the information has spread widely, and identical recommendations have also been added to the OAuth 2.0 for Browser-Based Applications draft. Therefore, today we are going to discuss another interesting issue rather than focusing on the topics that have already been covered. On the one hand, as an attacker I can try to steal existing tokens from client-side storage. However, it might not be necessary if we think it through. Often, it may be easier and more effective not to mind them at all. Instead, the attacker can obtain their own tokens (or not even tokens - spoiler!). So today, we are going to discuss attacks based on the initiation of a new, distinct OAuth flow and not aimed at compromising existing credentials. The attacker simply obtains their own such credentials. It is also worth noting the growing use of confidential clients, the implementation of which generally aligns with the patterns described in OAuth 2.0 for Browser-Based Applications, namely Backend-for-Frontend (BFF) and Token Mediating-Backend. Note: I suggest distinguishing the BFF pattern declared here from another pattern with the same name from the world of distributed systems and microservices to avoid confusion. While both of them, in fact, can be considered client-specific API gateways, they have different goals. The BFF pattern from OAuth 2.0 for Browser-Based Applications focuses on a BFF acting as an OAuth client, while the general pattern definitions do not include this characteristic in the set of mandatory ones, focusing on other aspects. Remarkably, it is mentioned that the “Acquisition and Extraction of New Tokens” attack is mitigated for both of those patterns. The attack is described as follows: In this advanced attack scenario, the attacker completely disregards any tokens that the application has already obtained. Instead, the attacker takes advantage of the ability to run malicious code that is associated with the application's origin. With that ability, the attacker can inject a hidden iframe and launch a silent Authorization Code flow. This silent flow will reuse the user's existing session with the authorization server and result in the issuing of a new, independent set of tokens. Equally interesting is the explanation of how exactly this attack is prevented: The third scenario, where the attacker obtains a fresh set of tokens by running a silent flow, is mitigated by making the BFF/token-mediating backend a confidential client. Even when the attacker manages to obtain an authorization code, they are prevented from exchanging this code due to the lack of client credentials. Additionally, the use of PKCE prevents other attacks against the authorization code. Let’s remember those words, we’ll come back to them later. It’s important to note that I am not saying that you should avoid using confidential clients. On the contrary, the use of such can improve security in many aspects. Although, I would like to point out that the use of the BFF alone (even with PKCE) does not mitigate a number of attacks that are possible if the attacker is able to inject malicious code into the application’s pages. Such attacks are also not new and have been around for quite some time. Let’s take a closer look at them through examples. Example of an attack It’s hard to talk about information security in a vacuum, s
In this article, we’ll take a close look at an interesting attack vector targeting applications that use OAuth/OIDC. We’ll explore the required preconditions for this attack — and see that they might not be as unrealistic as they seem at first glance.
We’ll also cover the Backend-for-Frontend (BFF) pattern and different ways to implement PKCE for confidential clients — and check whether these approaches actually help to mitigate the attack in question. Additionally, we’ll review other existing recommendations and proposed best practices, and think about further protection measures that can really make a difference. The article includes examples, diagrams, and even videos.
This material will be useful both for application developers and for those who look at the system from the attacker’s perspective.
Table of Contents
- Introduction
-
Example of an attack
- Preconditions for the attack
- BFF is not a cure-all
-
Will PKCE Help?
- PKCE for confidential clients
- Code verifier and code challenge generated on the client side
- Recommendations from BCP for OAuth 2.0 Security
- Reference to the attack in FAPI 2.0 Security Profile
- Relevance and applicability of the attack
-
Protection measures
- Form Post Response Mode
- Additional protection measures
- Historical examples
- Conclusion
Introduction
A lot can be said about OAuth and OIDC security on the client side. Usually, we discuss secure token storage on the frontend so that an attacker who is able to execute malicious JavaScript on the application’s page can’t access them.
I wrote about it at the beginning of 2023. Since then, the information has spread widely, and identical recommendations have also been added to the OAuth 2.0 for Browser-Based Applications draft. Therefore, today we are going to discuss another interesting issue rather than focusing on the topics that have already been covered.
On the one hand, as an attacker I can try to steal existing tokens from client-side storage. However, it might not be necessary if we think it through. Often, it may be easier and more effective not to mind them at all. Instead, the attacker can obtain their own tokens (or not even tokens - spoiler!). So today, we are going to discuss attacks based on the initiation of a new, distinct OAuth flow and not aimed at compromising existing credentials. The attacker simply obtains their own such credentials.
It is also worth noting the growing use of confidential clients, the implementation of which generally aligns with the patterns described in OAuth 2.0 for Browser-Based Applications, namely Backend-for-Frontend (BFF) and Token Mediating-Backend.
Note: I suggest distinguishing the BFF pattern declared here from another pattern with the same name from the world of distributed systems and microservices to avoid confusion. While both of them, in fact, can be considered client-specific API gateways, they have different goals. The BFF pattern from OAuth 2.0 for Browser-Based Applications focuses on a BFF acting as an OAuth client, while the general pattern definitions do not include this characteristic in the set of mandatory ones, focusing on other aspects.
Remarkably, it is mentioned that the “Acquisition and Extraction of New Tokens” attack is mitigated for both of those patterns. The attack is described as follows:
In this advanced attack scenario, the attacker completely disregards any tokens that the application has already obtained. Instead, the attacker takes advantage of the ability to run malicious code that is associated with the application's origin. With that ability, the attacker can inject a hidden iframe and launch a silent Authorization Code flow. This silent flow will reuse the user's existing session with the authorization server and result in the issuing of a new, independent set of tokens.
Equally interesting is the explanation of how exactly this attack is prevented:
The third scenario, where the attacker obtains a fresh set of tokens by running a silent flow, is mitigated by making the BFF/token-mediating backend a confidential client. Even when the attacker manages to obtain an authorization code, they are prevented from exchanging this code due to the lack of client credentials. Additionally, the use of PKCE prevents other attacks against the authorization code.
Let’s remember those words, we’ll come back to them later.
It’s important to note that I am not saying that you should avoid using confidential clients. On the contrary, the use of such can improve security in many aspects. Although, I would like to point out that the use of the BFF alone (even with PKCE) does not mitigate a number of attacks that are possible if the attacker is able to inject malicious code into the application’s pages.
Such attacks are also not new and have been around for quite some time. Let’s take a closer look at them through examples.
Example of an attack
It’s hard to talk about information security in a vacuum, so let’s first define a brief attacker model.
In these cases, the attacker is an external entity (a web attacker) who is able to inject JavaScript code into any page of the legitimate application that has an origin matching the origin of the redirect URI.
At the same time, communication channels are protected by TLS and the attacker has no access to unencrypted traffic or physical access to the user’s devices. The attacker also lacks other special traits.
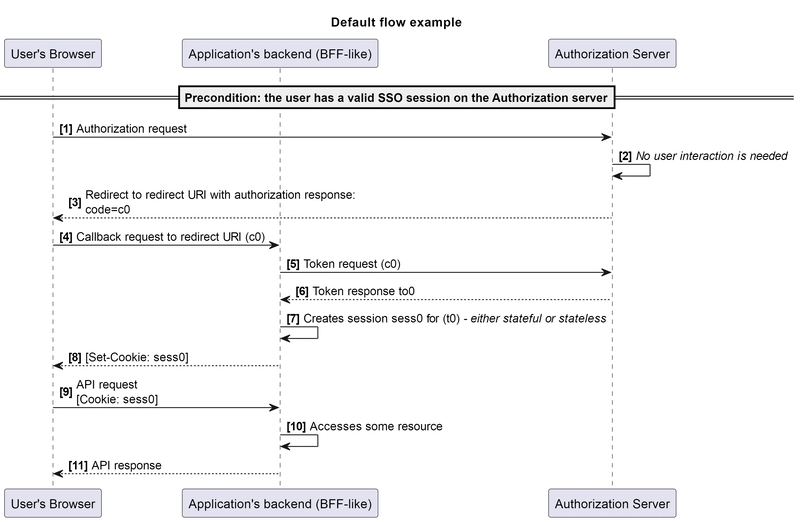
We begin with the most simple example, in which we have a legitimate application (client), that implements authorization code flow, with its backend acting as a confidential client. I noticed that sometimes the BFF pattern is offered as a more secure choice compared to the mentioned token-mediating backend since it stores obtained tokens on the server side. So, for illustrative purposes, in our examples the confidential client will be implemented in a BFF-like style: issuing its own session ID and further proxying API requests through itself.
This can be schematically depicted as follows:
Video demonstration of such an application:
The attack could then look like this:
We can see that even if the cookie has an HttpOnly attribute, it does not prevent the attacker from obtaining its value. The attacker sends the request from their own controlled environment, so setting a cookie is actually just a header that the attacker can read.
During the attack, the attacker successfully obtains the authorization response value from the user’s browser. Also, they obtain the corresponding created session identifier that allows them to access resources impersonating the user. Meanwhile, the attack is possible regardless of whether the user is authenticated in the application at the time the attack begins or not.
It should also be pointed out that the considered attack scenario applies to the token-mediating backend pattern as well. In this case, the attacker is able to obtain the access token value directly for the same purpose.
Preconditions for the attack
It can be seen that for the successful execution of such an attack, a number of conditions should be met.
1. Execution of malicious JavaScript code within the context of one of the application’s pages with the same origin
This is usually achieved through the following methods:
Cross-Site Scripting (XSS)
A vulnerable or compromised dependency, or third-party script
We all know that a dedicated redirect URI page is provided to us so that we can keep it as clean as possible, excluding any additional functionality and third-party scripts (even analytics may be questionable). That’s good and correct.
The thing is, the vulnerability does not necessarily have to be on the exact page to make the theft of the authorization response possible. In fact, the restriction is within the same origin. It’s also useful to note that there are mechanisms where, by design, the specific redirect URI page is not actually defined, but instead, it’s made clear that the authorization response is available within the origin. This can be clearly seen in the example of the following condition.
2. The ability to obtain the parameters of the authorization response
As we saw in the previous paragraph, in the general case, it may be enough for the attacker to be able to execute their JavaScript code on one of the application’s pages to steal the authorization response parameters. Here, I would like to briefly review the main methods for implementing such an attack.
Using the web message response mode and setting up one’s own event listener
Injecting an invisible iframe and obtaining the authorization response from the location object + breaking the OAuth flow
Briefly opening a new window and obtaining the authorization response from the location object + breaking the OAuth flow
Among the different response modes in OAuth, there is the “web message response mode”, which implies sending the authorization response parameters via the postMessage API. An interesting thing is that it’s essentially not specified: there are just two expired drafts from an early stage - the OAuth 2.0 Web Message Response Mode draft and the OAuth 2.0 Web Message Response Mode for Popup- and Iframe-based Authorization Flows draft.
However, the lack of a common specification does not prevent this approach from being implemented in the real world.
In most cases, the implementation looks like this: the URL of the authorization request is opened in a new window (popup) or inside an iframe. In response to the authorization request, the authorization server itself returns an HTML page that, by means of JavaScript, sends the authorization response parameters to the parent window via postMessage.
Among the best security practices for postMessage, we usually see validating the origin of the parent window (by strict comparison with a static string value) before sending the message with the authorization response parameters to it. This measure is undoubtedly important: it prevents the attacker from receiving the message with the authorization response on their own origin.
However, in the context of the examined attack, there is a catch. The attacker executes their code on the page with the same origin as the other pages of the legitimate application. Accordingly, the described origin validation cannot protect against the described attack. The attacker will initiate, one way or another, a new authorization request, set their own event listener for receiving “message” events, and will successfully obtain the message with the authorization response parameters, which was kindly sent to the main window.
An example of a simple Proof-of-Concept (PoC) for implementing such an attack:
window.addEventListener("message", (e) => {
console.log(`Authorization response: ${JSON.stringify(e.data)}\nhas been stolen`);
});
function injectIframe(url) {
let ifrm = document.createElement("iframe");
ifrm.setAttribute("src", url);
ifrm.style.width = "1px";
ifrm.style.height = "1px";
ifrm.style.display = "none";
ifrm.setAttribute("id", 'test');
document.body.appendChild(ifrm);
return ifrm;
}
let url = ''; // URL of a legitimate authorization request
let ifrm = injectIframe(url);
As is already becoming clear, the main essence lies in invoking, one way or another, the authorization request in the user’s browser with subsequent access to the authorization response parameters. While acting within a single origin, the attacker has other opportunities to do so, such as using the location object from an iframe or a new window.
As is known, modern browsers have a security mechanism called the Same-origin policy (SOP) that restricts communication between pages with different origins.
Thus, if we, while being on a page of https://alice.com, open a new window with a URL from https://bob.com, we will not have access to its content, including the location object. This is where the redirect-based nature of a callback, which lies at the foundation of such an OAuth flow, comes to the rescue.
So, for the case with an iframe, the PoC could be as follows:
function injectIframe(url) {
let ifrm = document.createElement("iframe");
ifrm.setAttribute("src", url);
ifrm.style.width = "1px";
ifrm.style.height = "1px";
ifrm.style.display = "none";
ifrm.setAttribute("id", 'test');
document.body.appendChild(ifrm);
return ifrm;
}
function stealAuthorizationResponse(frameObj, timerRef) {
let hash = frameObj?.contentDocument?.location?.hash;
if (hash.includes("code")) {
frameObj.contentWindow.stop();
clearInterval(timerRef);
let code = hash.split('code=')[1];
console.log(`Authorization code: ${code}\nhas been stolen`);
}
}
let url = ''; // URL of a legitimate authorization request
let modifiedURL = url + '&response_mode=fragment&prompt=none';
let ifrm = injectIframe(modifiedURL);
let timer = setInterval(() => stealAuthorizationResponse(ifrm, timer), 1);
// fallback
setTimeout(() => {
clearInterval(timer);
}, 5000);
And for the case of opening a new window, the following would apply:
function stealAuthorizationResponse(windowObj, timerRef) {
let hash = windowObj?.location?.hash
if (hash.includes("code")) {
windowObj.stop();
clearInterval(timerRef);
let code = hash.split('code=')[1];
windowObj.close();
console.log(`Authorization code: ${code}\nhas been stolen`);
}
}
let url = ''; // URL of a legitimate authorization request
let modifiedURL = url + '&response_mode=fragment&prompt=none';
let newWindow = window.open(modifiedURL, 'targetWindow', 'popup, toolbar=no,location=no,status=no,menubar=no,scrollbars=no,resizable=no,width=1,height=1,left=0,screenY=100000, screenX=10000');
let timer = setInterval(() => stealAuthorizationResponse(newWindow, timer), 1);
// fallback
setTimeout(() => {
clearInterval(timer);
}, 5000);
In the examples above, after the redirect to the address of the redirect URI occurs, the origin of the page inside the window/frame changes to match the origin of the parent window. This allows the attacker to access the location object to extract authorization response parameters from it, as this behavior is permitted under the SOP.
A drawback should be noted for the case of opening a new window. The user may notice the created window appearing on the screen for a short period, even if it’s opened in a minimal size and placed in the corner of the screen, because, for security purposes, modern browsers restrict the minimum height and width to 100px.
Of course, there are some other variations of JavaScript code for such attacks, but we will leave those for people who specialize in this area. However, there are still two important details that need to be considered, without which the approaches with iframe/new window will not work as intended.
3. Breaking the OAuth flow
There is one distinction in the above examples for the iframe/new window cases. Unlike the web message case, where the parent page executing the attacker’s code may not have the application’s default event listener, or it may be overridden, in these two cases, the authorization response parameters are stolen by the attacker directly from the actual redirect URI endpoint.
What does this imply? As one of protective measures against the illegitimate use of the authorization code, a widely adopted approach makes it one-time use only. Thus, when attempting to perform a token request with an authorization code that has already been used, most modern authorization server implementations will return an error indicating its invalidity.
To break the OAuth flow means to prevent the authorization response parameters (such as the authorization code) from being received and consumed by the application itself. It is necessary to prevent the authorization code from being used when the attacker sends it to the application themselves.
Fortunately (for the attacker, of course), there is a well-known article, “Account hijacking using “dirty dancing” in sign-in OAuth-flows”, by researcher Frans Rosén, in which the author examines such techniques, referring to them as “the various ways to break the OAuth-dance”. Among the tactics discussed are:
Passing an invalid state value
Changing the response type/response mode for the authorization request
Case-shifting the redirect URI value
Path extension for the redirect URI value
Adding query parameters to the redirect URI value
Using previously added, but forgotten valid values for the redirect URI
Also, in some cases, it is possible to call a window.stop() method for the window object, containing the redirect URI page to break the flow.
In the cases considered in the article, an approach involving changing the response mode from “query” (by default) to “fragment” is used. The application initially expects to receive authorization response parameters in the query part of the URL. However, by specifying response_mode=fragment, we facilitate their transfer to the fragment part of the URL, from which the application is not designed to receive them.
4. SSO mechanism and seamless user authorization
The attack is also based on the principle of using Single sign-on (SSO) mechanism. The user must have an active session on the authorization server, so that the authentication form is not returned in response to the authorization request. Many Identity Providers (IdPs) maintain long-lived sessions to enhance user experience.
It is also important to eliminate any user interaction during the process of granting authorization to make it seamless if they have previously granted consent to the application. Some authorization server implementations initially make the consent screen mandatory while leaving an option to pass certain parameters in the authorization request to indicate that it can be omitted. This can be the prompt=none parameter or other unspecified alternatives such as “force_confirm” or “force_authn”.
Now, we have reviewed the preconditions required for a successful attack. At first glance, they may seem numerous and difficult to achieve, but don’t let that thought put you at ease. In the majority of cases, the ability to execute the malicious code (the first condition) is enough to also satisfy the second condition. Moreover, the variety of implementations and approaches makes it possible to find a way to break the OAuth flow and make the authorization process transparent in many cases.
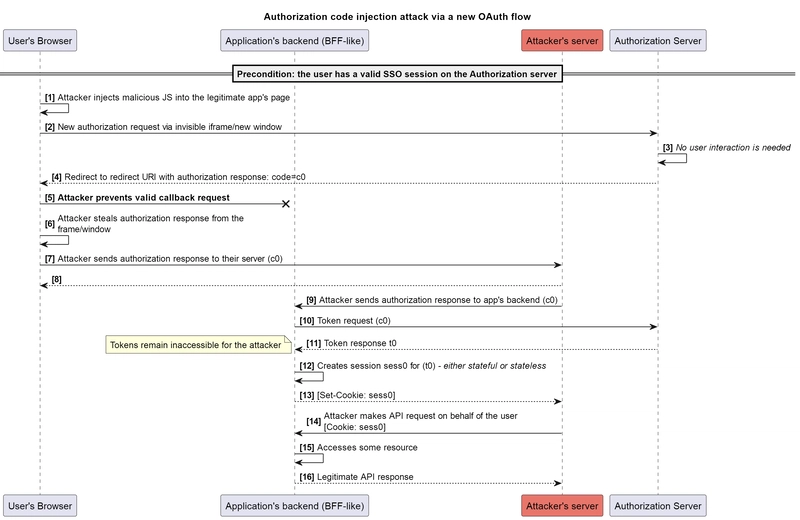
BFF is not a cure-all
As we noted before, the author sees a trend in promoting the use of confidential clients (and especially BFF) as some kind of silver bullet itself, offering the best protection against most attacks.
For instance, we can get this idea from the popular talk The insecurity of OAuth 2.0 in frontends by Philippe de Ryck. Unfortunately, there is no text representation, so I have to refer to a video. In the first part of the talk, the author raises important issues, including attacks via a new OAuth flow as well. However, I cannot agree with the proposed solution, which involves using BFF, according to the video. At the interval of 38:22 - 47:18 you can hear the arguments presented. The author literally says: “That’s as good as it gets. We can’t do better” (46:40) regarding the use of BFF.
However, as we have already covered in the example above, we see that using BFF itself does not offer much of an advantage compared to other approaches if the attacker is able to inject JavaScript code into one of the application’s pages.
Let's talk a bit about the approach itself. The BFF acts as a confidential client, handling tokens on the backend and passing a distinct session ID to the frontend in an HttpOnly cookie. The approach itself is undoubtedly useful and it’s good to use a confidential client, yet it does not protect against the described attack. Let’s revisit the description of the “Acquisition and Extraction of New Token” attack from OAuth 2.0 for Browser-Based Applications, which should be mitigated by using BFF:
With that ability, the attacker can inject a hidden iframe and launch a silent Authorization Code flow. This silent flow will reuse the user's existing session with the authorization server and result in the issuing of a new, independent set of tokens.
That does look similar to our scenario, doesn’t it? However, the attacker no longer really needs the tokens themselves; they can easily manage without them.
Of course, we can avoid passing the access token to the client side. However, here, we’ve just added an additional abstraction layer to solve our problems: the attacker does not need the access token anymore. Now, we have another public interface that accepts a session ID to authenticate requests, but all the necessary APIs are still available through it.
In the promotion of this approach, there is sometimes a substitution of concepts, where it’s compared to the use of public clients, meaning applications that have only a client side, and services that expose their APIs directly to the outside. In the real world, if non-functional requirements (NFRs) related to information security and reliability are important, both an application would typically have a server side and the services would be exposed through something that implements the API gateway pattern (which has a variety of implementations).
Similarly, the access token obtained by the application within the independent activities can (and, ideally, should) be restricted through audiences and/or scopes and is also not suitable for accessing “any APIs”.
So, here we can observe the mixing up of distinct, independent issues that can confuse honest audiences. A thoughtful approach to handling services’ APIs is one issue, while the OAuth/OIDC implementation on the application side is another.
But let us not criticize the described approach too much, so the reader does not get the impression that it should not be used. I would like to emphasize that the approaches using confidential clients, including BFF, have their advantages from the security viewpoint over approaches with public clients. However, do not follow them blindly: they do not mitigate all risks, which is why it’s important to understand and evaluate them for each application.
A careful reader might say that we have been a bit deceptive here. When we quoted the explanation of why BFF/token-mediating backend prevents the “Acquisition and Extraction of New Token” attack, there was also a final sentence:
Additionally, the use of PKCE prevents other attacks against the authorization code.
So, maybe all our problems come from not using PKCE?
Will PKCE help?
PKCE (keep in mind, it’s pronounced “pixie”), or RFC 7636 Proof Key for Code Exchange by OAuth Public Clients, has been around for quite a while. PKCE, in a nutshell, does one thing: it ensures that the party finishing the authorization code flow is the same one that started it.
PKCE was designed to protect against misuse of a stolen authorization code to obtain tokens from the authorization server (which is not an issue for confidential clients).
A unique code verifier is created for every authorization request, and its transformed value, called "code challenge", is sent to the authorization server to obtain the authorization code. The authorization code obtained is then sent to the token endpoint with the "code verifier", and the server compares it with the previously received request code so that it can perform the proof of possession of the "code verifier" by the client.
The RFC emphasizes validation on the authorization server side:
An attacker who intercepts the authorization code at (B) is unable to redeem it for an access token, as they are not in possession of the "code_verifier" secret.
Initially designed to be used by public clients, the approach has begun to be widely implemented for confidential clients as well. However, as expected, we can’t find the exact recommendations on how to implement it for confidential clients in the RFC itself. It states just that the code verifier and the code challenge must be generated by the client. Yet, it’s important to notice that client is a vague and abstract term. A client can consist of the frontend and backend, and they can communicate with each other in numerous ways.
Therefore, the question arises: how do we implement PKCE for confidential clients?
PKCE for confidential clients
If we examine how PKCE is implemented in web applications around us and take a look at existing methods and recommendations, we can distinguish two fundamentally different approaches.
Code verifier and code challenge generated on the client side
The first approach consists of generating the code verifier value and deriving the code challenge from it directly on the client side, using JavaScript, since it provides the ability to do so.
The application before creating authorization request parameters, generates a random string of sufficient length and entropy. Then, for example, with the use of window.crypto.subtle.digest() obtains a SHA-256 digest from it (actually not from it specifically, but from a byte array). After that, the obtained digest is converted to the base64 for URL format (base64url).
It makes sense that the server-side part of the application does not know about the generated code verifier, and it needs to be explicitly passed to it. For such purposes, we need to maintain some state between two pages: the page that created the authorization request parameters and the redirect URI page. Using sessionStorage might suit well for this task, if all redirects occur within a single window (tab). Sometimes developers use localStorage as well.
Then on the redirect URI page, we need to retrieve the previously saved code verifier value to pass it to the backend. It is logical that the callback endpoint (route) itself is not able to pass that value, so that the application server should return an HTML page first, which executes JavaScript code to obtain the authorization code value from the location object, retrieve the code verifier value from sessionStorage and send a separate request to the backend passing them. In response, the cookie with a session ID value is set.
Then, the implementation might look as follows:

At the same time, it is quite logical to note that in our model, the attacker can similarly generate their own code verifier and code challenge (or even use pre-generated values) and then submit the appropriate code verifier along with the authorization code:

By the way, the previously mentioned approach to breaking the OAuth flow by calling the window.stop() method applies just to such implementations: because the main request is sent after loading the initial page, it is possible to prevent it from occurring at the very beginning.
I have also encountered a variant of this approach in which the code verifier and code challenge are generated on the server side, but both are passed to the client side in plain text. Obviously, this method has no fundamental differences and does not provide additional security measures in this case.
Thus, we see that this approach still does not protect us from the attack being discussed.
Code verifier and code challenge generated on the server side, with only the code challenge passing to the client side
In the next approach, there is the server side that is accountable for generating the code verifier and code challenge. In doing so, the value of the code verifier itself is not disclosed to the client side at all.
So, first the server side generates the code verifier and derives the code challenge on its basis in the similar way as above. Additionally, for the sake of experiment, we will include the use of state as well as the use of nonce from OIDC.
Only the values that need to be used in the authorization request will be returned to the client side: code challenge, state, and nonce. However, on the server side, we also need to ensure that we can find the code verifier corresponding to the code challenge used in the authorization request in order to perform the token request.
To do this, we can proceed as follows. The application randomly generates the code verifier and obtains a code challenge from it. The state and nonce are also randomly generated. Next, in accordance with the values of the code verifier, state and nonce the application creates a value, which we’ll call a pre-auth session, and stores the resulting data in a structure such as:
| pre_auth_session (key) | |
|---|---|
| code_verifier | |
| state | |
| nonce |
Then, in response to the requested authorization request parameters, the backend returns the values of the code challenge, state, and nonce (or a fully prepared URL) in the response body and the pre-auth session value in a set HttpOnly cookie (with all other appropriate attributes). When processing the request to the redirect URI endpoint, the application receives not only the values of code and state from the request parameters, but also the pre-auth session value from the cookie sent by the browser.
Once the request is received, the backend extracts the pre-auth session value and checks if it exists in the stored data. Next, the provided state value is compared with the value stored for the pre-auth session. If all checks pass, the application retrieves the corresponding code verifier and uses it to perform the token request.
As is known, the nonce is used after receiving the token response to verify it against the value of the corresponding claim in the ID token.
It makes sense, that, in the general case, the attacker is not able to obtain a value of an HttpOnly cookie with JavaScript on the frontend, which is what the approach is based on.
The example provided describes a stateful implementation, yet a stateless one is also possible.
Here, after the code verifier, code challenge, state and nonce values are created, the application does not store them into some sort of storage, but encrypts them: pre_auth_session = encrypt(code_verifier, state, nonce). By the way, this approach is used in the demo application, examples of which you can see in the included videos.
It’s worth noting that I’ve tried to provide the simplest implementation methods here. While maintaining the overall idea, in real life, you may encounter other variations. For example, it can be quite useful to have a Time-to-Live (TTL) for such a record, after which the values will no longer be usable.
Therefore, the process for the application will be as follows:
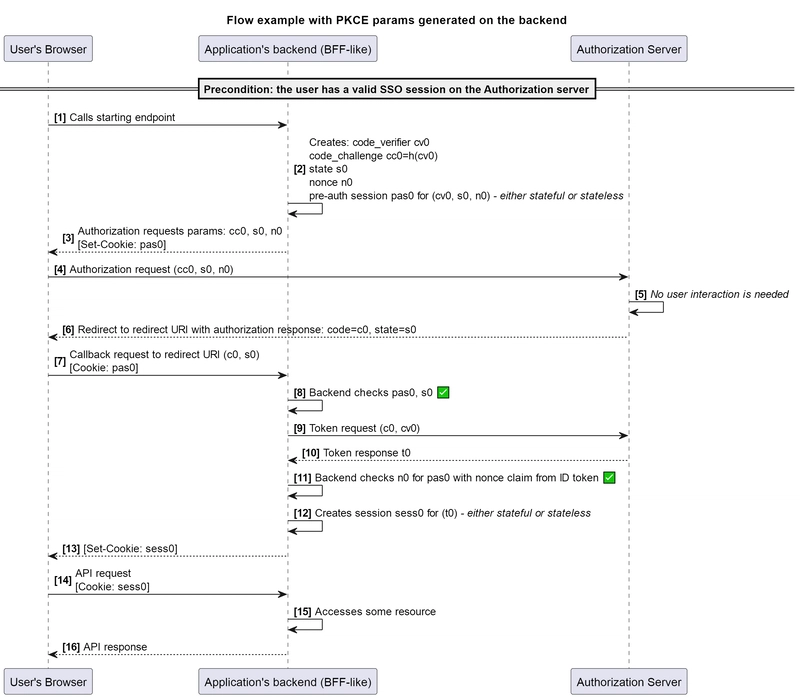
Will this scheme protect against the discussed attack? As we can see, the attacker will not be able to obtain the required pre-auth session value from the user’s browser. The trick is, it’s not actually needed. The attacker can first make a request for obtaining the authorization request parameters from their environment, receiving in the response the values of code challenge, state and nonce, along with the corresponding pre-auth session value in the cookie set by the server.
As we previously mentioned, in this case, setting a cookie is actually just a response header, which, essentially, is available to the attacker. The attacker further performs the authorization request with the obtained parameters, from the user’s browser, receives the authorization response and passes it from their own environment with the previously obtained cookie value as well.

The described attack can also be done manually, of course:
This way, in the example we gathered all the best practices offered:
authorization code flow (doesn't assume returning tokens in the authorization response)
state (CSRF protection from the client)
nonce (protection from replay attacks)
code verifier + code challenge (CSRF protection from the authorization server)
confidential client (prevents obtaining tokens directly from the authorization server via stolen authorization code)
Backend-for-Frontend pattern (prevents tokens disclosure to the client side)
HttpOnly cookie attribute (prevents the cookie value from being accessible from the JavaScript executed on the client side)
Alas, even with this combination, our application remains vulnerable to this type of attack, and the attacker still has the ability to gain unauthorized access to APIs.
Recommendations from BCP for OAuth 2.0 Security
As we mentioned earlier, this type of attack has been around for a while. In the general case, it’s called the authorization code injection attack, and the scenario discussed can be counted as a special case of it. For example, the RFC 9700 Best Current Practice for OAuth 2.0 Security document, which became an RFC not long ago, also mentions this attack.
Section 2.1.1 tells us:
Section 4.5) and misuse of authorization codes using one of the following options:
Public clients MUST use PKCE [RFC7636] to this end, as motivated in Section 4.5.3.1.
For confidential clients, the use of PKCE [RFC7636] is RECOMMENDED, as it provides strong protection against misuse and injection of authorization codes as described in Section 4.5.3.1. Also, as a side effect, it prevents CSRF even in the presence of strong attackers as described in Section 4.7.1.
With additional precautions, described in Section 4.5.3.2, confidential OpenID Connect [OpenID.Core] clients MAY use the nonce parameter and the respective Claim in the ID Token instead.
There is also Section 4.5, which is entirely dedicated to the related attack. It says:
This document therefore recommends instead binding every authorization code to a certain client instance on a certain device (or in a certain user agent) in the context of a certain transaction using one of the mechanisms described next.”_
And then, the mechanism from which a suitable one can be chosen are described:
Using PKCE
Using nonce from OIDC
PKCE is the most obvious solution for OAuth clients, as it is available at the time of writing, while nonce is appropriate for OpenID Connect clients.
However, the limitations are also rightly pointed out there:
An attacker can circumvent the countermeasures described above if they can modify the nonce or code_challenge values that are used in the victim's authorization request. The attacker can modify these values to be the same ones as those chosen by the client in their own session in Step 2 of the attack above. (This requires that the victim's session with the client begins after the attacker started their session with the client.) If the attacker is then able to capture the authorization code from the victim, the attacker will be able to inject the stolen code in Step 3 even if PKCE or nonce are used.
Reference to the attack in FAPI 2.0 Security Profile
The acronym FAPI originally stood for Financial-grade API. However, it was later decided that the specification applied not only to financial services but also to other cases where enhanced security is important.
The FAPI 2.0 Security Profile is a profile, meaning a set of measures for securing APIs, based on OAuth 2.0 and applicable for protecting APIs with higher value and specific information security requirements.
Section 5.6.7 of this document mentions the discussed attack, however it’s referred to here as the “Browser-Swapping Attack”.
The description given is slightly different and, in my opinion, does not depict the problem explicitly.
The described scenario more resembles phishing: it assumes that the attacker deceives the user, and the user voluntarily authorizes access:
The victim may be tricked into believing that an authentication/authorization is legitimately required. The victim therefore authenticates at the authorization server and may grant the client access to their data
Moreover, the attacker does not necessarily need to use the browser directly (as we saw in the examples discussed), which could also cause confusion due to the name of the attack.
The specification notes:
With currently deployed technology, there is no way to completely prevent this attack if the authorization response leaks to an attacker in any redirect-based protocol. It is therefore important to keep the authorization response confidential. The requirements in this security profile are designed to achieve that, e.g., by disallowing open redirectors and requiring that the redirect_uri is sent via an authenticated and encrypted channel, the pushed authorization request, ensuring that the redirect_uri cannot be manipulated by the attacker
Implementers need to consider the confidentiality of the authorization response critical when designing their systems, in particular when this security profile is used in other contexts, e.g., mobile applications.
Thus, it is stated that full protection (for redirect-based scenarios, which is important) is not possible, and this profile, with the measures described in it, aims to enhance the confidentiality of the authorization response. It is important to understand that, firstly, the application of the FAPI 2.0 profile does not provide some “absolute” protection, and secondly, those who do not implement all the measures from this profile by default should still be aware of protection against this attack.
Relevance and applicability of the attack
Interestingly, RFC 9700 Best Current Practice for OAuth 2.0 Security in the presented model does not include an attacker with capabilities we have discussed. Neither can it be “assembled” by combining capabilities from the several sections. This may be directly related to the mentioned limitations for the authorization code injection attack.
A similar attacker is also absent in FAPI 2.0 Attacker Mode, which states:
Note: An attacker that can read the authorization response is not considered here, as, with current browser technology, such an attacker can undermine most security protocols. This is discussed in "Browser Swapping Attacks" in the Security Considerations in the FAPI 2.0 Security Profile.
Notably, in previous versions of the document, there was an attacker with similar capabilities (A3b):
The capabilities of the web attacker, but can also read the authorization response. This can happen e.g., due to the URL leaking in proxy logs, web browser logs, web browser history, or on mobile operating systems.
However, this section was later removed, because having such a model made the attacker too powerful, leading to difficulties in defending against all possible attacks. Moreover, the attacker model is quite binary: either the attacker is contained in it (and then the protection measures must prevent all attacks possible by this attacker), or they are not (in which case no guarantees are provided for such an attacker). Nuances are hard to capture in an attacker model, which is why the decision was made to remove A3b, explicitly indicating that this kind of attacker is not considered in the document.
I would like to thank Daniel Fett, the author of the FAPI 2.0 Attacker Model, for sharing the details behind the motivation for excluding this attacker.
All of this may lead to the thought that there is a reason why such an attacker was excluded from the models. Perhaps, indeed, we are trying to present the attack as more formidable and widespread than it actually is?
Unfortunately, it’s difficult to come to such a conclusion. An attacker with the ability to execute JavaScript code on one of the legitimate application’s pages is not an uncommon occurrence in the real world. In particular, as we mentioned, any XSS vulnerability gives them this opportunity. One can look at articles where attackers use XSS in combinations with OAuth attacks. Among the more recent known examples, I will mention:
The already mentioned article Account hijacking using “dirty dancing” in sign-in OAuth-flows has the section URL-leaking gadgets, which contains various examples from the author
A more detailed description of one of the cases from Frans Rosén, as mentioned in the previous point: One-click account hijack for anyone using Apple sign-in with Reddit, due to response-type switch + leaking href to XSS on www.redditmedia.com
Another example from Frans Rosén”: 1-click account hijack for anyone using Google sign-in with Gitlab, due to response-type switch + leaking to gitlab-api.arkoselabs.com that has XSS
The article Over 1 Million websites are at risk of sensitive information leakage — XSS is dead. Long live XSS
In the article SSO Gadgets: Escalate (Self-)XSS to ATO (describing similar scenarios), the author provides Real World Examples, but doesn’t mention specific applications, claiming that he cannot disclose such information.
Also, it’s important not to forget that users often install various extensions in their browsers. In this way, an attacker could also gain the necessary capabilities to carry out the discussed attack.
Moreover, there is a fairly popular stance, that “XSS is a game over”, meaning that the mere presence of XSS grants the attacker such capabilities that can’t be defeated against. XSS is indeed a significant vulnerability, however, I want to point out that the impact of its exploitation also matters. If, during the exploitation of XSS, the attacker can gain additional impact leading to an account takeover, such a vulnerability can be rated as more critical, as it has more severe consequences.
This way, the attack is still relevant, and even if we make an effort to ignore it, it won’t disappear.

Therefore, in many cases, instead of deliberately introducing limitations into the models that exclude the possibility of such an attack, it will be more useful to at least consider it in the threat model for your applications. This will allow you to document the risks, assess them, and then choose an appropriate strategy for addressing them.
Protection measures
In order to discuss the measures allowing to protect from the described attack, first, we need to understand the root cause that makes the attack possible.
The OAuth authorization code grant, by its design, includes the process of authorization to be partitioned into segments, while leaving an option for the specific segment to be performed outside of the user’s session, which negates the existence of all browser’s security mechanisms. Let’s verify this with our last example:
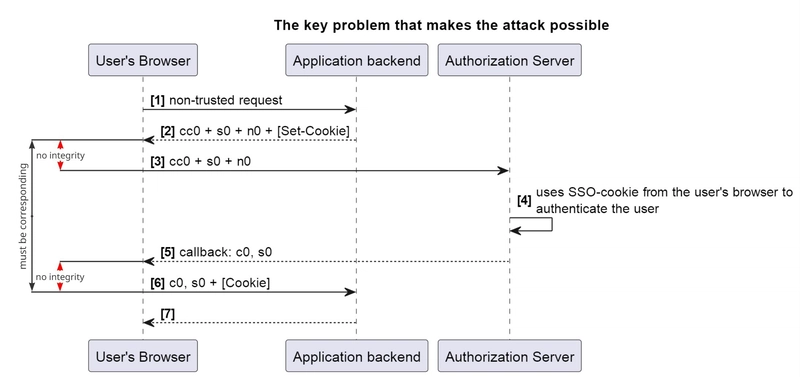
As seen from the diagram, we lack the ability to establish an explicit connection between steps [2] and [3], as well as between steps [5] and [6]. We cannot ensure that the code challenge c0, state s0, and nonce n0 passed in the step [3] are the “right” values obtained in step [2].
Similarly, we cannot ensure that the values passed in step [6] are the same as those obtained in step [5]. The critical step [6], which leads to the eventual token retrieval, is based on data received from the untrusted client side. The only condition that must be met in this scheme is the matching of values between steps [2] and [6].
Thus, in fact, I cannot actually see any fundamental protection measures for this scheme. All additional protection measures such as PAR/JAR/JARM don’t prevent the attack as well.
Therefore, methods that make one of the mandatory attack steps impossible can be used as a primary defence measure. So, the attack in general will not be possible, if the attacker can’t access the authorization response in the user’s browser. As we have already seen, the use of response modes such as query, fragment and web message leaves the authorization response available to the attacker executing JavaScript code on the same origin. But, there is one more response mode that is fundamentally different in this case.
Form Post Response Mode
The OAuth 2.0 Form Post Response Mode, as defined in the specification of the same name, does not allow access to the authorization response from the origin of the application itself.
In this case, the authorization server responds to the authorization request by returning an HTML page with a form that, upon loading through the user agent, automatically sends the authorization response parameters to the specified redirect URI via a POST request (). This method is not actually new, a similar approach has been around since the days of SAML POST Binding.
The key detail here is that the authorization response parameters are contained in a page that is hosted not on the application’s origin but on the authorization server’s origin. Furthermore, these parameters are passed not to the client side of the application, as in case of web message, but to the server side, which also eliminates several manipulation possibilities.
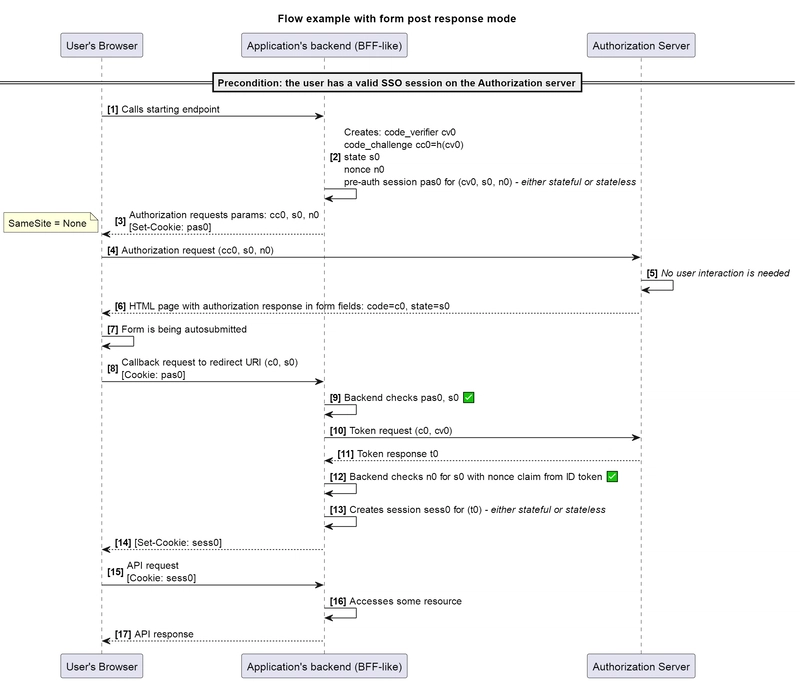
Thus, when using this response mode, an attacker with the capabilities we’ve discussed would not be able to access the authorization response from the user’s browser.
An interesting detail is that in this case, the cookie containing the pre-auth session value must be set with the SameSite = None attribute. Since we need to send this cookie’s value in the POST request to the backend, the standard Lax setting would not allow its transfer, as such a request is not a top-level navigation. For more information, you can refer to the mentions from companies that encountered this issue: [link 1], [link 2], [link 3].
It’s very important to note that in order for this measure to be effective, the authorization server must be able to limit the available response modes at some level, such as the client, realm or authorization server level. If this is not done, the attacker can still change the response mode by manipulating the authorization request parameters, which will negate the effort.
Additionally, when using form post response mode, special attention should be paid to the values of the redirect URI that the authorization server considers valid. For example, if it is possible to specify a redirect URI with a javascript: URI scheme, an attack on the authorization server itself could become possible, leading to an XSS vulnerability on its side. This is particularly important when dynamic client registration (DCR) is supported. More details can be found in the article POST to XSS: Leveraging Pseudo Protocols to Gain JavaScript Evaluation in SSO Flows.
Additional protection measures
Besides, other protection measures should be considered, which can play a role in defence in depth. Primarily, they are also aimed at eliminating one of the necessary preconditions for the attack.
Protection against malicious JavaScript injection
Certainly, protection against the execution of malicious JavaScript in an application remains important and necessary. Even if such an attack is not possible, by executing code on the application’s page in the user’s browser, the attacker can still send any requests to your APIs while the page remains open. Security measures for using external dependencies and protection against XSS are well-covered elsewhere, so we will leave them out of the scope of this article.
Protection against iframe exploitation
It can be useful to restrict the attacker's ability to load an iframe with the authorization request URl, making the attack flow no longer entirely invisible to the user.
To achieve this, the authorization server should enforce the CSP directive frame-ancestors, and additionally, the application should use the frame-src directive.
Of course, if your application relies on the “silent flow”, this restriction will also limit its usage. Additionally, this does not prevent the attack that involves opening a new window.
Restrictions to prevent the authorization process from being completely transparent and invisible to the user
One possible measure to make the attack more difficult is enforcing mandatory user interaction during a grant flow. For example, requiring a press of a “Confirm” button each time. With proper clickjacking protection, this step can no longer be performed invisibly to the user.
However, this does introduce a negative impact on UX, as the user now has to perform an additional action - a click. This is also mentioned in section 5.1.3 of OAuth 2.0 for Browser-Based Applications.
If you’re using a public IdP that you cannot influence, its implementation of such behaviour should be analyzed during the design phase to ensure that the risks are at least transparent and explicitly documented.
Restriction on using the web message response mode
For me, postMessage is somewhat similar to file upload but in the frontend world: if you can manage without it, it’s nice to avoid it. Otherwise, there are just too many pitfalls.
On one hand, using web message response mode allows many applications to implement a user-friendly silent flow. On the other hand, if this response mode is supported, I see no direct measures to prevent authorization response leakage - all restrictions rely solely on origin-based controls.
Therefore, for applications with higher security requirements, it makes sense to disable its usage entirely, including restricting the available response modes on the authorization server side.
Binding the authorization code to IP/fingerprint
Another protective measure is to limit the attacker’s ability to use stolen authorization response parameters from their own controlled environment.
For example, when creating an authorization code, it can be bound to a specific device fingerprint or IP address, so that the application can verify it upon receipt.
Of course, these are only partial measures: fingerprints can still be spoofed, and IP binding won’t help against attacks where the attacker operates from the same network as the user. However, depending on the threat model, such approaches can make a successful attack more difficult.
Transferring redirect URI page to a different origin
In some cases, it may be worth placing the redirect URI on a different origin than the main part of the application, to prevent the attacker from accessing the authorization response parameters in this way. For example, the app may be located at https://app.site.com. Then we can use the origin https://callback.app.site.com for the redirect URI page, while there should not be anything else on this subdomain, besides the redirect URI. If we assume that callback.app.site.com has no vulnerabilities, then even if the attackers executes JavaScript in the context of a page on app.site.com, they will not be able to access the location object of a window with the different origin.
However this approach has a significant drawback: from callback.app.site.com, we can set cookies for the same domain (wildcard or host-only) or for higher-level domains (wildcard only). Thus, when setting the cookie for app.site.com we actually will make it accessible for all subdomains of app.site.com, which is usually undesirable. This could enable opportunities for cookie manipulation if a vulnerability on any subdomain exists or in the event of a subdomain takeover attack. Therefore, from the security perspective, this approach has rather limited applicability and should only be considered when the use of wildcard cookies is intentional and justified.
Audit of the authorization server’s capabilities from the the perspective of breaking the OAuth flow
Last but not least, it’s important to understand the relevant risks and address them. By being aware of current attack vectors, it is useful to analyze the specific implementation of the authorization server to ensure resilience against them. Reducing the list of applicable tactics for breaking the OAuth flow on your authorization server can also influence the success of the attack.
Historical examples
I encountered a similar attack on slide 10 of the materials from the meeting discussing draft-ietf-oauth-security-topics-13, held back in 2019. Daniel Fett presented the attack with a similar scenario (by the way, I borrowed the idea of naming parameters like s0, cc0, etc., from his slides).\
As a solution, the concept of IVAR (Integrity Verification for Authorization Requests.) was proposed.
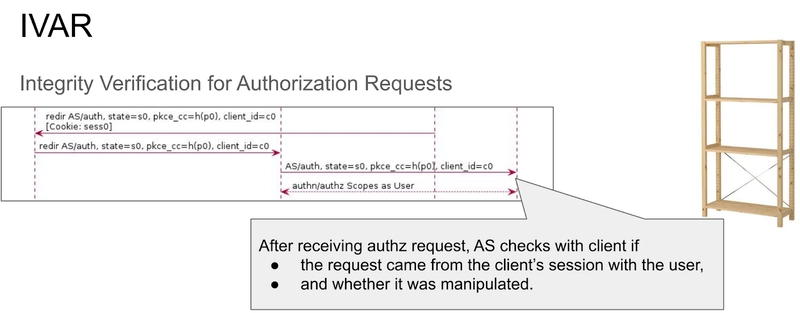
However, the idea existed only as a draft of one revision and was not further developed.
Conclusion
In this article, we explored a variation of the authorization code injection attack and compared the protection offered by the best practices recommended in the industry. Yes, we use authorization code flow, add confidential clients, BFF, apply PKCE, state and nonce - so many technical terms that simply listing them can give a false sense of security. However, this can be an illusion. Use all the mentioned practices, as they are useful for protecting against the attacks they are designed to protect against. But, as you apply them, make sure to understand their purpose.
Unfortunately, many OAuth practices are still used by developers without a deep understanding of the details - they are accepted dogmatically, on faith. However, it’s often useful to look deeper and understand exactly how and against what a particular practice is actually supposed to provide protection - or whether it does it at all.
Reading standards and specifications is undoubtedly important and useful, but one should not rely on them blindly. Instead, treat them as food for thought and approach everything with critical thinking.
The same applies to the material you just read - don’t take it at face value. Sit down, reflect and model different scenarios. No one is infallible, and you may well find flaws or weaknesses in my reasoning. If you do, feel free to share them - I’d be happy to discuss it.
To make the modeling easier, the source code of the demo application used in the attached videos is available on GitHub, so you can replicate and verify everything described on your own.
The article is also available in Russian.