

















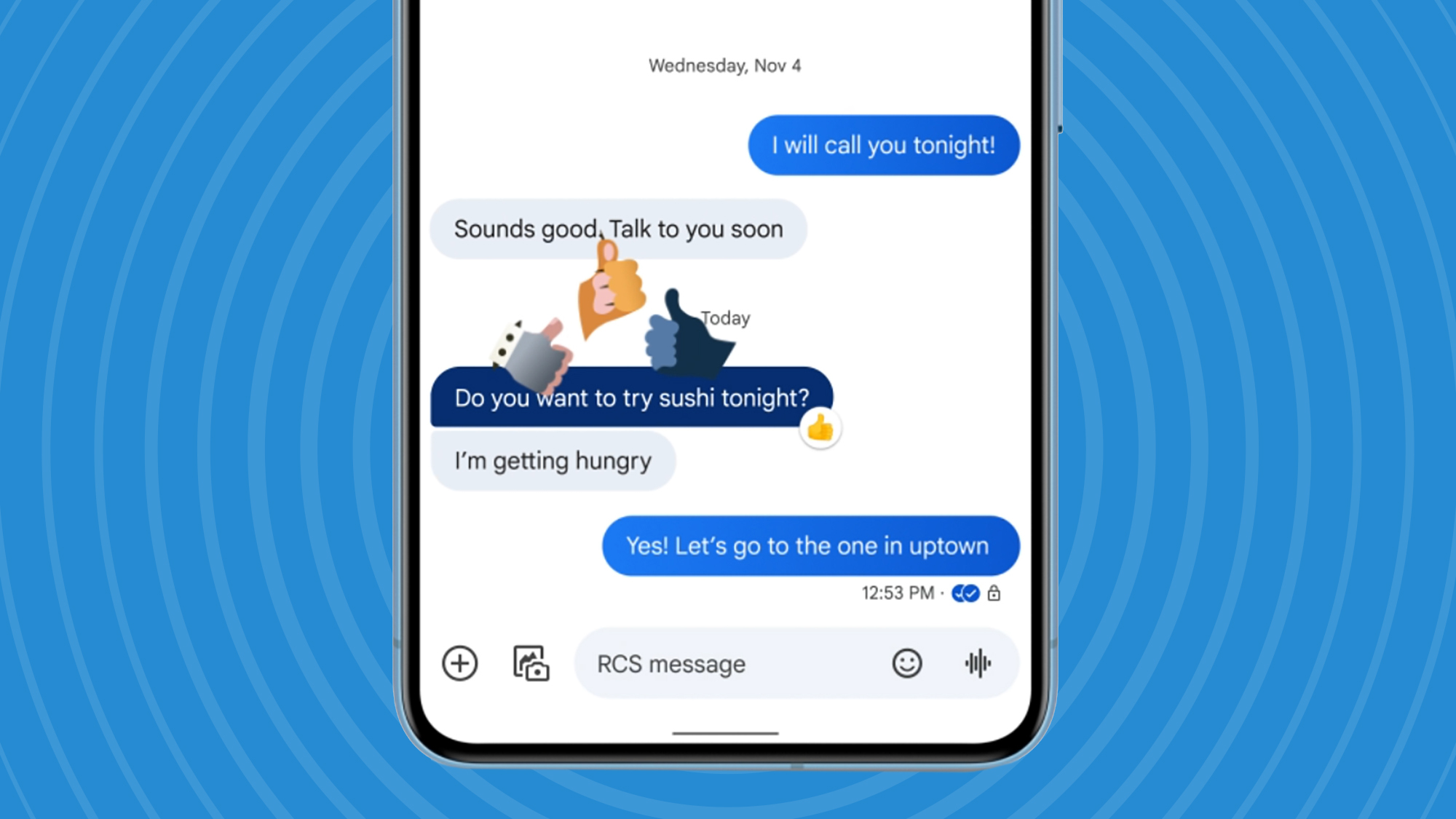


































-Reviewer-Photo-SOURCE-Julian-Chokkattu-(no-border).jpg)





















































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)

































































































































![Life in Startup Pivot Hell with Ex-Microsoft Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)




























































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)


















































-Nintendo-Switch-2-Hands-On-Preview-Mario-Kart-World-Impressions-&-More!-00-10-30.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

























_Andrey_Khokhlov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


_Aleksey_Funtap_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





















































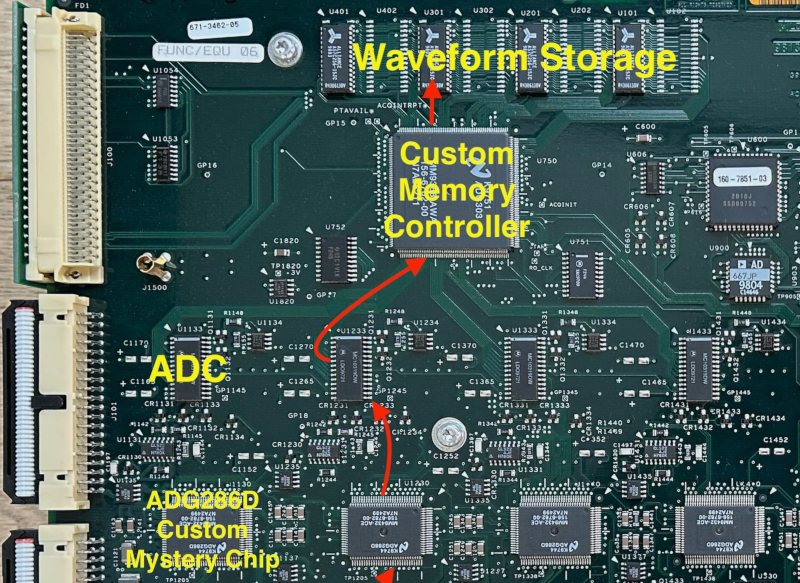





















































![Apple Foldable iPhone to Feature New Display Tech, 19% Thinner Panel [Rumor]](https://www.iclarified.com/images/news/97271/97271/97271-640.jpg)
![Apple Developing New Chips for Smart Glasses, Macs, AI Servers [Report]](https://www.iclarified.com/images/news/97269/97269/97269-640.jpg)
![Apple Shares New Mother's Day Ad: 'A Gift for Mom' [Video]](https://www.iclarified.com/images/news/97267/97267/97267-640.jpg)

































































![[Weekly funding roundup May 3-9] VC inflow into Indian startups touches new high](https://images.yourstory.com/cs/2/220356402d6d11e9aa979329348d4c3e/WeeklyFundingRoundupNewLogo1-1739546168054.jpg)


























Top P Sampling Explained: Smarter Text Generation with AI
If you’ve played around with language models or text generation before, you’ve probably seen the term “Top P” sampling—also called nucleus sampling—pop up. It’s one of those AI concepts that sounds a little mathy at first, but once you get it, it feels obvious. Why Sampling Matters in Language Models When a language model like GPT generates text, it's not just making random guesses. It’s predicting the next word (or token) based on probabilities. For example, after the phrase “The cat sat on the”, it might think: “mat” has a 60% chance “sofa” has a 25% chance “roof” has a 10% chance …and a bunch of others with tiny chances. The question is: how do we decide which token to actually pick? That’s where sampling strategies come in. What is Top P Sampling? Top P sampling offers a clever twist. Instead of blindly picking the top K tokens (like in Top K sampling), Top P picks a variable number of top tokens whose cumulative probability adds up to a chosen threshold, P. Let’s say you set P = 0.9. The model will look at all possible tokens and select the smallest set of tokens whose total probability adds up to 90%. It then randomly picks from that set. This means: More flexibility Fewer weird or low-probability words A better balance between coherence and creativity Top P vs. Top K: What’s the Difference? Feature Top K Sampling Top P (Nucleus) Sampling Fixed token count Yes (always picks top K) No (depends on token probabilities) Adaptability Manual tuning needed Automatically adapts Diversity Medium High (but still coherent) Risk of weird outputs Higher at high K values Lower (cuts off low-probability tokens) Adjusting the P Value: How Much Diversity Do You Want? The magic number people often use in practice is P = 0.9. But here’s what happens when you tweak it: Lower P (e.g., 0.7) More focused, predictable, and safe Might get repetitive or boring Higher P (e.g., 0.95–0.98) More creative, diverse, and unexpected May drift into off-topic or less coherent text It would be better to test different values for your use case. A chatbot might need lower P for consistent answers, while a poem generator could thrive with higher P. Preventing Out-of-Vocabulary Tokens Another unsung benefit: Top P sampling helps avoid out-of-vocabulary (OOV) tokens—basically, weird or nonsensical gibberish words. Since we’re selecting only the top-probability tokens that add up to P, extremely rare and low-quality tokens are left out. That’s good news if you’re building something people will read. Wrapping up Whether you're a developer building an AI assistant or a creative coder experimenting with story generation, Top P gives you the power to dial in the right mix of quality and creativity. It’s like adjusting the spice level in your food—just enough to taste exciting, but not enough to ruin the dish. So next time you’re configuring your model's generation settings, don’t overlook this humble parameter. It could be the difference between “meh” and “wow!” If you're a software developer who enjoys exploring different technologies and techniques like this one, check out LiveAPI. It’s a super-convenient tool that lets you generate interactive API docs instantly. So, if you’re working with a codebase that lacks documentation, just use LiveAPI to generate it and save time! You can instantly try it out here!

If you’ve played around with language models or text generation before, you’ve probably seen the term “Top P” sampling—also called nucleus sampling—pop up. It’s one of those AI concepts that sounds a little mathy at first, but once you get it, it feels obvious.
Why Sampling Matters in Language Models
When a language model like GPT generates text, it's not just making random guesses. It’s predicting the next word (or token) based on probabilities. For example, after the phrase “The cat sat on the”, it might think:
- “mat” has a 60% chance
- “sofa” has a 25% chance
- “roof” has a 10% chance
- …and a bunch of others with tiny chances.
The question is: how do we decide which token to actually pick? That’s where sampling strategies come in.
What is Top P Sampling?
Top P sampling offers a clever twist.
Instead of blindly picking the top K tokens (like in Top K sampling), Top P picks a variable number of top tokens whose cumulative probability adds up to a chosen threshold, P.
Let’s say you set P = 0.9. The model will look at all possible tokens and select the smallest set of tokens whose total probability adds up to 90%. It then randomly picks from that set.
This means:
- More flexibility
- Fewer weird or low-probability words
- A better balance between coherence and creativity
Top P vs. Top K: What’s the Difference?
| Feature | Top K Sampling | Top P (Nucleus) Sampling |
|---|---|---|
| Fixed token count | Yes (always picks top K) | No (depends on token probabilities) |
| Adaptability | Manual tuning needed | Automatically adapts |
| Diversity | Medium | High (but still coherent) |
| Risk of weird outputs | Higher at high K values | Lower (cuts off low-probability tokens) |
Adjusting the P Value: How Much Diversity Do You Want?
The magic number people often use in practice is P = 0.9. But here’s what happens when you tweak it:
Lower P (e.g., 0.7)
More focused, predictable, and safe
Might get repetitive or boringHigher P (e.g., 0.95–0.98)
More creative, diverse, and unexpected
May drift into off-topic or less coherent text
It would be better to test different values for your use case. A chatbot might need lower P for consistent answers, while a poem generator could thrive with higher P.
Preventing Out-of-Vocabulary Tokens
Another unsung benefit: Top P sampling helps avoid out-of-vocabulary (OOV) tokens—basically, weird or nonsensical gibberish words. Since we’re selecting only the top-probability tokens that add up to P, extremely rare and low-quality tokens are left out.
That’s good news if you’re building something people will read.
Wrapping up
Whether you're a developer building an AI assistant or a creative coder experimenting with story generation, Top P gives you the power to dial in the right mix of quality and creativity. It’s like adjusting the spice level in your food—just enough to taste exciting, but not enough to ruin the dish.
So next time you’re configuring your model's generation settings, don’t overlook this humble parameter. It could be the difference between “meh” and “wow!”
If you're a software developer who enjoys exploring different technologies and techniques like this one, check out LiveAPI. It’s a super-convenient tool that lets you generate interactive API docs instantly.
So, if you’re working with a codebase that lacks documentation, just use LiveAPI to generate it and save time!
You can instantly try it out here!


