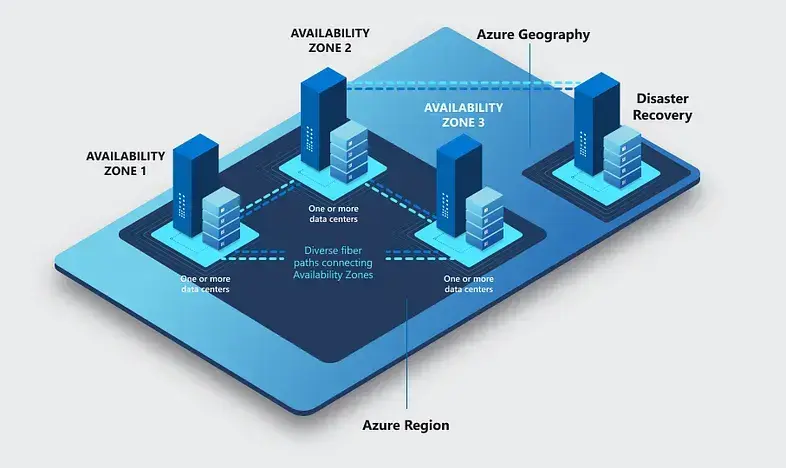










































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)
































































































































![Ditching a Microsoft Job to Enter Startup Hell with Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)



























































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)



















































-Nintendo-Switch-2-Hands-On-Preview-Mario-Kart-World-Impressions-&-More!-00-10-30.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)









































































































-xl.jpg)



























![New iPad 11 (A16) On Sale for Just $277.78! [Lowest Price Ever]](https://www.iclarified.com/images/news/97273/97273/97273-640.jpg)

![Apple Foldable iPhone to Feature New Display Tech, 19% Thinner Panel [Rumor]](https://www.iclarified.com/images/news/97271/97271/97271-640.jpg)




























































































Time and Truth: Lessons from Tracking My Work with Watson
I started using Watson with low expectations. Two and a half years later, it is still one of the few tools I have not quit. And it taught me a little bit about how I really spend my time. I have been using Watson since -- well, let me check: $ watson log --all | head -n1 | awk '{printf "%s %s, %s\n", $2, $3, $4}' 31 October, 2022 It is a small, Python-based command-line tool to track time and report how much time you spent on each project for a given period. It supports tags, so you have a bit of flexibility in how you want to categorize your time. It keeps the data in a flat, very simple JSON file, so you can easily back it up or even edit it by hand if you need to. Unfortunately, that is all it does. Projects and tags are good, but being able to take notes would be a great addition. This led me sometimes to use long, verbose tags for simple notes. To be honest, I never looked at those tags again. I knew that the project was not actively maintained. There are no bugs I know of, and there are no new releases since May 2022: That is three years now. Actually, when I was writing this blog post, I found out that the GitHub repository was moved under Jazzband, a community that saves and survives Python projects. When I started using it, I was skeptical. I thought that I would use it for a few days and then forget about it. But I managed to stick with it until now. I checked alternatives from time to time, but I never found anything that I liked significantly more than Watson. In fact, I even wrote blog posts (1, 2, 3) to show how to work on Watson data using Haskell. Here are my three takeaways after using Watson for about 2.5 years: Tracking time is a good habit. It will not necessarily make you productive, but it will help you understand where you spend your time. I knew that I was tinkering a lot, but I did not know the extent of it. Likewise, all the sysadmin and devops activities I did were much more than I expected. The first immediate benefit in my case was that I stopped lying to myself. Then, I slowly started changing my daily and weekly routines to compartmentalize tinkering and chores. Secondly, I now have better metrics about my work and my learning process. For example: I set myself a challenge in August last year to write a blog post every single day for a month. After I completed the challenge, I was surprised to see that the time I spent writing was reduced almost to one-third compared to at the beginning of the month. I am repeating the challenge this month, too, and I am observing a similar trend. Gut feelings are good, but metrics are better, if you can measure them. Finally, I learned that tools do not matter as much when performing lifehacks. It is more about how you use them, hence the hacking! For example, I could have invested in a more sophisticated tool, but instead I stuck to what suits my workflow best. Here is a hack that I am proud of: I wrote a small script as a GitHub CLI extension: #!/usr/bin/env bash ## Set strict mode: set -euo pipefail ## Check if we are in a git repository: if ! git rev-parse --is-inside-work-tree &>/dev/null; then >&2 echo -e "\e[31mNot in a git repository. Please run this script inside a git repository.\e[0m" exit 1 fi ## Check if watson is installed: if ! command -v watson &>/dev/null; then >&2 echo -e "\e[31mWatson is not installed. Please install it first.\e[0m" exit 1 fi ## Check if gh is installed: if ! command -v gh &>/dev/null; then >&2 echo -e "\e[31mgh is not installed. Please install it first.\e[0m" exit 1 fi ## Check if jq is installed: if ! command -v jq &>/dev/null; then >&2 echo -e "\e[31mjq is not installed. Please install it first.\e[0m" exit 1 fi ## Get the repo owner and name: _repo_info="$(gh repo view --json owner,name)" _repo_name="$(echo "${_repo_info}" | jq -r .name)" _repo_owner="$(echo "${_repo_info}" | jq -r .owner.login)" ## Log the repository information: echo -e "\e[32mStarting a new watson entry for \e[33m${_repo_owner}/${_repo_name}\e[0m" ## Start watson frame: watson start "${_repo_owner}" +"gh:${_repo_owner}/${_repo_name}" "${@}" Here is what it does: If I am in a repository, it automatically stops any existing Watson frames and starts a new one with the repository owner as the project name and gh:OWNER/REPO as a tag. The project name is not always what I want, so I change it later. But, as a person who lives inside tmux and (nowadays) neovim, the fit with my workflow is perfect: I just type gh watson and continue with my work. At this point, I believe the Pomodoro technique could really help me reap more from my time. My current setup for it is not ideal. Maybe I can find a way to integrate it into my workflow, too, without overcomplicating things. I will post about it if I manage to crack it.

I started using Watson with low expectations. Two and a half years later, it is still one of the few tools I have not quit. And it taught me a little bit about how I really spend my time.
I have been using Watson since -- well, let me check:
$ watson log --all | head -n1 | awk '{printf "%s %s, %s\n", $2, $3, $4}'
31 October, 2022
It is a small, Python-based command-line tool to track time and report how much time you spent on each project for a given period. It supports tags, so you have a bit of flexibility in how you want to categorize your time. It keeps the data in a flat, very simple JSON file, so you can easily back it up or even edit it by hand if you need to.
Unfortunately, that is all it does. Projects and tags are good, but being able to take notes would be a great addition. This led me sometimes to use long, verbose tags for simple notes. To be honest, I never looked at those tags again.
I knew that the project was not actively maintained. There are no bugs I know of, and there are no new releases since May 2022: That is three years now. Actually, when I was writing this blog post, I found out that the GitHub repository was moved under Jazzband, a community that saves and survives Python projects.
When I started using it, I was skeptical. I thought that I would use it for a few days and then forget about it. But I managed to stick with it until now. I checked alternatives from time to time, but I never found anything that I liked significantly more than Watson. In fact, I even wrote blog posts (1, 2, 3) to show how to work on Watson data using Haskell.
Here are my three takeaways after using Watson for about 2.5 years:
Tracking time is a good habit. It will not necessarily make you productive, but it will help you understand where you spend your time. I knew that I was tinkering a lot, but I did not know the extent of it. Likewise, all the sysadmin and devops activities I did were much more than I expected. The first immediate benefit in my case was that I stopped lying to myself. Then, I slowly started changing my daily and weekly routines to compartmentalize tinkering and chores.
Secondly, I now have better metrics about my work and my learning process. For example: I set myself a challenge in August last year to write a blog post every single day for a month. After I completed the challenge, I was surprised to see that the time I spent writing was reduced almost to one-third compared to at the beginning of the month. I am repeating the challenge this month, too, and I am observing a similar trend. Gut feelings are good, but metrics are better, if you can measure them.
Finally, I learned that tools do not matter as much when performing lifehacks. It is more about how you use them, hence the hacking! For example, I could have invested in a more sophisticated tool, but instead I stuck to what suits my workflow best.
Here is a hack that I am proud of: I wrote a small script as a GitHub CLI extension:
#!/usr/bin/env bash
## Set strict mode:
set -euo pipefail
## Check if we are in a git repository:
if ! git rev-parse --is-inside-work-tree &>/dev/null; then
>&2 echo -e "\e[31mNot in a git repository. Please run this script inside a git repository.\e[0m"
exit 1
fi
## Check if watson is installed:
if ! command -v watson &>/dev/null; then
>&2 echo -e "\e[31mWatson is not installed. Please install it first.\e[0m"
exit 1
fi
## Check if gh is installed:
if ! command -v gh &>/dev/null; then
>&2 echo -e "\e[31mgh is not installed. Please install it first.\e[0m"
exit 1
fi
## Check if jq is installed:
if ! command -v jq &>/dev/null; then
>&2 echo -e "\e[31mjq is not installed. Please install it first.\e[0m"
exit 1
fi
## Get the repo owner and name:
_repo_info="$(gh repo view --json owner,name)"
_repo_name="$(echo "${_repo_info}" | jq -r .name)"
_repo_owner="$(echo "${_repo_info}" | jq -r .owner.login)"
## Log the repository information:
echo -e "\e[32mStarting a new watson entry for \e[33m${_repo_owner}/${_repo_name}\e[0m"
## Start watson frame:
watson start "${_repo_owner}" +"gh:${_repo_owner}/${_repo_name}" "${@}"
Here is what it does: If I am in a repository, it automatically stops any existing Watson frames and starts a new one with the repository owner as the project name and gh:OWNER/REPO as a tag. The project name is not always what I want, so I change it later. But, as a person who lives inside tmux and (nowadays) neovim, the fit with my workflow is perfect: I just type gh watson and continue with my work.
At this point, I believe the Pomodoro technique could really help me reap more from my time. My current setup for it is not ideal. Maybe I can find a way to integrate it into my workflow, too, without overcomplicating things. I will post about it if I manage to crack it.