















































































































































































![[The AI Show Episode 153]: OpenAI Releases o3-Pro, Disney Sues Midjourney, Altman: “Gentle Singularity” Is Here, AI and Jobs & News Sites Getting Crushed by AI Search](https://www.marketingaiinstitute.com/hubfs/ep%20153%20cover.png)



































































































































































































































































_Alexander-Yakimov_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_Zoonar_GmbH_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

















































































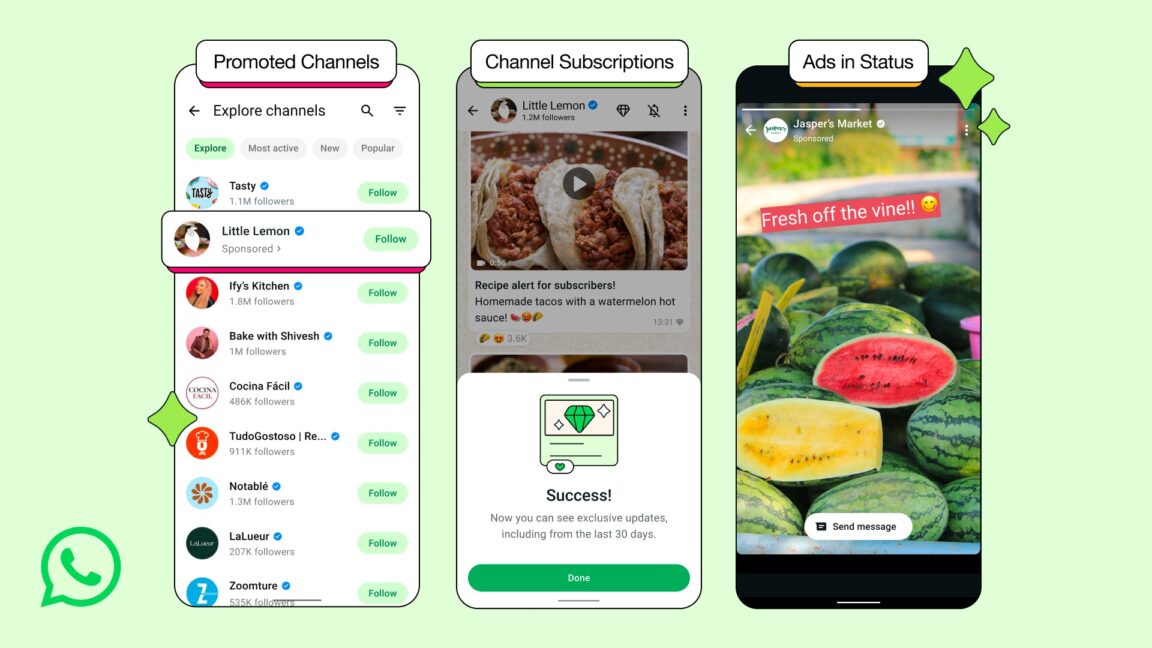












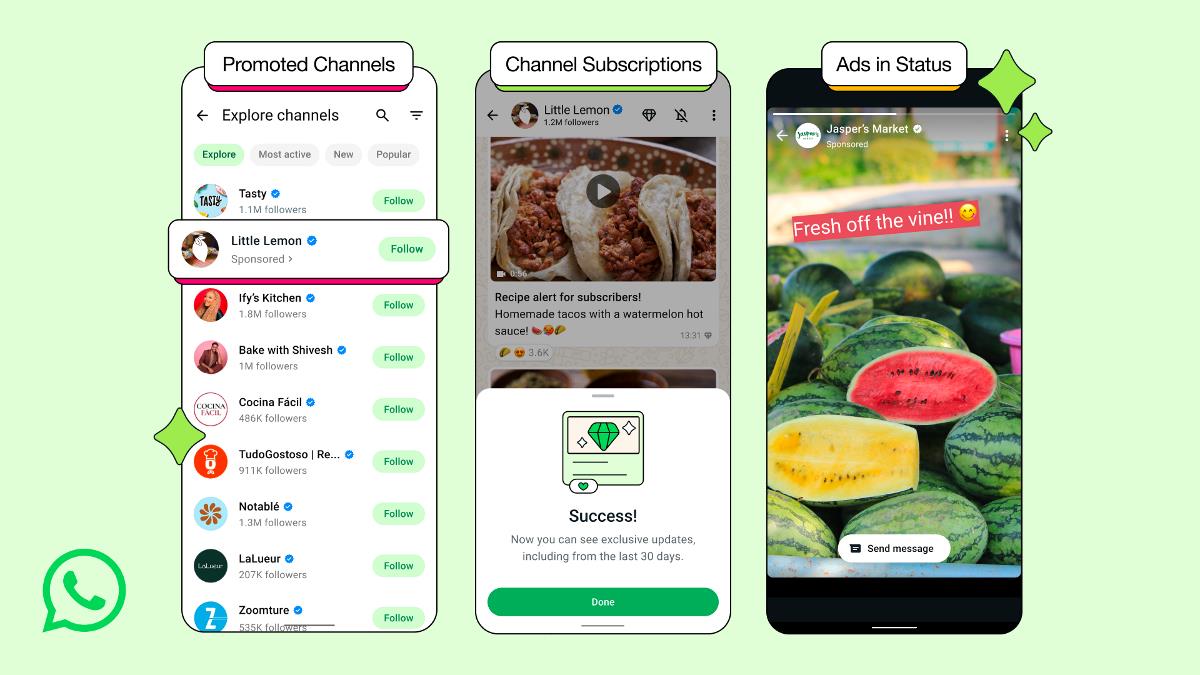
![Meta AI app ‘a privacy disaster’ as chats unknowingly made public [U: Warning added]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/06/Meta-AI-app-a-privacy-disaster-as-chats-inadvertently-made-public.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)

![OnePlus Pad Lite officially teased just as its specs leak [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/06/oneplus-nord-pad-lite-lineup-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)














![AirPods Pro 3 Not Launching Until 2026 [Pu]](https://www.iclarified.com/images/news/97620/97620/97620-640.jpg)
![Apple Releases First Beta of iOS 18.6 and iPadOS 18.6 to Developers [Download]](https://www.iclarified.com/images/news/97626/97626/97626-640.jpg)
![Apple Seeds watchOS 11.6 Beta to Developers [Download]](https://www.iclarified.com/images/news/97627/97627/97627-640.jpg)
![Apple Seeds tvOS 18.6 Beta to Developers [Download]](https://www.iclarified.com/images/news/97628/97628/97628-640.jpg)














































![Nothing Phone (3) may debut with a "flagship" chip – just not the flagship-est one [UPDATED]](https://m-cdn.phonearena.com/images/article/171412-two/Nothing-Phone-3-may-debut-with-a-flagship-chip--just-not-the-flagship-est-one-UPDATED.jpg?#)













[Thread] A new US paper shows the best frontier LLM models achieve 0% on hard real-life Programming Contest problems, domains where expert humans still excel (Rohan Paul/@rohanpaul_ai)
Rohan Paul / @rohanpaul_ai: [Thread] A new US paper shows the best frontier LLM models achieve 0% on hard real-life Programming Contest problems, domains where expert humans still excel — This is really BAD news of LLM's coding skill. ☹️ The best Frontier LLM models achieve 0% on hard real-life Programming Contest problems, domains where expert humans still excel. LiveCodeBench Pro, a benchmark composed of problems from Codeforces, ICPC, and IOI ("International [image]
![[Thread] A new US paper shows the best frontier LLM models achieve 0% on hard real-life Programming Contest problems, domains where expert humans still excel (Rohan Paul/@rohanpaul_ai)](http://www.techmeme.com/img/pml.png)
![]() Rohan Paul / @rohanpaul_ai:
Rohan Paul / @rohanpaul_ai:
[Thread] A new US paper shows the best frontier LLM models achieve 0% on hard real-life Programming Contest problems, domains where expert humans still excel — This is really BAD news of LLM's coding skill. ☹️ The best Frontier LLM models achieve 0% on hard real-life Programming Contest problems, domains where expert humans still excel. LiveCodeBench Pro, a benchmark composed of problems from Codeforces, ICPC, and IOI ("International [image]


