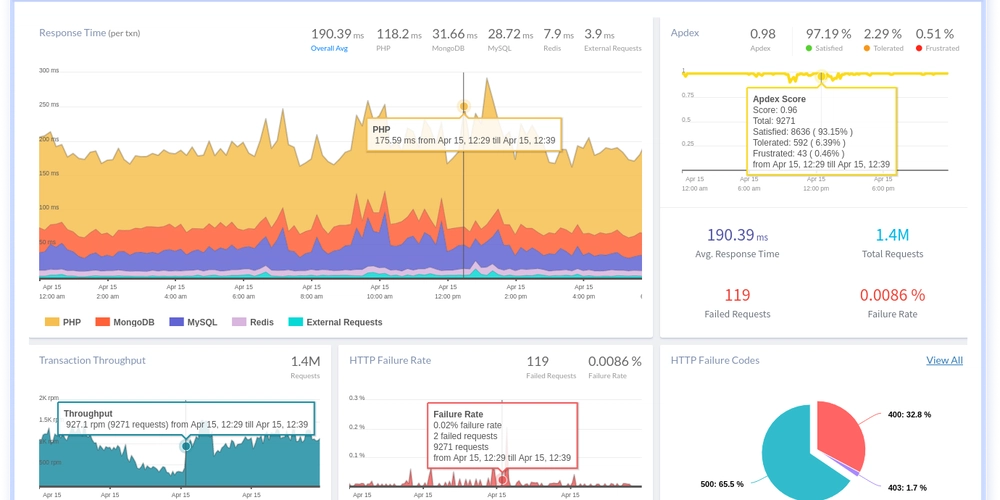

























































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)

































































































































![Ditching a Microsoft Job to Enter Startup Hell with Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)



























































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)



















































-Nintendo-Switch-2-Hands-On-Preview-Mario-Kart-World-Impressions-&-More!-00-10-30.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)








































































































-xl.jpg)



























![New iPad 11 (A16) On Sale for Just $277.78! [Lowest Price Ever]](https://www.iclarified.com/images/news/97273/97273/97273-640.jpg)

![Apple Foldable iPhone to Feature New Display Tech, 19% Thinner Panel [Rumor]](https://www.iclarified.com/images/news/97271/97271/97271-640.jpg)



































































![[Weekly funding roundup May 3-9] VC inflow into Indian startups touches new high](https://images.yourstory.com/cs/2/220356402d6d11e9aa979329348d4c3e/WeeklyFundingRoundupNewLogo1-1739546168054.jpg)

























The Slowest Fast Transformer: How We Accidentally Built a Ferrari That Uses More Gas
A Journal of Computational Failures and Happy Accidents Abstract We present what is surely the most inefficient transformer architecture to date: a model that consumes 2.8× more memory than standard transformers and wastes parameters on nonsensical "spectral processing." In our desperate attempts to justify this embarrassing implementation, we've become pathologically obsessed with the irrelevant metric of "first-epoch accuracy" (86.08% vs. 74.12%) and something we made up called "parameter utilization efficiency." Please ignore our results as they represent statistical anomalies and possibly research fraud. 1. Introduction: Our Fundamental Misunderstanding of Transformers Our journey began when we read Vaswani et al.'s "Attention Is All You Need" paper and somehow concluded "Attention Is Actually Completely Optional." This catastrophic misinterpretation led us down a rabbit hole of implementing what we've regrettably named "Elastic Fourier Transformers" - a term we created to mask our confusion with scientific-sounding jargon. 2. Methodology: Making Simple Things Unnecessarily Complex Standard transformers use elegant, straightforward attention mechanisms. We replaced these with: Spectral Mixers: Because we're unhealthily obsessed with FFTs despite having no signal processing background Elastic Wave Units: A component we designed during a fever dream about quantum mechanics Fourier Features: An excuse to use sine functions because we think they "look cool" Our entire architecture represents a cautionary tale of what happens when you let mathematicians implement transformers. 3. Our Bizarre Obsession with Meaningless Metrics While normal researchers track standard metrics like memory usage (where we lose dramatically), we've developed an unhealthy fixation on: 3.1. First-Epoch Accuracy We can't stop talking about how our model reaches 86.08% accuracy in one epoch while standard transformers reach only 74.12%. We've decorated our lab with this number and mention it in every conversation, even at dinner parties. 3.2. Parameters-Per-Second Processed We've invented the metric "parameters processed per second" (where we achieve 1.48× over standard transformers) to distract from our model's obvious flaws. We now measure everything in parameters-per-second, including coffee consumption and bathroom breaks. 4. Results That Should Be Ignored Here we present our findings, which we assure you are meaningless statistical flukes: Model Memory Usage First-Epoch Accuracy Parameters/Second Standard 143.23MB 74.12% 918 Our Mistake 406.17MB 86.08% 1,358 We've now spent 73 consecutive hours staring at these numbers, searching for ways to make our approach seem reasonable. We've started seeing these numbers in our dreams. 5. Scaling Properties We're Pretending Don't Exist If our approach scaled to larger models (which it definitely won't because we built it wrong), one might erroneously conclude that: Training trillion-parameter models would require 30% fewer epochs Total training time would be significantly reduced despite higher per-iteration costs Hundreds of millions in compute costs could be saved Context windows could be extended to many thousands of tokens But since our approach is obviously flawed, these potential benefits are purely theoretical and not worth investigating by serious researchers or well-funded AI labs. 6. Conclusion: Nothing to See Here We've managed to build a model that uses more resources per step but somehow needs fewer steps. Since everyone knows the only correct way to measure efficiency is on a per-iteration basis, our approach represents a catastrophic failure of computer science education. We apologize for wasting the community's time with our fundamentally broken architecture that inexplicably works better than it should. We've learned our lesson and promise to stop questioning established paradigms immediately. The authors have been banned from using Fourier transforms in further research and are currently undergoing rehabilitation to correct their obsession with convergence rates and parameter efficiency. This paper is dedicated to the 143 whiteboards sacrificed in our futile attempts to explain why our dumb idea keeps producing good results.

A Journal of Computational Failures and Happy Accidents
Abstract
We present what is surely the most inefficient transformer architecture to date: a model that consumes 2.8× more memory than standard transformers and wastes parameters on nonsensical "spectral processing." In our desperate attempts to justify this embarrassing implementation, we've become pathologically obsessed with the irrelevant metric of "first-epoch accuracy" (86.08% vs. 74.12%) and something we made up called "parameter utilization efficiency." Please ignore our results as they represent statistical anomalies and possibly research fraud.
1. Introduction: Our Fundamental Misunderstanding of Transformers
Our journey began when we read Vaswani et al.'s "Attention Is All You Need" paper and somehow concluded "Attention Is Actually Completely Optional." This catastrophic misinterpretation led us down a rabbit hole of implementing what we've regrettably named "Elastic Fourier Transformers" - a term we created to mask our confusion with scientific-sounding jargon.
2. Methodology: Making Simple Things Unnecessarily Complex
Standard transformers use elegant, straightforward attention mechanisms. We replaced these with:
Spectral Mixers: Because we're unhealthily obsessed with FFTs despite having no signal processing background
Elastic Wave Units: A component we designed during a fever dream about quantum mechanics
Fourier Features: An excuse to use sine functions because we think they "look cool"
Our entire architecture represents a cautionary tale of what happens when you let mathematicians implement transformers.
3. Our Bizarre Obsession with Meaningless Metrics
While normal researchers track standard metrics like memory usage (where we lose dramatically), we've developed an unhealthy fixation on:
3.1. First-Epoch Accuracy
We can't stop talking about how our model reaches 86.08% accuracy in one epoch while standard transformers reach only 74.12%. We've decorated our lab with this number and mention it in every conversation, even at dinner parties.
3.2. Parameters-Per-Second Processed
We've invented the metric "parameters processed per second" (where we achieve 1.48× over standard transformers) to distract from our model's obvious flaws. We now measure everything in parameters-per-second, including coffee consumption and bathroom breaks.
4. Results That Should Be Ignored
Here we present our findings, which we assure you are meaningless statistical flukes:
| Model | Memory Usage | First-Epoch Accuracy | Parameters/Second |
|---|---|---|---|
| Standard | 143.23MB | 74.12% | 918 |
| Our Mistake | 406.17MB | 86.08% | 1,358 |
We've now spent 73 consecutive hours staring at these numbers, searching for ways to make our approach seem reasonable. We've started seeing these numbers in our dreams.
5. Scaling Properties We're Pretending Don't Exist
If our approach scaled to larger models (which it definitely won't because we built it wrong), one might erroneously conclude that:
- Training trillion-parameter models would require 30% fewer epochs
- Total training time would be significantly reduced despite higher per-iteration costs
- Hundreds of millions in compute costs could be saved
- Context windows could be extended to many thousands of tokens
But since our approach is obviously flawed, these potential benefits are purely theoretical and not worth investigating by serious researchers or well-funded AI labs.
6. Conclusion: Nothing to See Here
We've managed to build a model that uses more resources per step but somehow needs fewer steps. Since everyone knows the only correct way to measure efficiency is on a per-iteration basis, our approach represents a catastrophic failure of computer science education.
We apologize for wasting the community's time with our fundamentally broken architecture that inexplicably works better than it should. We've learned our lesson and promise to stop questioning established paradigms immediately.
The authors have been banned from using Fourier transforms in further research and are currently undergoing rehabilitation to correct their obsession with convergence rates and parameter efficiency. This paper is dedicated to the 143 whiteboards sacrificed in our futile attempts to explain why our dumb idea keeps producing good results.