













































































































































![Top Features of Vision-Based Workplace Safety Tools [2025]](https://static.wixstatic.com/media/379e66_7e75a4bcefe14e4fbc100abdff83bed3~mv2.jpg/v1/fit/w_1000,h_884,al_c,q_80/file.png?#)































![How to Use AI as a Productivity Tool with Mike Kaput [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/v2MAICON-Speaker_Series.png)
![[The AI Show Episode 152]: ChatGPT Connectors, AI-Human Relationships, New AI Job Data, OpenAI Court-Ordered to Keep ChatGPT Logs & WPP’s Large Marketing Model](https://www.marketingaiinstitute.com/hubfs/ep%20152%20cover.png)





















































































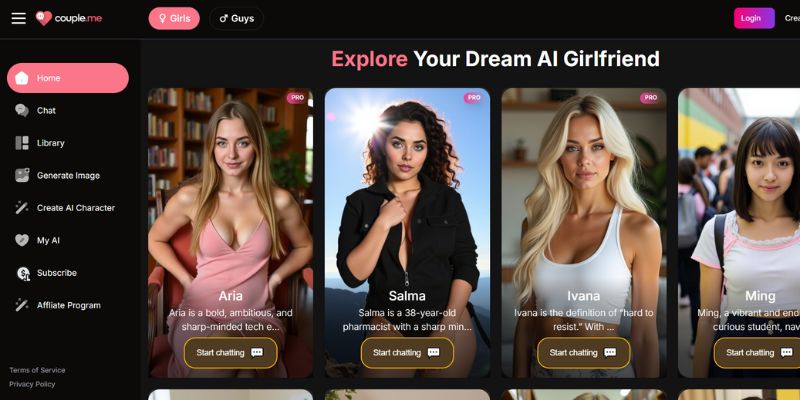

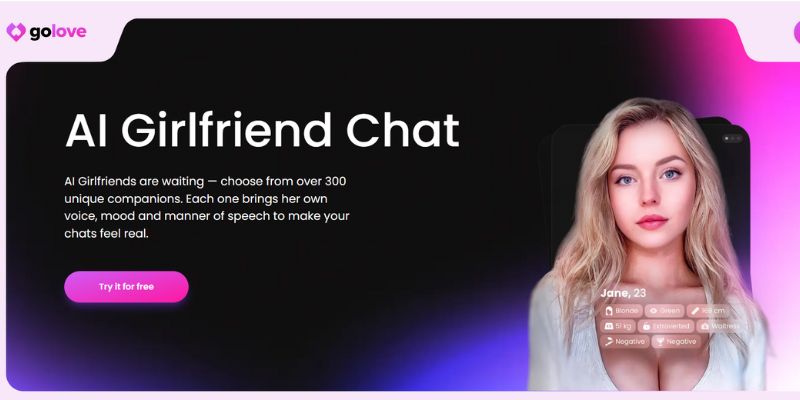


















































































































































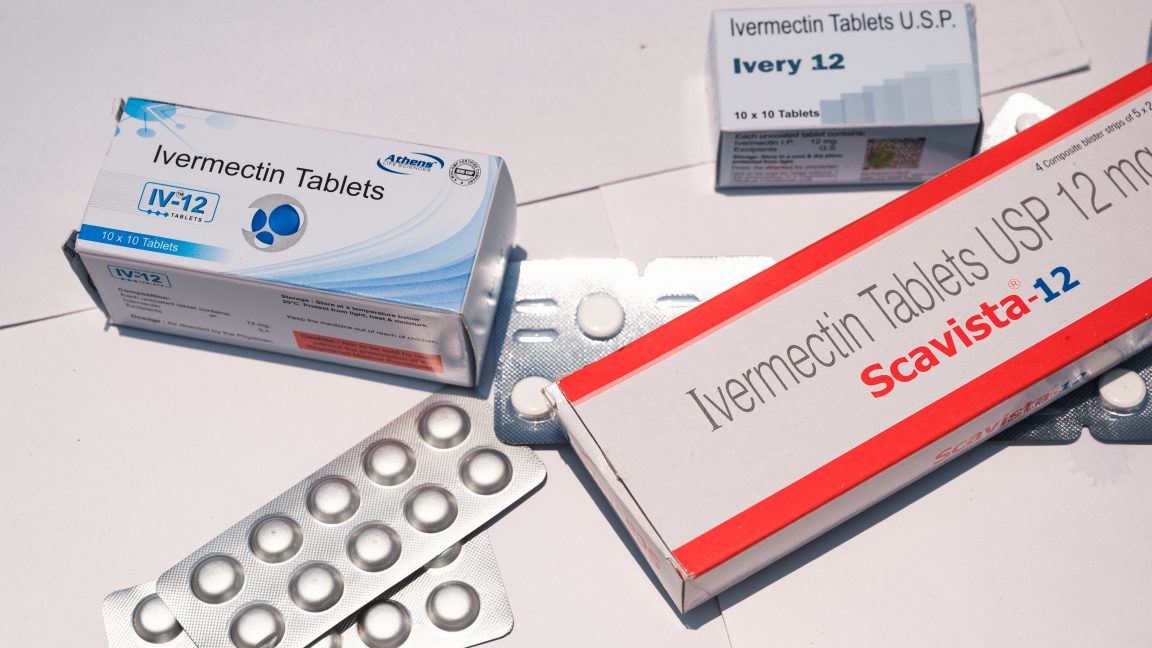
-0-6-screenshot.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

















































































































![Someone is selling a bunch of those rare Essential ‘Gem’ phones for $1,200 [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2019/10/next-essential-phone.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)














![Apple Shares Teaser Trailer for 'The Lost Bus' Starring Matthew McConaughey [Video]](https://www.iclarified.com/images/news/97582/97582/97582-640.jpg)
























































Organizing Ad-Hoc Tooling in a Multi-Repo Structure
Imagine you have the following scenario. Your organization deploys some app core to its mission. For example if you're Stack Exchange, this might be the customer facing web server. Let's also say you subscribe to something like the 12-Factor App philosophy. Each app mantains its own SCM repo, which acts as the canonical source of truth. You might also have org-wide libraries which are consumed by zero, one or multiple apps, and maintain their own SCM repos. Finally the app itself may be deployed over many different sites, each with potentially different configurations or underlying infrastructure. Okay, now the wrinkle comes with how you handle tooling that's designed to monitor, analyze or detect anomalies with the actual app production runs. The purpose might be for sysadmin reasons (checking for critical error messages in app logs), data science (post-hoc analysis of user behavior), performance profiling, or some other reason. What are best practices for organizing this tooling in your organization's multi-repository structure.The key question is do you put this tooling with the app's main repo? (E.g. add a new top-level directory called tools/ to the repo frontend-web-server). Do you separate all the tooling for a given app into a single separate repo? (E.g. new repo called frontend-web-server-tools) Or create a separate repo for each specific tool? (E.g. frontend-web-server-user-analysis, frontend-web-server-runtime-monitor, frontend-web-server-profiler) I see some strong arguments on all sides: The tooling may have fairly strong dependencies on the underlying app code itself. E.g. if we change the app's log format, then anything consuming those logs probably also has to be change. Keeping it a single repo reduces the chance of breaking the tooling on codebase changes. The tooling itself probably conforms to much looser software engineering standards, and a lot of tools may created on a one-off or ad-hoc basis then thrown away. We may not want to pollute the main repo with this. Some of the tooling may span multiple apps. For example for some data science analytics script we may want to join activity in the front-end app with data from a backing microservice. The tooling itself is likely to benefit from a shared codebase. If we have a tool to do X and a tool to Y, they may both need some logic to do Z. Obviously DRY, so we often we probably want similar tools to at least be in the same repo with each other. The tooling may also consume code directly from the app's codebase. Maybe we have a tool that replays activity for some test environment. That might be a lot easier to do by relying on a single module within the app to avoid DRY. Compiling the tool along with the app's codebase is a lot easier if they share a repo. It seems impractical to fork an entirely separate library repo just for one repo. Some of the tooling might be specific to the deploy. You wouldn't want to pollute the app codebase with deploy details. Maybe a single approach doesn't capture all the idiosyncrasies of different plausible scenarios. But how do large organizations typically handle situations like this? Or at least how do they approach making these decisions?
Imagine you have the following scenario. Your organization deploys some app core to its mission. For example if you're Stack Exchange, this might be the customer facing web server. Let's also say you subscribe to something like the 12-Factor App philosophy. Each app mantains its own SCM repo, which acts as the canonical source of truth. You might also have org-wide libraries which are consumed by zero, one or multiple apps, and maintain their own SCM repos. Finally the app itself may be deployed over many different sites, each with potentially different configurations or underlying infrastructure.
Okay, now the wrinkle comes with how you handle tooling that's designed to monitor, analyze or detect anomalies with the actual app production runs. The purpose might be for sysadmin reasons (checking for critical error messages in app logs), data science (post-hoc analysis of user behavior), performance profiling, or some other reason.
What are best practices for organizing this tooling in your organization's multi-repository structure.The key question is do you put this tooling with the app's main repo? (E.g. add a new top-level directory called tools/ to the repo frontend-web-server). Do you separate all the tooling for a given app into a single separate repo? (E.g. new repo called frontend-web-server-tools) Or create a separate repo for each specific tool? (E.g. frontend-web-server-user-analysis, frontend-web-server-runtime-monitor, frontend-web-server-profiler)
I see some strong arguments on all sides:
- The tooling may have fairly strong dependencies on the underlying app code itself. E.g. if we change the app's log format, then anything consuming those logs probably also has to be change. Keeping it a single repo reduces the chance of breaking the tooling on codebase changes.
- The tooling itself probably conforms to much looser software engineering standards, and a lot of tools may created on a one-off or ad-hoc basis then thrown away. We may not want to pollute the main repo with this.
- Some of the tooling may span multiple apps. For example for some data science analytics script we may want to join activity in the front-end app with data from a backing microservice.
- The tooling itself is likely to benefit from a shared codebase. If we have a tool to do X and a tool to Y, they may both need some logic to do Z. Obviously DRY, so we often we probably want similar tools to at least be in the same repo with each other.
- The tooling may also consume code directly from the app's codebase. Maybe we have a tool that replays activity for some test environment. That might be a lot easier to do by relying on a single module within the app to avoid DRY. Compiling the tool along with the app's codebase is a lot easier if they share a repo. It seems impractical to fork an entirely separate library repo just for one repo.
- Some of the tooling might be specific to the deploy. You wouldn't want to pollute the app codebase with deploy details.
Maybe a single approach doesn't capture all the idiosyncrasies of different plausible scenarios. But how do large organizations typically handle situations like this? Or at least how do they approach making these decisions?

