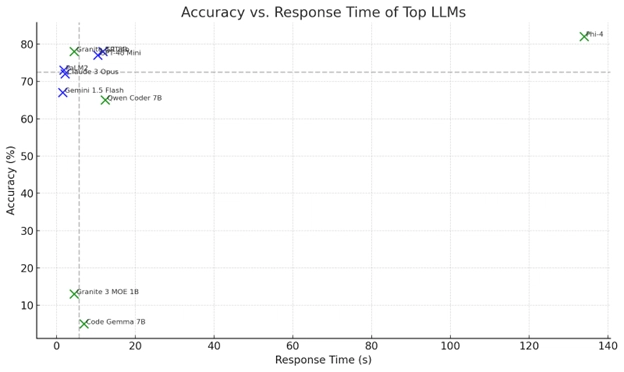


















































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)





























































































































![From Accountant to Data Engineer with Alyson La [Podcast #168]](https://cdn.hashnode.com/res/hashnode/image/upload/v1744420903260/fae4b593-d653-41eb-b70b-031591aa2f35.png?#)







































































































.png?#)






















![Apple TV+ Summer Preview 2025 [Video]](https://www.iclarified.com/images/news/96999/96999/96999-640.jpg)





















































































































![Apple Watch SE 2 On Sale for Just $169.97 [Deal]](https://www.iclarified.com/images/news/96996/96996/96996-640.jpg)

![Apple Posts Full First Episode of 'Your Friends & Neighbors' on YouTube [Video]](https://www.iclarified.com/images/news/96990/96990/96990-640.jpg)
























































































































Nexus Search: RAG-Powered Semantic Search for HPKV
In traditional key-value stores, finding data relies on knowing exact keys or key patterns. This works well for structured, predictable access patterns, but falls short when dealing with unstructured content or natural language queries. This article introduces Nexus Search, our solution for adding semantic understanding to HPKV. What is Nexus Search? Nexus Search adds Retrieval Augmented Generation (RAG) capabilities to HPKV, enabling semantic search and AI-powered question answering over your key-value data. Unlike traditional key-based access, Nexus Search understands the meaning of your content, allowing natural language queries and intelligent information retrieval. At its core, Nexus Search combines two powerful capabilities: Semantic Search: Finding records based on meaning rather than exact key matches Question Answering: Generating natural language responses by analyzing relevant records These capabilities unlock entirely new ways to interact with your data, transforming HPKV from a simple storage system into an intelligent knowledge base. The Architecture Nexus Search operates alongside your existing HPKV storage, adding a semantic layer without compromising the performance characteristics that make HPKV valuable. When you write data to HPKV, Nexus Search automatically processes your content: Your key-value data is stored in HPKV as usual The text content is converted into vector embeddings (numerical representations that capture meaning) These embeddings are stored in a specialized vector database When you search or query, your input is converted to the same vector format The system finds the most similar vectors to your query For queries, an AI model generates a natural language response based on the retrieved content This process happens automatically in the background whenever you add or update data through the standard HPKV API. Implementation Details Nexus Search exposes two main endpoints: Search Endpoint The /search endpoint finds semantically similar records to a given query: POST /search Content-Type: application/json X-Api-Key: YOUR_API_KEY { "query": "Your natural language search query", "topK": 5, // Optional: number of results to return (default: 5) "minScore": 0.5 // Optional: minimum similarity score threshold (default: 0.5) } The response includes matching keys and their similarity scores: { "results": [ { "key": "article:123", "score": 0.87 }, { "key": "product:456", "score": 0.76 }, ... ] } Query Endpoint The /query endpoint provides AI-generated answers to questions about your data: POST /query Content-Type: application/json X-Api-Key: YOUR_API_KEY { "query": "Your natural language question", "topK": 5, // Optional: number of relevant records to use (default: 5) "minScore": 0.5 // Optional: minimum similarity score threshold (default: 0.5) } The response includes both the answer and the source records used to generate it: { "answer": "The AI-generated answer to your question based on your data", "sources": [ { "key": "article:123", "score": 0.87 }, { "key": "product:456", "score": 0.76 }, ... ] } Practical Use Cases Let's explore two practical applications of Nexus Search: log analysis and semantic product filtering. Log Analysis Application logs contain valuable information, but finding relevant events can be challenging, especially when you don't know exact patterns to search for. Nexus Search transforms log analysis by allowing natural language queries over log data. Consider this sample log data stored in HPKV: key: 20231004123456, value: "2023-10-04 12:34:56 INFO [WebServer] GET /index.html 200 123.456.789.012" key: 20231004123510, value: "2023-10-04 12:35:10 ERROR [WebServer] GET /nonexistent.html 404 123.456.789.012" key: 20231004123600, value: "2023-10-04 12:36:00 INFO [AuthService] User 'john_doe' authenticated successfully from IP 123.456.789.012" key: 20231004123605, value: "2023-10-04 12:36:05 WARN [AuthService] Authentication failed for user 'john_doe' from IP 123.456.789.012" key: 20231004123700, value: "2023-10-04 12:37:00 INFO [OrderService] User 'john_doe' placed an order with ID 12345" key: 20231004123705, value: "2023-10-04 12:37:05 ERROR [OrderService] Failed to process order for user 'john_doe': Insufficient funds" key: 20231004123805, value: "2023-10-04 12:38:05 ERROR [Database] Query failed: INSERT INTO orders ... - Duplicate entry" key: 20231004123900, value: "2023-10-04 12:39:00 INFO [PaymentGateway] Initiated payment for order 12345" key: 20231004123910, value: "2023-10-04 12:39:10 ERROR [PaymentGateway] Payment failed for order 12345: Invalid card number" With traditional key-value access, you would need to: Know which keys to check or scan a range of keys Manually filter the res
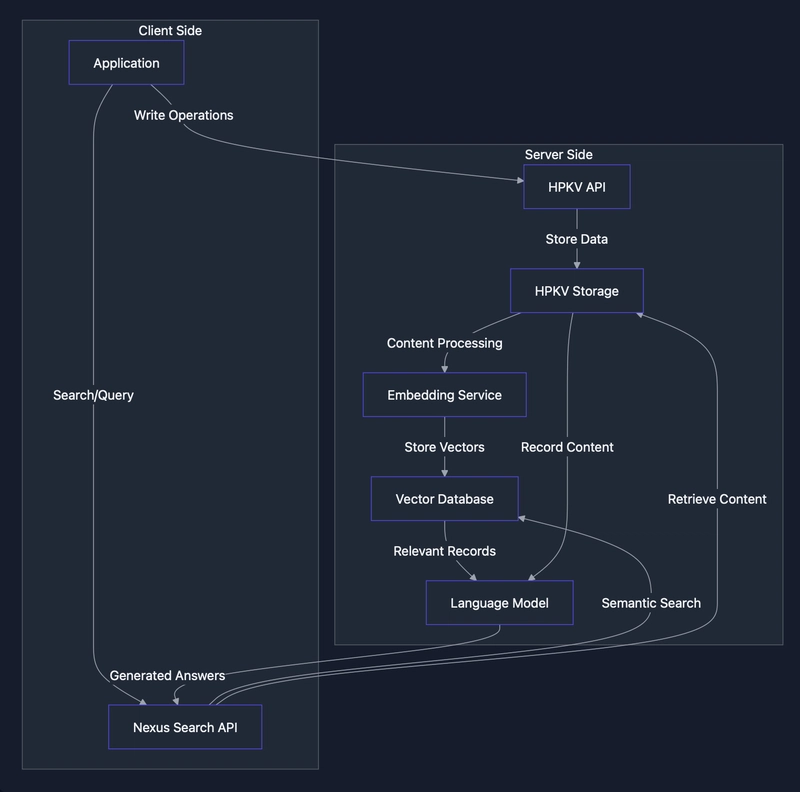
In traditional key-value stores, finding data relies on knowing exact keys or key patterns. This works well for structured, predictable access patterns, but falls short when dealing with unstructured content or natural language queries. This article introduces Nexus Search, our solution for adding semantic understanding to HPKV.
What is Nexus Search?
Nexus Search adds Retrieval Augmented Generation (RAG) capabilities to HPKV, enabling semantic search and AI-powered question answering over your key-value data. Unlike traditional key-based access, Nexus Search understands the meaning of your content, allowing natural language queries and intelligent information retrieval.
At its core, Nexus Search combines two powerful capabilities:
- Semantic Search: Finding records based on meaning rather than exact key matches
- Question Answering: Generating natural language responses by analyzing relevant records
These capabilities unlock entirely new ways to interact with your data, transforming HPKV from a simple storage system into an intelligent knowledge base.
The Architecture
Nexus Search operates alongside your existing HPKV storage, adding a semantic layer without compromising the performance characteristics that make HPKV valuable.
When you write data to HPKV, Nexus Search automatically processes your content:
- Your key-value data is stored in HPKV as usual
- The text content is converted into vector embeddings (numerical representations that capture meaning)
- These embeddings are stored in a specialized vector database
- When you search or query, your input is converted to the same vector format
- The system finds the most similar vectors to your query
- For queries, an AI model generates a natural language response based on the retrieved content
This process happens automatically in the background whenever you add or update data through the standard HPKV API.
Implementation Details
Nexus Search exposes two main endpoints:
Search Endpoint
The /search endpoint finds semantically similar records to a given query:
POST /search
Content-Type: application/json
X-Api-Key: YOUR_API_KEY
{
"query": "Your natural language search query",
"topK": 5, // Optional: number of results to return (default: 5)
"minScore": 0.5 // Optional: minimum similarity score threshold (default: 0.5)
}
The response includes matching keys and their similarity scores:
{
"results": [
{
"key": "article:123",
"score": 0.87
},
{
"key": "product:456",
"score": 0.76
},
...
]
}
Query Endpoint
The /query endpoint provides AI-generated answers to questions about your data:
POST /query
Content-Type: application/json
X-Api-Key: YOUR_API_KEY
{
"query": "Your natural language question",
"topK": 5, // Optional: number of relevant records to use (default: 5)
"minScore": 0.5 // Optional: minimum similarity score threshold (default: 0.5)
}
The response includes both the answer and the source records used to generate it:
{
"answer": "The AI-generated answer to your question based on your data",
"sources": [
{
"key": "article:123",
"score": 0.87
},
{
"key": "product:456",
"score": 0.76
},
...
]
}
Practical Use Cases
Let's explore two practical applications of Nexus Search: log analysis and semantic product filtering.
Log Analysis
Application logs contain valuable information, but finding relevant events can be challenging, especially when you don't know exact patterns to search for. Nexus Search transforms log analysis by allowing natural language queries over log data.
Consider this sample log data stored in HPKV:
key: 20231004123456, value: "2023-10-04 12:34:56 INFO [WebServer] GET /index.html 200 123.456.789.012"
key: 20231004123510, value: "2023-10-04 12:35:10 ERROR [WebServer] GET /nonexistent.html 404 123.456.789.012"
key: 20231004123600, value: "2023-10-04 12:36:00 INFO [AuthService] User 'john_doe' authenticated successfully from IP 123.456.789.012"
key: 20231004123605, value: "2023-10-04 12:36:05 WARN [AuthService] Authentication failed for user 'john_doe' from IP 123.456.789.012"
key: 20231004123700, value: "2023-10-04 12:37:00 INFO [OrderService] User 'john_doe' placed an order with ID 12345"
key: 20231004123705, value: "2023-10-04 12:37:05 ERROR [OrderService] Failed to process order for user 'john_doe': Insufficient funds"
key: 20231004123805, value: "2023-10-04 12:38:05 ERROR [Database] Query failed: INSERT INTO orders ... - Duplicate entry"
key: 20231004123900, value: "2023-10-04 12:39:00 INFO [PaymentGateway] Initiated payment for order 12345"
key: 20231004123910, value: "2023-10-04 12:39:10 ERROR [PaymentGateway] Payment failed for order 12345: Invalid card number"
With traditional key-value access, you would need to:
- Know which keys to check or scan a range of keys
- Manually filter the results for relevant content
- Piece together related events from different logs
With Nexus Search, you can simply ask natural language questions:
// Query: "What happened with user john_doe's order?"
const response = await fetch("https://nexus.hpkv.io/query", {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-Api-Key': 'YOUR_API_KEY'
},
body: JSON.stringify({
query: "What happened with user john_doe's order?"
})
});
const data = await response.json();
console.log(data.answer);
Response:
{
"answer": "According to the log, here's what happened with user john_doe's order:
1. At 12:37:00, user john_doe placed an order with ID 12345.
2. At 12:37:05, the order failed to process due to insufficient funds.
3. At 12:39:00, the payment gateway initiated payment for the order.
4. At 12:39:10, the payment failed due to an invalid card number.
So, unfortunately, the order was not successfully processed and paid for.",
"sources": [
{ "key": "20231004123700", "score": 0.8413863 },
{ "key": "20231004123705", "score": 0.8051659 },
{ "key": "20231004123900", "score": 0.7073802 },
{ "key": "20231004123910", "score": 0.6628850 }
]
}
Nexus Search automatically identifies relevant log entries, understands their relationships, and synthesizes a coherent explanation—without requiring you to know log formats or key patterns.
Our users have applied this pattern to analyze:
- Application error logs to troubleshoot issues
- Access logs to identify security concerns
- Transaction logs to trace order problems
- System metrics to investigate performance issues
This approach drastically reduces time-to-resolution for complex issues that span multiple systems or time periods.
Semantic Product Filtering
E-commerce platforms typically store product information across various systems. While structured queries work for exact attribute matching, finding products based on natural language descriptions is much harder.
Consider an e-commerce site with product specifications stored in HPKV:
// key: product:1001
{
"name": "UltraBook Pro X1",
"category": "Laptops",
"specs": {
"processor": "Intel Core i7-1280P, 14 cores (6P+8E), up to 4.8GHz",
"memory": "32GB DDR5-4800",
"storage": "1TB NVMe SSD, PCIe Gen4x4",
"display": "14-inch OLED, 2880x1800, 90Hz, 400 nits, 100% DCI-P3",
"graphics": "Intel Iris Xe Graphics",
"battery": "72Wh, up to 15 hours",
"ports": ["2x Thunderbolt 4", "1x USB-A 3.2", "HDMI 2.0", "3.5mm combo jack"],
"weight": "1.3kg"
}
}
// key: product:1002
{
"name": "PowerBook Studio",
"category": "Laptops",
"specs": {
"processor": "AMD Ryzen 9 6900HX, 8 cores, up to 4.9GHz",
"memory": "64GB DDR5-5200",
"storage": "2TB NVMe SSD, RAID 0",
"display": "16-inch Mini-LED, 3456x2234, 120Hz, 1000 nits, 100% DCI-P3",
"graphics": "AMD Radeon 680M + NVIDIA RTX 3080 Ti 16GB",
"battery": "90Wh, up to 12 hours",
"ports": ["3x USB-C 4.0", "1x USB-A 3.2", "SD Card Reader", "HDMI 2.1", "3.5mm combo jack"],
"weight": "2.2kg"
}
}
// key: product:1003
{
"name": "MacBook Air",
"category": "Laptops",
"specs": {
"processor": "Apple M2, 8-core CPU, 8-core GPU",
"memory": "16GB unified memory",
"storage": "512GB SSD",
"display": "13.6-inch IPS, 2560x1664, 60Hz, 500 nits, P3 wide color",
"graphics": "Integrated 8-core GPU",
"battery": "52.6Wh, up to 18 hours",
"ports": ["2x Thunderbolt 3", "MagSafe 3", "3.5mm headphone jack"],
"weight": "1.24kg"
}
}
Traditional KV store operations would require either:
- Maintaining separate indices for each queryable attribute
- Scanning all products and filtering in application code
- Implementing a specialized search engine alongside the KV store
With Nexus Search, you can simply search using natural language:
// Find a laptop suitable for video editing
const response = await fetch("https://nexus.hpkv.io/search", {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-Api-Key': 'YOUR_API_KEY'
},
body: JSON.stringify({
query: "powerful laptop for professional video editing and rendering"
})
});
const data = await response.json();
console.log(data.results);
Response:
{
"results": [
{ "key": "product:1002", "score": 0.89 },
{ "key": "product:1001", "score": 0.76 },
{ "key": "product:1003", "score": 0.64 }
]
}
The results are ranked by semantic relevance to the query. The PowerBook Studio ranks highest because its specs (powerful discrete GPU, large amount of RAM, high core count CPU) align well with video editing requirements, even though the product description never explicitly mentions "video editing."
Once you have the matching keys, you can retrieve the full product details using standard HPKV operations:
// Get full details for the best matching product
const productKey = data.results[0].key;
const productDetails = await hpkvClient.get(productKey);
displayProduct(JSON.parse(productDetails));
This approach combines the benefits of fast key-value lookups with the flexibility of semantic search:
- Store all product data in HPKV as usual
- Use Nexus Search to find relevant products based on natural language
- Retrieve and display only the needed products
For e-commerce applications, this enables powerful features like:
- Natural language search ("show me laptops good for college students")
- Semantic filtering ("lightweight laptops with good battery life")
- Feature-based comparison ("laptops with the best display for photo editing")
Performance and Implementation Considerations
Vector Embedding Process
When you store text data in HPKV, Nexus Search processes it as follows:
- Text extraction from the value (supporting JSON, plain text, and other formats)
- Text normalization and preprocessing
- Chunking for long content (with configurable overlap)
- Vector embedding generation
- Storage in the vector database with reference to the original HPKV key
This process happens asynchronously to avoid impacting HPKV's performance characteristics. There is typically a delay of a few seconds between data writes and when the content becomes searchable.
Resource Usage
Vector embeddings add storage overhead. For typical text content, expect:
- ~1.5-3KB of vector data per 1KB of text (varies by content type)
- Additional processing during ingestion (CPU and memory)
- Increased memory usage for the vector database
For high-volume applications, consider:
- Selectively embedding only the content that needs semantic search
- Using pagination with the
topKparameter to limit result sets - Setting appropriate
minScorethresholds to filter low-relevance matches
Limitations
While powerful, Nexus Search has some limitations to be aware of:
- The embedding model only supports English text (non-English content may have reduced accuracy)
- Up to 20 results can be returned with a single search request
- Processing delay between data writes and search availability
Real-World Performance
Performance varies based on data volume, query complexity, and subscription tier:
| Tier | Context Tokens | Output Tokens | Request Limits |
|---|---|---|---|
| Free | 24K | 1K | 100 calls/month, 12 req/min |
| Pro | 24K | 5K | 500 calls/month, 24 req/min |
| Business | 80K | 10K | 5000 calls/month, 60 req/min, agent mode |
| Enterprise | 110K | 50K | Unlimited calls, 120 req/min, agent mode |
For most applications, we see:
- Search latency: 200-500ms
- Query latency: 500ms-2s (depending on complexity)
- Indexing throughput: ~20MB/minute
Our ongoing optimizations focus on:
- Improving embedding quality for specialized domains
- Adding support for more languages and content types
Implementation Example
Here's a complete example showing how to store data and query it with Nexus Search:
// Store data in HPKV first
await fetch(`${baseUrl}/record`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-Api-Key': 'YOUR_API_KEY'
},
body: JSON.stringify({
key: 'article:databases',
value: 'High performance databases offer exceptional speed and reliability. They typically achieve sub-millisecond response times and can handle millions of operations per second. This makes them ideal for real-time applications, financial systems, gaming backends, and other use cases where latency matters.'
})
});
// Wait for a moment to allow indexing (in production, data is indexed asynchronously)
await new Promise(resolve => setTimeout(resolve, 1000));
// Query the data using Nexus Search
const response = await fetch("https://nexus.hpkv.io/query", {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-Api-Key': 'YOUR_API_KEY'
},
body: JSON.stringify({
query: "What applications benefit from high performance databases?"
})
});
const data = await response.json();
console.log(data.answer);
// Output: "High performance databases are ideal for real-time applications, financial systems, gaming backends, and other use cases where low latency is critical."
Conclusion
Nexus Search represents our approach to bridging the gap between high-performance key-value storage and semantic understanding. By adding RAG capabilities to HPKV, we've enabled entirely new ways to interact with your data without sacrificing the performance and simplicity that made HPKV valuable in the first place.
The applications go far beyond the examples we've shared here. Nexus Search can be used for applications such as:
- Customer support knowledge bases
- Internal documentation search
- Compliance monitoring across large document sets
- User-generated content moderation
- Technical troubleshooting assistants
- Research paper analysis
We've built Nexus Search with the same commitment to performance, reliability, and security that guides all our work at HPKV. The system is designed to scale with your needs, from small datasets to enterprise-scale knowledge bases.
We're just beginning to explore the possibilities of combining high-performance storage with AI-powered search and retrieval. As we continue to refine and expand Nexus Search, we welcome your feedback, questions, and use cases to help guide our development priorities.
Nexus Search is available on all HPKV subscription tiers, with features and limits varying by tier. Visit our pricing page for details, or dive into the documentation to get started.