










































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)

































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)











































































































.png?#)























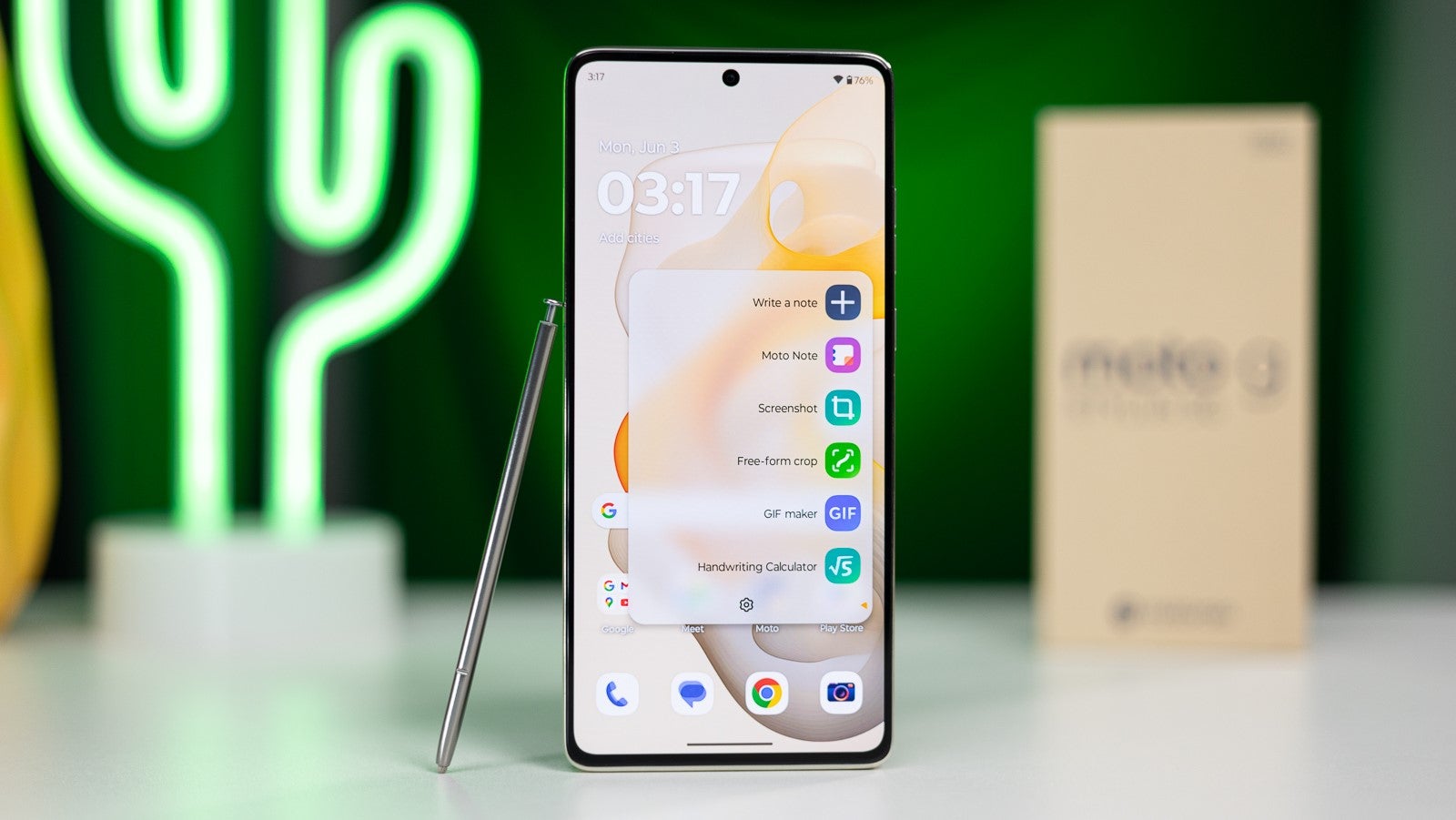










_Christophe_Coat_Alamy.jpg?#)



.webp?#)






































































































![Apple Considers Delaying Smart Home Hub Until 2026 [Gurman]](https://www.iclarified.com/images/news/96946/96946/96946-640.jpg)
![iPhone 17 Pro Won't Feature Two-Toned Back [Gurman]](https://www.iclarified.com/images/news/96944/96944/96944-640.jpg)
![Tariffs Threaten Apple's $999 iPhone Price Point in the U.S. [Gurman]](https://www.iclarified.com/images/news/96943/96943/96943-640.jpg)

























































































































Unlocking the Power of AWS: A Guide to Amazon S3 (Simple Storage Service)
Amazon Web Services (AWS) offers a wide range of cloud computing services, but one that stands out for its versatility and popularity is Amazon S3 (Simple Storage Service). Whether you're a beginner or an experienced cloud architect, understanding how to leverage Amazon S3 is crucial for efficient data storage and management. In this article, we’ll walk through the core concepts of Amazon S3, its features, and best practices to help you get the most out of this powerful service. What is Amazon S3? Amazon S3 is an object storage service that provides scalable, durable, and low-latency storage. It’s designed to store and retrieve any amount of data at any time, from anywhere on the web. Whether you are storing images, videos, backups, logs, or large datasets, S3 allows you to store files in "buckets" and access them via a web interface or through APIs. Amazon S3 is widely used because of its flexibility, security features, and high availability. With S3, you can store large amounts of unstructured data in a highly reliable and cost-effective manner. Core Features of Amazon S3 Scalability Amazon S3 automatically scales to accommodate your storage needs, whether you're a small startup or a large enterprise. You don’t need to worry about provisioning hardware or manually scaling your infrastructure. Durability and Availability S3 guarantees 99.999999999% (11 9’s) durability over a given year. Data is automatically replicated across multiple data centers (availability zones), ensuring redundancy and preventing data loss in case of hardware failure. Data Security S3 provides multiple layers of security, including: Encryption: You can encrypt data both in transit and at rest using AWS-managed or customer-managed keys. Access Control: S3 allows you to control access to your data using bucket policies, IAM roles, and ACLs (Access Control Lists). Versioning S3 supports versioning, which allows you to keep multiple versions of an object. This is particularly useful for tracking changes over time, recovering from accidental deletions, or maintaining backup copies of your files. Lifecycle Policies You can set lifecycle policies to automatically transition objects between different storage classes or delete them after a certain period. This helps in managing data retention and cost optimization. Storage Classes Amazon S3 offers different storage classes to optimize costs: Standard: Best for frequently accessed data. Intelligent-Tiering: Automatically moves data between two access tiers when access patterns change. Standard-IA (Infrequent Access): Lower cost for data that’s accessed less frequently but needs rapid access. Glacier: Low-cost storage for data that is rarely accessed and can tolerate retrieval times of several hours. Glacier Deep Archive: Lowest cost storage for long-term data archival. Key Concepts of Amazon S3 Buckets: A bucket is a container for storing objects in S3. You create a bucket to upload data, and each object is stored in a unique location within that bucket. Objects: Objects are the fundamental entities stored in S3. They consist of the data itself, metadata, and a unique identifier (the object key). Object Keys: Each object in a bucket has a unique key that can be used to retrieve it. The key is often structured in a hierarchical way (using prefixes to mimic folders), but S3 does not have a true folder structure. Getting Started with Amazon S3 Here are the basic steps to get started with Amazon S3: 1. Create a Bucket Sign in to the AWS Management Console. Navigate to S3 and click on Create Bucket. Give your bucket a unique name (the name must be globally unique across all of S3). Choose the region closest to your users to reduce latency and increase performance. 2. Upload Data After creating the bucket, you can upload files by: Clicking on the Upload button in the S3 console. Dragging and dropping files from your local machine. Using the AWS CLI (Command Line Interface) or SDKs to automate the process programmatically. 3. Set Permissions You can control access to your bucket and its contents. This is done using: Bucket policies: Define rules that apply to all objects within a bucket. Access Control Lists (ACLs): Set permissions for individual objects. IAM Roles and Policies: Attach permissions to AWS Identity and Access Management (IAM) roles. 4. Manage Data Lifecycle Set up lifecycle policies to automate data management: Archive objects that aren’t frequently accessed to Glacier. Delete objects older than a certain number of days. 5. Monitor and Audit S3 integrates with AWS CloudTrail for logging and auditing API calls. You can also use Amazon CloudWatch to set up metrics and alarms related to your S3 usage, such as monitoring storage usage and retrieval rates. Best Practices for Using Amazon S3 Naming Conventions Use consistent and des

Amazon Web Services (AWS) offers a wide range of cloud computing services, but one that stands out for its versatility and popularity is Amazon S3 (Simple Storage Service). Whether you're a beginner or an experienced cloud architect, understanding how to leverage Amazon S3 is crucial for efficient data storage and management.
In this article, we’ll walk through the core concepts of Amazon S3, its features, and best practices to help you get the most out of this powerful service.
What is Amazon S3?
Amazon S3 is an object storage service that provides scalable, durable, and low-latency storage. It’s designed to store and retrieve any amount of data at any time, from anywhere on the web. Whether you are storing images, videos, backups, logs, or large datasets, S3 allows you to store files in "buckets" and access them via a web interface or through APIs.
Amazon S3 is widely used because of its flexibility, security features, and high availability. With S3, you can store large amounts of unstructured data in a highly reliable and cost-effective manner.
Core Features of Amazon S3
Scalability
Amazon S3 automatically scales to accommodate your storage needs, whether you're a small startup or a large enterprise. You don’t need to worry about provisioning hardware or manually scaling your infrastructure.Durability and Availability
S3 guarantees 99.999999999% (11 9’s) durability over a given year. Data is automatically replicated across multiple data centers (availability zones), ensuring redundancy and preventing data loss in case of hardware failure.-
Data Security
S3 provides multiple layers of security, including:- Encryption: You can encrypt data both in transit and at rest using AWS-managed or customer-managed keys.
- Access Control: S3 allows you to control access to your data using bucket policies, IAM roles, and ACLs (Access Control Lists).
Versioning
S3 supports versioning, which allows you to keep multiple versions of an object. This is particularly useful for tracking changes over time, recovering from accidental deletions, or maintaining backup copies of your files.Lifecycle Policies
You can set lifecycle policies to automatically transition objects between different storage classes or delete them after a certain period. This helps in managing data retention and cost optimization.-
Storage Classes
Amazon S3 offers different storage classes to optimize costs:- Standard: Best for frequently accessed data.
- Intelligent-Tiering: Automatically moves data between two access tiers when access patterns change.
- Standard-IA (Infrequent Access): Lower cost for data that’s accessed less frequently but needs rapid access.
- Glacier: Low-cost storage for data that is rarely accessed and can tolerate retrieval times of several hours.
- Glacier Deep Archive: Lowest cost storage for long-term data archival.
Key Concepts of Amazon S3
- Buckets: A bucket is a container for storing objects in S3. You create a bucket to upload data, and each object is stored in a unique location within that bucket.
- Objects: Objects are the fundamental entities stored in S3. They consist of the data itself, metadata, and a unique identifier (the object key).
- Object Keys: Each object in a bucket has a unique key that can be used to retrieve it. The key is often structured in a hierarchical way (using prefixes to mimic folders), but S3 does not have a true folder structure.
Getting Started with Amazon S3
Here are the basic steps to get started with Amazon S3:
1. Create a Bucket
- Sign in to the AWS Management Console.
- Navigate to S3 and click on Create Bucket.
- Give your bucket a unique name (the name must be globally unique across all of S3).
- Choose the region closest to your users to reduce latency and increase performance.
2. Upload Data
After creating the bucket, you can upload files by:
- Clicking on the Upload button in the S3 console.
- Dragging and dropping files from your local machine.
- Using the AWS CLI (Command Line Interface) or SDKs to automate the process programmatically.
3. Set Permissions
You can control access to your bucket and its contents. This is done using:
- Bucket policies: Define rules that apply to all objects within a bucket.
- Access Control Lists (ACLs): Set permissions for individual objects.
- IAM Roles and Policies: Attach permissions to AWS Identity and Access Management (IAM) roles.
4. Manage Data Lifecycle
Set up lifecycle policies to automate data management:
- Archive objects that aren’t frequently accessed to Glacier.
- Delete objects older than a certain number of days.
5. Monitor and Audit
S3 integrates with AWS CloudTrail for logging and auditing API calls. You can also use Amazon CloudWatch to set up metrics and alarms related to your S3 usage, such as monitoring storage usage and retrieval rates.
Best Practices for Using Amazon S3
Naming Conventions
Use consistent and descriptive naming conventions for your buckets and object keys. This makes it easier to organize and retrieve data as your storage grows.Data Encryption
Always enable encryption for your sensitive data. Use S3-managed keys (SSE-S3) for simplicity, or manage your own keys with SSE-KMS for additional security controls.Optimize Costs with Lifecycle Policies
Implement lifecycle policies to automatically transition objects to lower-cost storage classes, such as Glacier or Glacier Deep Archive, to optimize storage costs for data you don’t need immediate access to.Regularly Review Access Permissions
Review your access control policies regularly to ensure that only the necessary users and services have access to your S3 resources. Make use of IAM roles and policies for fine-grained control.Version Control
Enable versioning on your buckets to protect against accidental deletions or overwrites. You can retrieve older versions of an object even after it’s been modified or deleted.
Real-World Use Cases of Amazon S3
Backup and Restore
S3 is widely used for backing up databases, files, and entire systems. The durability and security of S3 make it an ideal solution for protecting critical data.Data Archival
For long-term data storage, S3 Glacier and Glacier Deep Archive provide a cost-effective solution for archiving infrequently accessed data.Web Hosting
Many websites and web applications store static assets (images, videos, and other media) on S3. S3 integrates well with Amazon CloudFront (a CDN) to deliver content globally with low latency.Big Data Storage
S3 is used as a storage layer for big data analytics platforms. Its scalability and ability to integrate with other AWS services like Amazon Athena and Amazon EMR make it ideal for processing large datasets.
Conclusion
Amazon S3 is a fundamental service within AWS, providing reliable, scalable, and cost-effective storage solutions for businesses of all sizes. By understanding its features and capabilities, you can optimize how you store, access, and manage data, ensuring both high performance and low costs. Whether you're handling backups, large-scale data analytics, or web content delivery, mastering S3 is an essential step toward becoming proficient in AWS.



