








































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)




































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)

















![QA - Best methods for getting large amount of test data into event consuming applications generated from an API application [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)






























































































-11.11.2024-4-49-screenshot.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)























_jvphoto_Alamy.jpg?#)




.png?#)















































































![Refresh your iPhone in style with the TORRAS Ostand Fitness case [15% off]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/TARROS.webp?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Debuts Official Trailer for 'Murderbot' [Video]](https://www.iclarified.com/images/news/96972/96972/96972-640.jpg)
![Alleged Case for Rumored iPhone 17 Pro Surfaces Online [Image]](https://www.iclarified.com/images/news/96969/96969/96969-640.jpg)

![Apple Rushes Five Planes of iPhones to US Ahead of New Tariffs [Report]](https://www.iclarified.com/images/news/96967/96967/96967-640.jpg)


















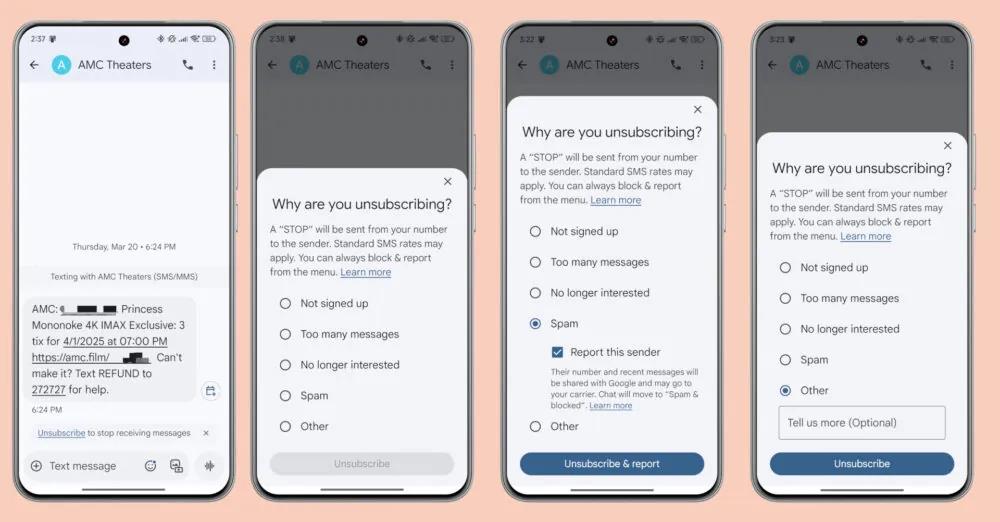



































































































New Benchmark Reveals Major Gaps in AI Vision-Language Models' Performance across 73,000 Human Tests
This is a Plain English Papers summary of a research paper called New Benchmark Reveals Major Gaps in AI Vision-Language Models' Performance across 73,000 Human Tests. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Overview ViLBench is a comprehensive benchmark for evaluating vision-language models Consists of 4 test suites: understanding, following, reasoning, and generation Includes ViLReward-73K dataset with 73,000 human preference annotations Uses VLLM-as-a-Judge evaluation methodology Reveals significant performance gaps in current multimodal AI systems Plain English Explanation ViLBench is a new way to test how well AI systems can understand and work with both images and text together. The researchers created this because they noticed that current evaluation methods don't thoroughly test all the abilities these AI systems should have. Think of ViLBen... Click here to read the full summary of this paper

This is a Plain English Papers summary of a research paper called New Benchmark Reveals Major Gaps in AI Vision-Language Models' Performance across 73,000 Human Tests. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- ViLBench is a comprehensive benchmark for evaluating vision-language models
- Consists of 4 test suites: understanding, following, reasoning, and generation
- Includes ViLReward-73K dataset with 73,000 human preference annotations
- Uses VLLM-as-a-Judge evaluation methodology
- Reveals significant performance gaps in current multimodal AI systems
Plain English Explanation
ViLBench is a new way to test how well AI systems can understand and work with both images and text together. The researchers created this because they noticed that current evaluation methods don't thoroughly test all the abilities these AI systems should have.
Think of ViLBen...



