


























































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






































































































































































































![GrandChase tier list of the best characters available [April 2025]](https://media.pocketgamer.com/artwork/na-33057-1637756796/grandchase-ios-android-3rd-anniversary.jpg?#)







































































.webp?#)




































































































![New Beats USB-C Charging Cables Now Available on Amazon [Video]](https://www.iclarified.com/images/news/97060/97060/97060-640.jpg)

![Apple M4 13-inch iPad Pro On Sale for $200 Off [Deal]](https://www.iclarified.com/images/news/97056/97056/97056-640.jpg)

























































































































การใช้โมเดล YOLOv3 ในการตรวจจับวัตถุในภาพ
หนึ่งในการ coding AI ที่น่าสนใจที่สุดคงหนีไม่พ้นการทำ AI ตรวจจับวัตถุในภาพ (Object Detection) โดยในบทความนี้ จะยกการใช้ Computer Vision + Deep Learning (CNN) ด้วยโมเดลที่ชื่อว่า YOLO (You Only Look Once) มาใช้ในการทำ AI coding โมเดลนี้ได้รับการฝึกฝนจากชุดข้อมูล coco เพื่อสามารถตรวจจับวัตถุหลากหลายประเภท จึงนับว่าเป็นโมเดลที่ฝึกเสร็จแล้ว และยังนับว่าโมเดลนี้เป็นแบบ Supervised Learning เพราะยังต้องมีการติดป้ายกำกับไว้ให้ว่าของชิ้นนี้คืออะไรจากชุดข้อมูล coco ซึ่ง YOLOv3 นี้มีแนวคิดว่า ดูภาพเพียงครั้งเดียว (You Only Look Once) แล้วตรวจจับวัตถุทั้งหมดในคราวเดียว โดยมีขั้นตอนดังนี้ แบ่งภาพเป็น grid ทุกช่องของตารางจะเป็นผู้ทำนายว่า มีวัตถุไหม? วัตถุประเภทอะไร? กรอบของวัตถุอยู่ตรงไหน? ใช้ CNN เพื่อเรียนรู้ pattern จากรูปภาพ ประมวลผลทั้งหมดใน 1 ครั้ง ในบทความนี้ จะใช้ Python ใน Visual studio code ในการรันโค้ด และจะนำเข้าไฟล์ทั้งหมด 3 ไฟล์ นั่นคือ yolov3.weights (Download weights), yolov3.cfg (Download cfg) และ coco.names (Download names) โดยเราจะทำความรู้จักกับไฟล์ของโมเดล YOLOv3 ก่อน ดังนี้ yolov3.weights : น้ำหนักของโมเดลที่ได้รับการเทรนมาแล้ว มีรูปแบบเป็นตัวเลข (weights) ที่โมเดลได้เรียนรู้มาจากการเทรน ใช้คู่กับ yolov3.cfg เพื่อดหลดโมเดลที่ได้รับการฝึกมาแล้ว yolov3.cfg : เป็นไฟล์ text บอกว่าโมเดล YOLOv3 มี layer กี่ชั้น, แต่ละชั้นคืออะไร, ขนาด filter เท่าไหร่, stride เท่าไหร่ เอาไว้ให้ yolov3.weights เข้าไปแยกโหลดแต่ละ object coco.names : เป็นไฟล์ text รวมรายชื่อวัตถุทั้งหมดที่ YOLOv3 register เอาไว้ คล้าย ๆ พจนานุกรมให้ตัว model สามารถรู้ได้ว่าสิ่งนี้เรียกว่าอะไร เมื่อรู้จักโมเดล YOLOv3 คร่าว ๆ แล้ว ต่อมาจะเป็นการเขียนโค้ดเพื่อนำโมเดลตัวนี้มาใช้งานกัน Step 1 ทำการ import library 2 ตัว : OpenCV สำหรับโหลด/ประมวลผลภาพ และ numpy ใช้จัดการ array ต่าง ๆ import cv2 import numpy as np Step 2 โหลดโมเดล YOLOv3 จากไฟล์ที่อยู่ในโฟลเดอร์ของเรา (สองไฟล์นี้ต้องอยู่ในโฟลเดอร์เดียวกับไฟล์ python ซึ่งในบทความนี้จะอยู่ในโฟลเดอร์ yolo_project) net = cv2.dnn.readNet("yolo_project/yolov3.weights", "yolo_project/yolov3.cfg") Step 3 เปิดไฟล์ coco.names ด้วยการใช้ read mode อ่านออกมา เมื่ออ่านเสร็จแล้วจะเก็บค่าเป็น list ของ string เก็บไว้ในตัวแปรหนึ่ง เป็นการโหลดคลาสเก็บเอาไว้ with open("yolo_project/coco.names", "r") as f: classes = [line.strip() for line in f.readlines()] Step 4 เป็นการระบุว่าเราจะใช้ layer ไหนใน network สำหรับการทำนาย (yolo_82 สำหรับวัตถุขนาดใหญ่, yolo_94 สำหรับวัตถุขนาดกลาง, yolo_106 สำหรับวัตถุขนาดเล็ก) layer_names = net.getLayerNames() output_layers = [layer_names[i - 1] for i in net.getUnconnectedOutLayers()] Step 5 เป็นการโหลดภาพที่เราต้องการใช้เข้ามา โดยจะทำการย่อขนาดลงครึ่งนึงเพื่อให้โปรแกรมรันไวขึ้น จากนั้นจึงเก็บค่าความสูงและความกว้างของภาพเอาไว้ img = cv2.imread("yolo_project/test.jpg") img = cv2.resize(img, None, fx=0.5, fy=0.5) height, width, _ = img.shape Step 6 ทำการแปลงภาพให้เป็น blob เพื่อเป็น input ส่งเข้า YOLO network และเก็บข้อมูลที่ได้ไว้ใน output_layers blob = cv2.dnn.blobFromImage( img, # ภาพต้นฉบับ 0.00392, (416, 416), # ขนาดภาพที่ YOLO ต้องการ swapRB=True, # สลับจาก BGR -> RGB crop=False ) net.setInput(blob) outs = net.forward(output_layers) Step 7 เตรียมลิสต์ข้อมูลเอาไว้เก็บข้อมูล boxes = [] #จุดพิกัดของกรอบรูป confidences = [] #ความมั่นใจของการทำนาย class_ids = [] #หมายเลขคลาส ทำการวนลูปเพื่อหาผลลัพธ์จากตัวโมเดล YOLOv3 และถ้าค่า confidence มากกว่า 0.5 (ค่าความมั่นใจมากกว่า 50%) จะทำการคำนวนพิกัดที่จะทำการวาดกรอบรูปครอบวัตถุที่ตรวจจับได้ ค่า outs จะมีการบอกค่าตรงกลางแนวนอนของรูป ค่าตรงกลางแนวตั้งของรูป ค่าความกว้างของกรอบรูป และค่าความสูงของกรอบรูปด้วย จึงนำมาคำนวนหาจุดมุมบนซ้ายของรูป เพื่อนำขนาดของกรอบรูปมาวาดลงในรูปจริง โดยเริ่มจากมุมบนซ้าย for out in outs: for detection in out: scores = detection[5:] class_id = np.argmax(scores) confidence = scores[class_id] if confidence > 0.5: center_x = int(detection[0] * width) center_y = int(detection[1] * height) w = int(detection[2] * width) h = int(detection[3] * height) x = int(center_x - w / 2) y = int(center_y - h / 2) ตัวอย่างการคำนวนและวาดกรอบรูปเมื่อรูปภาพมีขนาด 480*640px และค่าความกว้างและสูงของกรอบรูป (detection[2], detection[3]) มีค่า 0.2 และ 0.4 ตามลำดับ center_x = int(0.5 * 640) = 320 #จุดกึ่งกลางรูปในแนวแกน x center_y = int(0.5 * 480) = 240 #จุดกึ่งกลางรูปในแนวแกน y w = int(0.2 * 640) = 128 h = int(0.4 * 480) = 192 x = 320 - 128/2 = 256 #ค่า x มุมบนซ้ายของกรอบ y = 240 - 192/2 = 144 #ค่า y มุมบนซ้ายของกรอบ เก็บข้อมูลเอาไว้ใน lists ที่สร้างไว้ก่อนหน้านี้ เพื่อเอาไว้ใช้วาดทีหลัง boxes.append([x, y, w, h]) confidences.append(float(confidence)) class_ids.append(class_id) Step 8 ลบกรอบซ้ำซ้อน ด้วย NMS เก็บไว้เฉพาะกรอบที่มีค่า confidence มากที่สุด indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4) แสดงใน terminal ว่าตรวจจับวัตถุอะไรได้บ้าง และกำหนดฟอนต์ที่จะใช้เขียนในรูป pri
หนึ่งในการ coding AI ที่น่าสนใจที่สุดคงหนีไม่พ้นการทำ AI ตรวจจับวัตถุในภาพ (Object Detection) โดยในบทความนี้ จะยกการใช้ Computer Vision + Deep Learning (CNN) ด้วยโมเดลที่ชื่อว่า YOLO (You Only Look Once) มาใช้ในการทำ AI coding โมเดลนี้ได้รับการฝึกฝนจากชุดข้อมูล coco เพื่อสามารถตรวจจับวัตถุหลากหลายประเภท จึงนับว่าเป็นโมเดลที่ฝึกเสร็จแล้ว และยังนับว่าโมเดลนี้เป็นแบบ Supervised Learning เพราะยังต้องมีการติดป้ายกำกับไว้ให้ว่าของชิ้นนี้คืออะไรจากชุดข้อมูล coco
ซึ่ง YOLOv3 นี้มีแนวคิดว่า
ดูภาพเพียงครั้งเดียว (You Only Look Once) แล้วตรวจจับวัตถุทั้งหมดในคราวเดียว
โดยมีขั้นตอนดังนี้
- แบ่งภาพเป็น grid
- ทุกช่องของตารางจะเป็นผู้ทำนายว่า มีวัตถุไหม? วัตถุประเภทอะไร? กรอบของวัตถุอยู่ตรงไหน?
- ใช้ CNN เพื่อเรียนรู้ pattern จากรูปภาพ
- ประมวลผลทั้งหมดใน 1 ครั้ง
ในบทความนี้ จะใช้ Python ใน Visual studio code ในการรันโค้ด และจะนำเข้าไฟล์ทั้งหมด 3 ไฟล์ นั่นคือ yolov3.weights (Download weights), yolov3.cfg (Download cfg) และ coco.names (Download names) โดยเราจะทำความรู้จักกับไฟล์ของโมเดล YOLOv3 ก่อน ดังนี้
- yolov3.weights : น้ำหนักของโมเดลที่ได้รับการเทรนมาแล้ว มีรูปแบบเป็นตัวเลข (weights) ที่โมเดลได้เรียนรู้มาจากการเทรน ใช้คู่กับ yolov3.cfg เพื่อดหลดโมเดลที่ได้รับการฝึกมาแล้ว
- yolov3.cfg : เป็นไฟล์ text บอกว่าโมเดล YOLOv3 มี layer กี่ชั้น, แต่ละชั้นคืออะไร, ขนาด filter เท่าไหร่, stride เท่าไหร่ เอาไว้ให้ yolov3.weights เข้าไปแยกโหลดแต่ละ object
- coco.names : เป็นไฟล์ text รวมรายชื่อวัตถุทั้งหมดที่ YOLOv3 register เอาไว้ คล้าย ๆ พจนานุกรมให้ตัว model สามารถรู้ได้ว่าสิ่งนี้เรียกว่าอะไร
เมื่อรู้จักโมเดล YOLOv3 คร่าว ๆ แล้ว ต่อมาจะเป็นการเขียนโค้ดเพื่อนำโมเดลตัวนี้มาใช้งานกัน
Step 1
- ทำการ import library 2 ตัว : OpenCV สำหรับโหลด/ประมวลผลภาพ และ numpy ใช้จัดการ array ต่าง ๆ
import cv2
import numpy as np
Step 2
- โหลดโมเดล YOLOv3 จากไฟล์ที่อยู่ในโฟลเดอร์ของเรา (สองไฟล์นี้ต้องอยู่ในโฟลเดอร์เดียวกับไฟล์ python ซึ่งในบทความนี้จะอยู่ในโฟลเดอร์ yolo_project)
net = cv2.dnn.readNet("yolo_project/yolov3.weights", "yolo_project/yolov3.cfg")
Step 3
- เปิดไฟล์ coco.names ด้วยการใช้ read mode อ่านออกมา เมื่ออ่านเสร็จแล้วจะเก็บค่าเป็น list ของ string เก็บไว้ในตัวแปรหนึ่ง เป็นการโหลดคลาสเก็บเอาไว้
with open("yolo_project/coco.names", "r") as f:
classes = [line.strip() for line in f.readlines()]
Step 4
- เป็นการระบุว่าเราจะใช้ layer ไหนใน network สำหรับการทำนาย (yolo_82 สำหรับวัตถุขนาดใหญ่, yolo_94 สำหรับวัตถุขนาดกลาง, yolo_106 สำหรับวัตถุขนาดเล็ก)
layer_names = net.getLayerNames()
output_layers = [layer_names[i - 1] for i in net.getUnconnectedOutLayers()]
Step 5
- เป็นการโหลดภาพที่เราต้องการใช้เข้ามา โดยจะทำการย่อขนาดลงครึ่งนึงเพื่อให้โปรแกรมรันไวขึ้น จากนั้นจึงเก็บค่าความสูงและความกว้างของภาพเอาไว้
img = cv2.imread("yolo_project/test.jpg")
img = cv2.resize(img, None, fx=0.5, fy=0.5)
height, width, _ = img.shape
Step 6
- ทำการแปลงภาพให้เป็น blob เพื่อเป็น input ส่งเข้า YOLO network และเก็บข้อมูลที่ได้ไว้ใน output_layers
blob = cv2.dnn.blobFromImage(
img, # ภาพต้นฉบับ
0.00392,
(416, 416), # ขนาดภาพที่ YOLO ต้องการ
swapRB=True, # สลับจาก BGR -> RGB
crop=False
)
net.setInput(blob)
outs = net.forward(output_layers)
Step 7
- เตรียมลิสต์ข้อมูลเอาไว้เก็บข้อมูล
boxes = [] #จุดพิกัดของกรอบรูป
confidences = [] #ความมั่นใจของการทำนาย
class_ids = [] #หมายเลขคลาส
- ทำการวนลูปเพื่อหาผลลัพธ์จากตัวโมเดล YOLOv3 และถ้าค่า confidence มากกว่า 0.5 (ค่าความมั่นใจมากกว่า 50%) จะทำการคำนวนพิกัดที่จะทำการวาดกรอบรูปครอบวัตถุที่ตรวจจับได้ ค่า outs จะมีการบอกค่าตรงกลางแนวนอนของรูป ค่าตรงกลางแนวตั้งของรูป ค่าความกว้างของกรอบรูป และค่าความสูงของกรอบรูปด้วย จึงนำมาคำนวนหาจุดมุมบนซ้ายของรูป เพื่อนำขนาดของกรอบรูปมาวาดลงในรูปจริง โดยเริ่มจากมุมบนซ้าย
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.5:
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
x = int(center_x - w / 2)
y = int(center_y - h / 2)
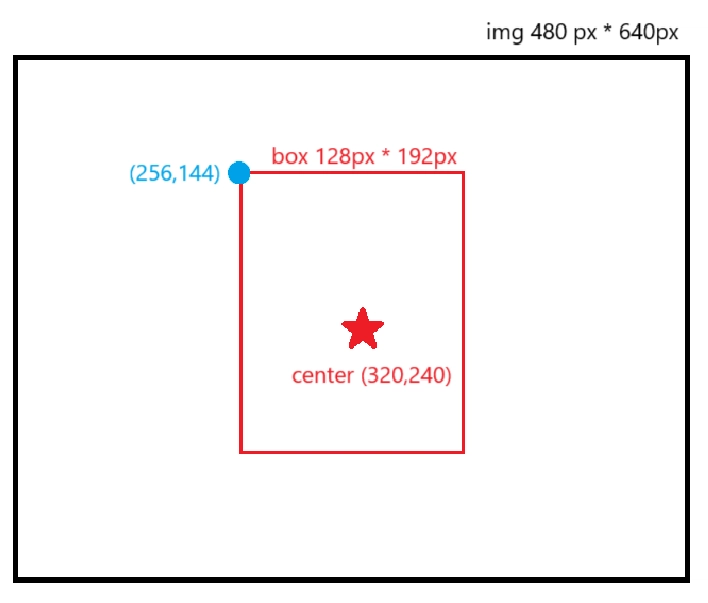
ตัวอย่างการคำนวนและวาดกรอบรูปเมื่อรูปภาพมีขนาด 480*640px และค่าความกว้างและสูงของกรอบรูป (detection[2], detection[3]) มีค่า 0.2 และ 0.4 ตามลำดับ
center_x = int(0.5 * 640) = 320 #จุดกึ่งกลางรูปในแนวแกน x
center_y = int(0.5 * 480) = 240 #จุดกึ่งกลางรูปในแนวแกน y
w = int(0.2 * 640) = 128
h = int(0.4 * 480) = 192
x = 320 - 128/2 = 256 #ค่า x มุมบนซ้ายของกรอบ
y = 240 - 192/2 = 144 #ค่า y มุมบนซ้ายของกรอบ
- เก็บข้อมูลเอาไว้ใน lists ที่สร้างไว้ก่อนหน้านี้ เพื่อเอาไว้ใช้วาดทีหลัง
boxes.append([x, y, w, h])
confidences.append(float(confidence))
class_ids.append(class_id)
Step 8
- ลบกรอบซ้ำซ้อน ด้วย NMS เก็บไว้เฉพาะกรอบที่มีค่า confidence มากที่สุด
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
- แสดงใน terminal ว่าตรวจจับวัตถุอะไรได้บ้าง และกำหนดฟอนต์ที่จะใช้เขียนในรูป
print("Detected Object:")
font = cv2.FONT_HERSHEY_SIMPLEX
- วนลูปการลบกรอบด้วย NMS และวาดกรอบ ใส่ชื่อวัตถุ ใส่ค่าความมั่นใจ และแสดงชื่อวัตถุใน terminal
for i in range(len(boxes)):
if i in indexes:
x, y, w, h = boxes[i]
label = f"{classes[class_ids[i]]} ({confidences[i]:.2f})"
color = (0, 255, 0)
cv2.rectangle(img, (x, y), (x + w, y + h), color, 2)
cv2.putText(img, label, (x, y + 20), font, 0.6, color, 2)
#แสดงใน Terminal
print(f"- {label}")
Step 9
- บันทึกรูปภาพที่วาดเสร็จแล้วลงในโฟลเดอร์ และบอกใน terminal ว่าบันทึกเป็นชื่ออะไร
cv2.imwrite("output.jpg", img)
print("\n Save As: output.jpg")
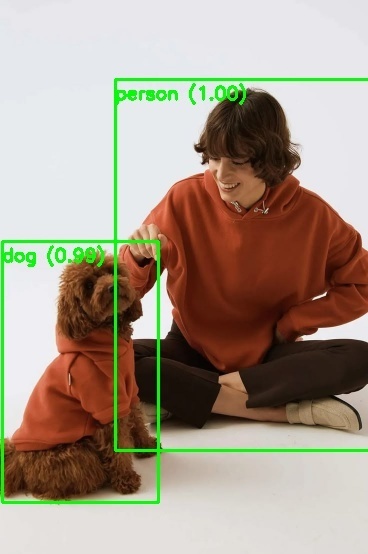
ตัวอย่างที่ได้จากการรันจะเป็นดังนี้
- รูปต้นฉบับ

- รูปที่ได้จากการรัน
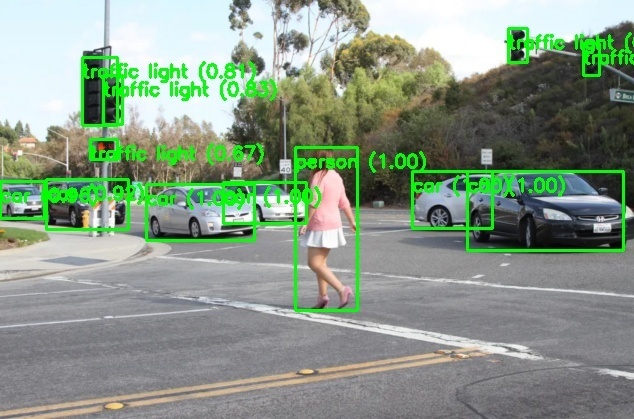
ถ้าเราใช้รูปที่มีความซับซ้อนกว่าเดิม จะเป็นดังนี้
- รูปต้นฉบับ

- รูปที่ได้จากการรัน
สรุป
ในบทความนี้ เราได้ลองใช้ YOLOv3 ในการเขียนโค้ดตรวจจับวัตถุบนภาพ และเมื่อลองเปลี่ยนรูปภาพก็ยังสามารถตรวจจับได้อยู่ แต่มีเงื่อนไขว่าวัตถุนั้นจะต้องมีข้อมูลอยู่ในชุดข้อมูล coco เพื่อตัวโมเดลจะได้ตรวจจับได้
References
Create Object Detection Model Using Python & Open CV
A Beginner’s Guide to Object Detection in Python
zip file (open in visual studio code)