

















































































































































































![How to Build an AI Assistant with Keith Moehring [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/MAICON-Speaker_Series%20%281%29.png)
![[The AI Show Episode 156]: AI Answers - Data Privacy, AI Roadmaps, Regulated Industries, Selling AI to the C-Suite & Change Management](https://www.marketingaiinstitute.com/hubfs/ep%20156%20cover.png)
![[The AI Show Episode 155]: The New Jobs AI Will Create, Amazon CEO: AI Will Cut Jobs, Your Brain on ChatGPT, Possible OpenAI-Microsoft Breakup & Veo 3 IP Issues](https://www.marketingaiinstitute.com/hubfs/ep%20155%20cover.png)








































































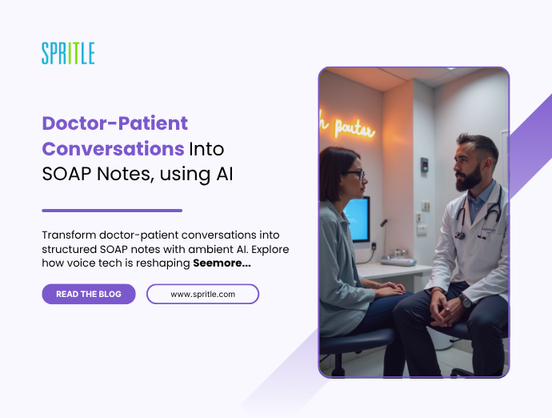




































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

























_Michael_Burrell_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)












































































































































































Kubernetes: Handling Crashes, Scaling, and Rollbacks
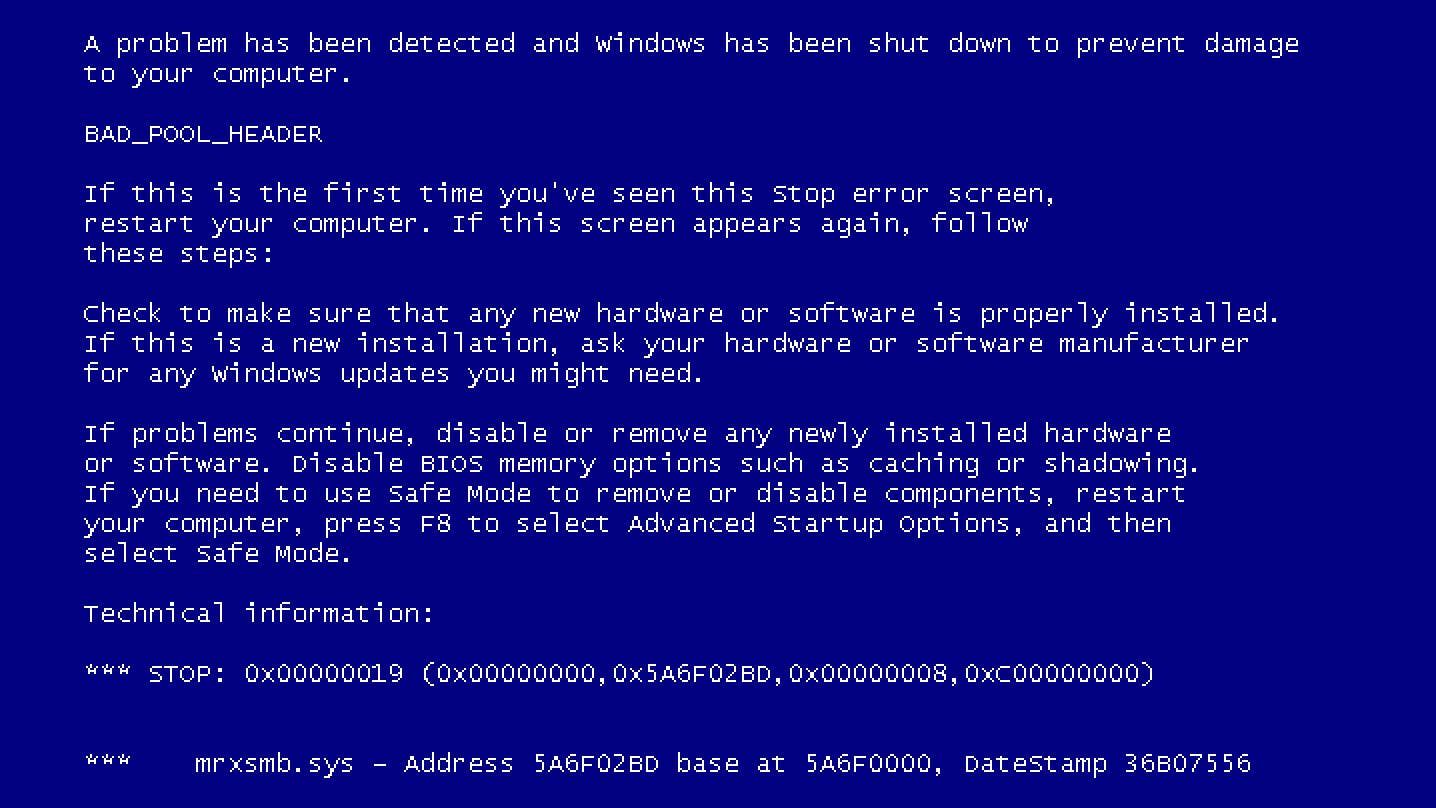
In today's fast-paced application landscape, maintaining continuous availability while seamlessly deploying updates is non-negotiable. Kubernetes, the leading container orchestration platform, rises to this challenge with a powerful suite of features. As we explored in our previous article, 'Understanding Kubernetes Objects and Deployment Process', we laid the groundwork by understanding the core Kubernetes Objects and the fundamental deployment mechanism. Now, let's build upon that knowledge and delve deeper into how Kubernetes ensures your applications remain highly available and can dynamically scale to meet any demand. Container Crash Coverage: Self-Healing in Action Imagine a scenario where an unexpected error causes a container within your application to fail. In traditional setups, this could lead to downtime and require manual intervention. However, Kubernetes actively monitors the health of your application pods. If a container crashes, Kubernetes detects this failure and automatically takes action to restore the desired state. Consider a web application where a specific endpoint, say /error, is intentionally designed to trigger a crash for demonstration purposes. If we attempt to access this endpoint and then quickly check the status of our pods using the command: kubectl get pods You'll likely observe that the pod containing the crashed container is in the process of being restarted. Kubernetes ensures that the desired number of replicas for your application is always running. This self-healing mechanism significantly enhances application reliability and reduces the impact of individual container failures. Auto Scaling: Maintaining Availability Under Load Beyond individual container failures, applications often experience fluctuating traffic demands. Kubernetes offers powerful auto-scaling capabilities to handle these variations gracefully. By configuring horizontal pod autoscaling (HPA), Kubernetes can automatically adjust the number of pod replicas based on metrics like CPU utilization or custom application metrics. For instance, if we initially have a deployment named first-app running with a single replica: kubectl scale deployment/first-app --replicas=1 And then we decide to increase the desired number of replicas to three: kubectl scale deployment/first-app --replicas=3 Kubernetes will spin up two additional instances of our application. Now, if one of these containers were to crash, the incoming traffic would be seamlessly routed to the remaining healthy instances, ensuring continuous service availability. This built-in load balancing and failover mechanism is a cornerstone of resilient application deployments. Streamlined Updates: Deploying Changes with Confidence Deploying new versions of your application is a frequent necessity. Kubernetes simplifies this process with its rolling update strategy. This approach allows you to update your application without any downtime. Instead of abruptly stopping all old instances and starting new ones, Kubernetes gradually replaces the old pods with new ones, ensuring that a sufficient number of replicas are always available to serve traffic. Let's say we've built a new version of our first-app and tagged the Docker image as mayankcse1/kub-first-app:2. To deploy this new version, we first push the image to our container registry: docker build -t mayankcse1/kub-first-app:2 . docker push mayankcse1/kub-first-app:2 Then, we instruct Kubernetes to update the deployment to use this new image: kubectl set image deployment/first-app kub-first-app=mayankcse1/kub-first-app:2 Finally, we can monitor the rollout status: kubectl rollout deployment/first-app Kubernetes will perform a rolling update, gradually replacing the old pods with the new ones. This ensures a zero-downtime deployment, providing a smooth experience for your users. Effortless Rollbacks: Recovering from Problematic Deployments Despite rigorous testing, sometimes a new deployment might introduce unforeseen issues. Kubernetes provides a straightforward way to rollback to a previous stable version. If we encounter problems with our latest deployment, we can easily revert to the previous version using the command: kubectl rollout undo deployment/first-app Kubernetes keeps a history of your deployment revisions, allowing you to go back to any previous stable state. To view the deployment history, you can use: kubectl rollout history deployment/first-app This will list the revision history of your deployment. If you need to rollback to a specific older revision, for example, revision number 1, you can use: kubectl rollout undo deployment/first-app --to-revision=1 This ability to quickly rollback problematic deployments is invaluable for maintaining application stability and minimizing the impact of faulty releases. Conclusion: Kubernetes – Your Partner in Relia

In today's fast-paced application landscape, maintaining continuous availability while seamlessly deploying updates is non-negotiable. Kubernetes, the leading container orchestration platform, rises to this challenge with a powerful suite of features. As we explored in our previous article, 'Understanding Kubernetes Objects and Deployment Process', we laid the groundwork by understanding the core Kubernetes Objects and the fundamental deployment mechanism. Now, let's build upon that knowledge and delve deeper into how Kubernetes ensures your applications remain highly available and can dynamically scale to meet any demand.
Container Crash Coverage: Self-Healing in Action
Imagine a scenario where an unexpected error causes a container within your application to fail. In traditional setups, this could lead to downtime and require manual intervention. However, Kubernetes actively monitors the health of your application pods. If a container crashes, Kubernetes detects this failure and automatically takes action to restore the desired state.
Consider a web application where a specific endpoint, say /error, is intentionally designed to trigger a crash for demonstration purposes. If we attempt to access this endpoint and then quickly check the status of our pods using the command:
kubectl get pods
You'll likely observe that the pod containing the crashed container is in the process of being restarted. Kubernetes ensures that the desired number of replicas for your application is always running. This self-healing mechanism significantly enhances application reliability and reduces the impact of individual container failures.
Auto Scaling: Maintaining Availability Under Load
Beyond individual container failures, applications often experience fluctuating traffic demands. Kubernetes offers powerful auto-scaling capabilities to handle these variations gracefully. By configuring horizontal pod autoscaling (HPA), Kubernetes can automatically adjust the number of pod replicas based on metrics like CPU utilization or custom application metrics.
For instance, if we initially have a deployment named first-app running with a single replica:
kubectl scale deployment/first-app --replicas=1
And then we decide to increase the desired number of replicas to three:
kubectl scale deployment/first-app --replicas=3
Kubernetes will spin up two additional instances of our application. Now, if one of these containers were to crash, the incoming traffic would be seamlessly routed to the remaining healthy instances, ensuring continuous service availability. This built-in load balancing and failover mechanism is a cornerstone of resilient application deployments.
Streamlined Updates: Deploying Changes with Confidence
Deploying new versions of your application is a frequent necessity. Kubernetes simplifies this process with its rolling update strategy. This approach allows you to update your application without any downtime. Instead of abruptly stopping all old instances and starting new ones, Kubernetes gradually replaces the old pods with new ones, ensuring that a sufficient number of replicas are always available to serve traffic.
Let's say we've built a new version of our first-app and tagged the Docker image as mayankcse1/kub-first-app:2. To deploy this new version, we first push the image to our container registry:
docker build -t mayankcse1/kub-first-app:2 .
docker push mayankcse1/kub-first-app:2
Then, we instruct Kubernetes to update the deployment to use this new image:
kubectl set image deployment/first-app kub-first-app=mayankcse1/kub-first-app:2
Finally, we can monitor the rollout status:
kubectl rollout deployment/first-app
Kubernetes will perform a rolling update, gradually replacing the old pods with the new ones. This ensures a zero-downtime deployment, providing a smooth experience for your users.
Effortless Rollbacks: Recovering from Problematic Deployments
Despite rigorous testing, sometimes a new deployment might introduce unforeseen issues. Kubernetes provides a straightforward way to rollback to a previous stable version. If we encounter problems with our latest deployment, we can easily revert to the previous version using the command:
kubectl rollout undo deployment/first-app
Kubernetes keeps a history of your deployment revisions, allowing you to go back to any previous stable state. To view the deployment history, you can use:
kubectl rollout history deployment/first-app
This will list the revision history of your deployment. If you need to rollback to a specific older revision, for example, revision number 1, you can use:
kubectl rollout undo deployment/first-app --to-revision=1
This ability to quickly rollback problematic deployments is invaluable for maintaining application stability and minimizing the impact of faulty releases.
Conclusion: Kubernetes – Your Partner in Reliable Application Management
The features discussed above – automatic container restarts, auto-scaling, seamless rolling updates, and effortless rollbacks – highlight the power and sophistication of Kubernetes. These capabilities significantly simplify the complexities of managing modern, containerized applications, ensuring high availability, resilience to failures, and a smooth path for continuous delivery. Kubernetes truly empowers developers and operations teams to focus on building and delivering value, rather than being bogged down by infrastructure management challenges.


