










































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)
































































































































![Ditching a Microsoft Job to Enter Startup Purgatory with Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)





























































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)


























































































































































-xl.jpg)




























![New iPad 11 (A16) On Sale for Just $277.78! [Lowest Price Ever]](https://www.iclarified.com/images/news/97273/97273/97273-640.jpg)

![Apple Foldable iPhone to Feature New Display Tech, 19% Thinner Panel [Rumor]](https://www.iclarified.com/images/news/97271/97271/97271-640.jpg)



























































































Dealing with Mountains of Data: Why Just Buying a Bigger Hard Drive Won't Cut It
Large scale applications have large amounts of data. I'm not talking about a few gigabytes or terabytes, rather petabytes of data. Although 30TB hard drives might be a thing now (Thanks Seagate! [https://www.techradar.com/pro/seagate-confirms-that-30tb-hard-drives-are-coming-in-early-2024-but-you-probably-wont-be-able-to-use-it-in-your-pc]), they simply don't suffice for these truly large-scale applications. Let's take Instagram for example: They probably have a user table that resembles something like this (If you are a dev from Meta reading this and this is exactly how your table looks, I'm a Genius! I leaked your user data!!!! Evil laugh) user_id user_name phone_number 1 user1 12269765432 2 user2 12269765432 3 user3 12269765432 Coming back to the topic, this user data of 3 rows seems pretty harmless, right? RIGHT! But now imagine 2 billion of these records (Yes, that's how many of you are spending time scrolling, including you reading this article, I see you!). If each row takes around 10KB to store (Just an arbitrary value, don't sue me!), the 3 rows would barely take 30KB. However, for 2 billion, that's a whole other story. Size per row: 10 KB Number of rows: 2 billion (2,000,000,000) Total size = Size per row × Number of rows Total size = 10 KB/row × 2,000,000,000 rows Total size = 20,000,000,000 KB Yeah, I'm not reading that number out loud, but I think we both can agree that it's a lot! Much larger than a single hard disk can store! Oh, you don't believe me? Fine, take more numbers, that might help: 1 MB = 1024 KB 1 GB = 1024 MB 1 TB = 1024 GB 1 PB = 1024 TB Total size in MB = 20,000,000,000 KB / 1024 ≈ 19,531,250 MB Total size in GB = 19,531,250 MB / 1024 ≈ 19,073 GB Total size in TB = 19,073 GB / 1024 ≈ 18.63 TB (Terabytes) Total size in PB = 18.63 TB / 1024 ≈ 0.018 PB (Petabytes) Now I hope we are both on the same page (both figuratively and literally). Okay, but hypothetically, what if some genie or a magician waves a magic wand and we now have a disk that can store such large amounts of data? It would still not solve all our problems. We would now have a SPOF (you read that right, not SPF you skincare freaks!) – A SINGLE POINT OF FAILURE. If that one giant disk fails, your entire application is down. Game over. At this point, you might be thinking, "Hey Hayden, why are you telling me this? I already have enough problems in my life!" I'll let my buddy Dan answer that: Dan Martell’s : "A problem well defined is a problem half solved." See, he's the best! Now, back to our topic! We have two main problems: 1) No single disk large enough to hold the large amount of data. 2) We do not want a single point of failure. If you're jumping up right now with the answer, give yourself a pat on the back! Yes, the solution is: why don't we have multiple copies of the database? That would fix the issue with a single point of failure, right? But wait, we can't just duplicate the entire dataset, right? Since it doesn't fit on one disk to begin with! So, we have to divide (partition) the data across multiple databases or servers. And yes, that's our answer: Partitioning / Sharding. You've probably heard this before, but I hope that you now understand the crucial use case as to why it's required for large-scale applications. Now, let's come back to the topic of how we divide this data. We could shard or partition the database using multiple strategies. One approach would be partitioning users based on their region. For example, users from the US could be written to a database server located in the US, the same for EU or APAC (Asia Pacific for those of you who do not know). The merits of this would be: Reduced Latency: Since the servers are located closer to the users, query time would generally be faster. Easier Compliance: Data can be stored within specific geographical boundaries, helping with data residency regulations. However, nothing is always a bed of roses, right? What happens if a user moves from one region to another? Or how about regions where traffic is significantly higher than others? There are a lot of other issues that we could go into with regional partitioning (like complex cross-region queries). But coming to the point that got me writing this blog in the first place: Hashing, Consistent Hashing to be more precise. Yes, we could divide and partition the databases according to the user's region, but what if we had something smarter decide which partition a user's record should be written to? It takes the username, user ID, phone number and, voila, tells you that you belong to partition 2. All hail our AI overlords! Just kidding (riding on the AI hype, lol!), we do not need AI for this. We have something very cool: Hash Functions! If you are a CS major or know a thing or two about crypto, you've probably heard phrases like these associated with hash functions: Deterministic Efficient to Compute Uniform Distribution You know who could
Large scale applications have large amounts of data. I'm not talking about a few gigabytes or terabytes, rather petabytes of data. Although 30TB hard drives might be a thing now (Thanks Seagate! [https://www.techradar.com/pro/seagate-confirms-that-30tb-hard-drives-are-coming-in-early-2024-but-you-probably-wont-be-able-to-use-it-in-your-pc]), they simply don't suffice for these truly large-scale applications.
Let's take Instagram for example:
They probably have a user table that resembles something like this (If you are a dev from Meta reading this and this is exactly how your table looks, I'm a Genius! I leaked your user data!!!! Evil laugh)
| user_id | user_name | phone_number |
|---|---|---|
| 1 | user1 | 12269765432 |
| 2 | user2 | 12269765432 |
| 3 | user3 | 12269765432 |
Coming back to the topic, this user data of 3 rows seems pretty harmless, right? RIGHT! But now imagine 2 billion of these records (Yes, that's how many of you are spending time scrolling, including you reading this article, I see you!). If each row takes around 10KB to store (Just an arbitrary value, don't sue me!), the 3 rows would barely take 30KB. However, for 2 billion, that's a whole other story.
Size per row: 10 KB
Number of rows: 2 billion (2,000,000,000)
Total size = Size per row × Number of rows
Total size = 10 KB/row × 2,000,000,000 rows
Total size = 20,000,000,000 KB
Yeah, I'm not reading that number out loud, but I think we both can agree that it's a lot! Much larger than a single hard disk can store!
Oh, you don't believe me? Fine, take more numbers, that might help:
1 MB = 1024 KB
1 GB = 1024 MB
1 TB = 1024 GB
1 PB = 1024 TB
Total size in MB = 20,000,000,000 KB / 1024 ≈ 19,531,250 MB
Total size in GB = 19,531,250 MB / 1024 ≈ 19,073 GB
Total size in TB = 19,073 GB / 1024 ≈ 18.63 TB (Terabytes)
Total size in PB = 18.63 TB / 1024 ≈ 0.018 PB (Petabytes)
Now I hope we are both on the same page (both figuratively and literally).
Okay, but hypothetically, what if some genie or a magician waves a magic wand and we now have a disk that can store such large amounts of data?
It would still not solve all our problems. We would now have a SPOF (you read that right, not SPF you skincare freaks!) – A SINGLE POINT OF FAILURE. If that one giant disk fails, your entire application is down. Game over.
At this point, you might be thinking, "Hey Hayden, why are you telling me this? I already have enough problems in my life!"
I'll let my buddy Dan answer that:
Dan Martell’s : "A problem well defined is a problem half solved."
See, he's the best!
Now, back to our topic! We have two main problems:
1) No single disk large enough to hold the large amount of data.
2) We do not want a single point of failure.
If you're jumping up right now with the answer, give yourself a pat on the back! Yes, the solution is: why don't we have multiple copies of the database? That would fix the issue with a single point of failure, right? But wait, we can't just duplicate the entire dataset, right? Since it doesn't fit on one disk to begin with!
So, we have to divide (partition) the data across multiple databases or servers.
And yes, that's our answer: Partitioning / Sharding.
You've probably heard this before, but I hope that you now understand the crucial use case as to why it's required for large-scale applications.
Now, let's come back to the topic of how we divide this data. We could shard or partition the database using multiple strategies.
One approach would be partitioning users based on their region. For example, users from the US could be written to a database server located in the US, the same for EU or APAC (Asia Pacific for those of you who do not know).
The merits of this would be:
- Reduced Latency: Since the servers are located closer to the users, query time would generally be faster.
- Easier Compliance: Data can be stored within specific geographical boundaries, helping with data residency regulations.
However, nothing is always a bed of roses, right? What happens if a user moves from one region to another? Or how about regions where traffic is significantly higher than others? There are a lot of other issues that we could go into with regional partitioning (like complex cross-region queries).
But coming to the point that got me writing this blog in the first place: Hashing, Consistent Hashing to be more precise.
Yes, we could divide and partition the databases according to the user's region, but what if we had something smarter decide which partition a user's record should be written to? It takes the username, user ID, phone number and, voila, tells you that you belong to partition 2. All hail our AI overlords! Just kidding (riding on the AI hype, lol!), we do not need AI for this. We have something very cool: Hash Functions!
If you are a CS major or know a thing or two about crypto, you've probably heard phrases like these associated with hash functions:
- Deterministic
- Efficient to Compute
- Uniform Distribution
You know who could really benefit from these attributes? Yes, Databases! (You are so smart, light pat on your head!)
Okay, let's say we give the hash function a few attributes from our user table. If you ask why more than one (don't worry, we'll get back to that later).
Hashing:
Hash(user_id, user_name, phone_number) -> SomeUniqueOrSemiUniqueHashValue
Now the question is, how do we take this SomeUniqueOrSemiUniqueHashValue and map that to a database partition? Do you remember how we might make a circular array? Yes, that's the modulo (%) operator!
So, if we had 10 servers (or partitions), we could simply take the SomeUniqueOrSemiUniqueHashValue % 10, which would give us an output between 0 and 9 (since 10 % 10 = 0).
If SomeUniqueOrSemiUniqueHashValue % 10 returned 2, we would simply insert the user record in partition 2. Easy peasy!
Coming back to the point on why we are giving 3 attributes instead of just 1 to the hash function:
Using a combination of attributes like user_id, user_name, and phone_number can contribute to a more uniform distribution of hash values. If we only used user_id and they were assigned sequentially, we might still end up with hot spots as new users are constantly being added to a specific range of IDs. By including other attributes, we increase the entropy and randomness of the hash output, which helps in distributing the data more evenly across the partitions. It's like mixing colors to get a more complex and evenly spread shade.
Now, let me throw the curveball! Are you ready?
Let's say our user base grows 10x tomorrow. That would mean we would have to add more database servers, right? And that would also mean that our calculation SomeUniqueOrSemiUniqueHashValue % N, where N was initially 10, would change to something more like 20.
So, if SomeUniqueOrSemiUniqueHashValue % 10 returned 2 earlier, SomeUniqueOrSemiUniqueHashValue % 20 might not necessarily return 2. It could return 3, 4, 5, or any other number. You get my point?
Let's maybe run through an example:
When you change N to a new number (N_new), the result of the modulo operation (hash() % N_new) will be different for almost every existing piece of data.
Imagine you have 4 partitions (N=4) and a user's data hashes to 10. 10 % 4 = 2, so their data is in Partition 2.
Now, you add 4 more partitions, so you have 8 (N_new=8). The same user's data with the hash 10 would now be assigned to 10 % 8 = 2. In this specific case, the partition number is the same, but this is purely coincidental.
Consider another user whose data hashes to 11. With 4 partitions, 11 % 4 = 3, so their data is in Partition 3. With 8 partitions, 11 % 8 = 3. Still the same.
Okay, let's try a hash of 13. With 4 partitions, 13 % 4 = 1. With 8 partitions, 13 % 8 = 5. This user's data needs to move from Partition 1 to Partition 5.
How about a hash of 14? With 4 partitions, 14 % 4 = 2. With 8 partitions, 14 % 8 = 6. This user's data needs to move from Partition 2 to Partition 6.
As you can see, a significant portion of your data would need to be re-calculated and moved to a different partition whenever you change the number of nodes. This process, known as rehashing, is very disruptive, resource-intensive, and can lead to significant downtime for your application while the data is being migrated. Not ideal for a system that needs to be available 24/7!
Consistent Hashing (Our Superhero!)
So, you see the problem, right? Simple hashing with that % operator is like trying to organize a growing party where every time a new guest arrives or someone leaves, you have to ask everyone to move to a completely new spot. Chaos!
Consistent Hashing walks in, puts on its cape, and says, "Hold my perfectly distributed data." It tackles this rehashing headache with a fundamentally different approach.
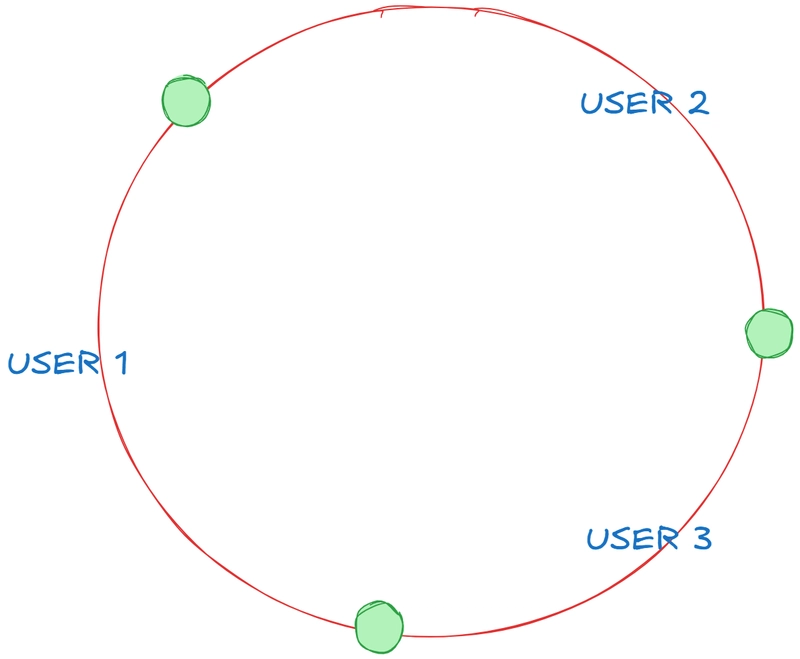
Instead of thinking about servers numbered 0 to N, imagine a ring. A giant, conceptual ring representing the space of all possible hash values. We take our hash function – that cool, deterministic one that takes your user_id, user_name, phone_number, and spits out a value – and we use that same function to map both our users (data) and our database servers (nodes) onto this ring.
So, your user data hashes to a point on the ring, and each of your database servers also hashes to one or more points on this same ring.
Now, when we want to store or find a user's data, we take their hash value, find its spot on the ring, and then we move clockwise around the ring until we hit the first server node. That server node is where that user's data lives.
Think of the ring like a timeline or a sorted list of all possible hash values. Each server is responsible for a segment of that ring, from the last server it encountered going counter-clockwise, up to its own position.
Okay, superhero time! What happens when we need to add a new database server? We hash our new server, and place it onto the ring at its hash position. This new server now takes responsibility for a section of the ring that was previously handled by the server immediately clockwise to it.
And here's the magic: Only the data keys that fall into that specific segment of the ring that the new server just claimed need to move! All the other users, whose hash values land in segments of the ring not affected by the new server's arrival, stay exactly where they are. No mass migration needed!
Similarly, if a server has to leave the ring (sad face, maybe it retired), the server immediately clockwise to the departing server on the ring simply takes over the range of hash values that the old server was responsible for. Again, only the data from the leaving server needs to be moved to its new neighbor.
This is why consistent hashing is crucial in building massively scalable and resilient distributed systems. It allows us to grow or shrink our database infrastructure without causing an application-wide meltdown. It's the unsung hero keeping your favorite large-scale apps running smoothly as their data (and user base!) explodes.



