







































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)



















































































































































![Am I responsible for data which is being sent but not stored? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)





















































































































.png?#)


































































































![Apple Posts Full First Episode of 'Your Friends & Neighbors' on YouTube [Video]](https://www.iclarified.com/images/news/96990/96990/96990-640.jpg)

![Apple May Implement Global iPhone Price Increases to Mitigate Tariff Impacts [Report]](https://www.iclarified.com/images/news/96987/96987/96987-640.jpg)
![Apple Aims to Launch Revamped Siri This Fall After AI Setbacks [Report]](https://www.iclarified.com/images/news/96984/96984/96984-640.jpg)































































![[Weekly funding roundup April 5-11] VC inflows into Indian startups remain subdued](https://images.yourstory.com/cs/2/220356402d6d11e9aa979329348d4c3e/WeeklyFundingRoundupNewLogo1-1739546168054.jpg)























































Centralized log collection in python
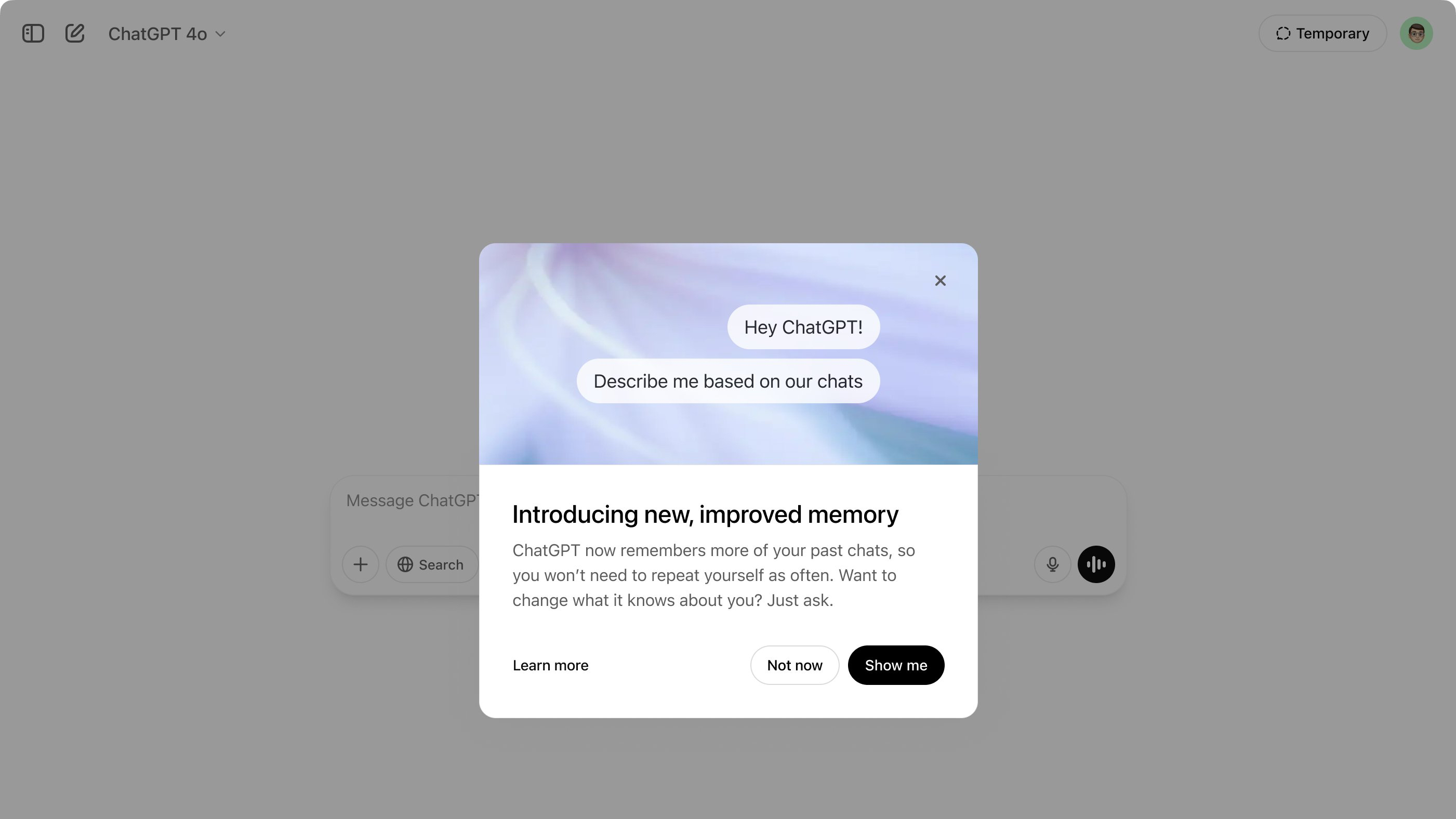
With this project I wanted to create a PoC of a centralized logging system. In the project where I used this solution Elasticsearch or other "external" centralized log collection was not an option and I had to handle multiple outputs like console, file and for certain logs a database. In the project I was working on I had multiple processes running so I had to find a way to write all the logs into file / database without any race condition. So my solution was this create a centralized logging server that would receive logs from multiple clients and handle them to run a separated server process that would handle the logs. The code is on GitHub, you can read it throuhg: https://github.com/kubenetic/centralized-logging How Everything Works Together The Server: It starts at startup and listens for incoming connections from clients. Parses the incoming data, converts it to a log record and send through the appropriate log handlers. The Client: It sends log records to the server using a socket handler. Handlers: I used in this PoC Pythons original logging handlers: StreamHandler and FileHandler to write logs out and the SocketHandler to send logs to the server. Why Use This Architecture? Scalability: The server can handle logs from multiple processes or systems, centralizing the log collection. Flexibility: You can add custom handlers on the server (e.g., write logs to a database, send alerts, etc.). Decoupling: The client processes only need to send logs, without worrying about the details of log handling. logging.handlers.SocketHandler The logging server is a standard TCP server that listens for incoming connections from clients. The clients send log data with the SocketHandler as I described above. It sends the data in binary format. The first 4 bytes contains the length of the log record, followed by the serialized log record. What is that >L format in Python's struct module? The >L format in Python's struct module is a format specifier used for packing and unpacking binary data. It specifies the byte order, data type, and size of the data to be packed or unpacked. Breaking Down >L The character > specifies the byte order (also called endianness). '>' means big-endian (most significant byte first). 'L', value) print(f"Packed: {packed}") # Output: b'\x00\x00\x04\x00' # Unpack it back to an integer unpacked = struct.unpack('>L', packed) print(f"Unpacked: {unpacked[0]}") # Output: 1024 Explanation: # Converts the integer 1024 to its big-endian binary representation. # Binary representation of 1024 is 0x00000400 (4 bytes). # Output: b'\x00\x00\x04\x00'. struct.pack('>L', 1024): # Converts the binary data back to the original integer 1024. struct.unpack('>L', b'\x00\x00\x04\x00'): Use in the Logging Server As you can see in the codesnippet below the server receives the length of the log record first, then the data itself. The length is unpacked using struct.unpack('>L', length_of_data)[0] to get the actual length of the data. The data is then received and deserialized using pickle.loads(). The log record is then created using logging.makeLogRecord() and emitted to the log handlers. length_of_data = connection.recv(4) if not length_of_data: break length = struct.unpack('>L', length_of_data)[0] log_data = connection.recv(length) if not log_data: break log_data = pickle.loads(log_data) log_record = logging.makeLogRecord(log_data) for handler in self._handlers: handler.emit(log_record)
With this project I wanted to create a PoC of a centralized logging system. In the project where I used this solution
Elasticsearch or other "external" centralized log collection was not an option and I had to handle multiple outputs
like console, file and for certain logs a database. In the project I was working on I had multiple processes running
so I had to find a way to write all the logs into file / database without any race condition.
So my solution was this create a centralized logging server that would receive logs from multiple clients and handle
them to run a separated server process that would handle the logs.
The code is on GitHub, you can read it throuhg: https://github.com/kubenetic/centralized-logging
How Everything Works Together
- The Server: It starts at startup and listens for incoming connections from clients. Parses the incoming data, converts it to a log record and send through the appropriate log handlers.
- The Client: It sends log records to the server using a socket handler.
- Handlers: I used in this PoC Pythons original logging handlers: StreamHandler and FileHandler to write logs out and the SocketHandler to send logs to the server.
Why Use This Architecture?
- Scalability: The server can handle logs from multiple processes or systems, centralizing the log collection.
- Flexibility: You can add custom handlers on the server (e.g., write logs to a database, send alerts, etc.).
- Decoupling: The client processes only need to send logs, without worrying about the details of log handling.
logging.handlers.SocketHandler
The logging server is a standard TCP server that listens for incoming connections from clients. The clients send log data
with the SocketHandler as I described above. It sends the data in binary format. The first 4 bytes contains the length of
the log record, followed by the serialized log record.
What is that >L format in Python's struct module?
The >L format in Python's struct module is a format specifier used for packing and unpacking binary data. It specifies
the byte order, data type, and size of the data to be packed or unpacked.
Breaking Down >L
The character > specifies the byte order (also called endianness).
- '>' means big-endian (most significant byte first).
- '<' would mean little-endian (the least significant byte first).
Big-endian and little-endian define how multibyte data is stored in memory. For example, the number 0x12345678 would
be stored as:
- Big-endian: 0x12 0x34 0x56 0x78
- Little-endian: 0x78 0x56 0x34 0x12
L: Specifies the data type that is an unsigned long integer (typically 4 bytes on most platforms). The value will be
packed or unpacked as a 4-byte binary representation.
What It Does
- When used with
struct.pack(), it converts a Python integer into a 4-byte binary representation in big-endian order. - When used with
struct.unpack(), it converts a 4-byte binary representation in big-endian order back into a Python integer.
Example
import struct
value = 1024
# Pack the integer (big-endian, unsigned long)
packed = struct.pack('>L', value)
print(f"Packed: {packed}") # Output: b'\x00\x00\x04\x00'
# Unpack it back to an integer
unpacked = struct.unpack('>L', packed)
print(f"Unpacked: {unpacked[0]}") # Output: 1024
Explanation:
# Converts the integer 1024 to its big-endian binary representation.
# Binary representation of 1024 is 0x00000400 (4 bytes).
# Output: b'\x00\x00\x04\x00'.
struct.pack('>L', 1024):
# Converts the binary data back to the original integer 1024.
struct.unpack('>L', b'\x00\x00\x04\x00'):
Use in the Logging Server
As you can see in the codesnippet below the server receives the length of the log record first, then the data itself.
The length is unpacked using struct.unpack('>L', length_of_data)[0] to get the actual length of the data. The data is
then received and deserialized using pickle.loads(). The log record is then created using logging.makeLogRecord() and
emitted to the log handlers.
length_of_data = connection.recv(4)
if not length_of_data:
break
length = struct.unpack('>L', length_of_data)[0]
log_data = connection.recv(length)
if not log_data:
break
log_data = pickle.loads(log_data)
log_record = logging.makeLogRecord(log_data)
for handler in self._handlers:
handler.emit(log_record)



