










































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)






























































































































![Ditching a Microsoft Job to Enter Startup Purgatory with Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)




























































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)































































![T-Mobile discontinues a free number feature but a paid alternative exists [UPDATED]](https://m-cdn.phonearena.com/images/article/170235-two/T-Mobile-discontinues-a-free-number-feature-but-a-paid-alternative-exists-UPDATED.jpg?#)
![Apple's 11th Gen iPad Drops to New Low Price of $277.78 on Amazon [Updated]](https://images.macrumors.com/t/yQCVe42SNCzUyF04yj1XYLHG5FM=/2500x/article-new/2025/03/11th-gen-ipad-orange.jpeg)
![Beats Studio Buds + On Sale for $99.95 [Lowest Price Ever]](https://www.iclarified.com/images/news/96983/96983/96983-640.jpg)





























































































-xl.jpg)




























![New iPad 11 (A16) On Sale for Just $277.78! [Lowest Price Ever]](https://www.iclarified.com/images/news/97273/97273/97273-640.jpg)










































![[Exclusive] Infinix GT DynaVue: a Prototype that could change everything!](https://www.gizchina.com/wp-content/uploads/images/2025/05/Screen-Shot-2025-05-10-at-16.07.40-PM-copy.png)



















































Attention Crisis: The 85% Dead Neuron Problem in Modern Transformers
Introduction What began as a satirical thought experiment in "Attention? You Don't Need It" has evolved into a groundbreaking discovery that challenges the foundation of modern AI. Our ElasticFourierTransformer (EFT) doesn't merely offer an alternative to conventional architectures—it exposes a catastrophic inefficiency hidden at the heart of transformer design. Through rigorous neural autopsy, we've uncovered that up to 85% of neurons in critical self-attention layers contribute nothing to model performance, revealing why our spectral approach achieves superior results with more efficient computation. 1. Neural Autopsy: Revealing What Accuracy Metrics Hide Traditional evaluation metrics have blinded us to the internal wastage of modern architectures. Our comprehensive neural autopsy framework pierces this veil by examining three critical dimensions: Generalization Capacity: Quantifying the true learning-memorization balance Neuronal Importance: Mapping the flow of decision-making power Dead Neuron Detection: Identifying computational resources wasted on inactive pathways These diagnostics expose the hidden reality of transformer inefficiency that performance benchmarks systematically obscure. 2. The Generalization Crisis in Standard Transformers Our experiments reveal a shocking disparity: while EFT maintains robust 88% validation accuracy against 93% training performance (a modest 5% gap), standard transformers collapse to 59% validation accuracy despite 95% training performance—revealing a catastrophic 36% memorization gap. Critical Insight: This 7.2× difference in generalization capability isn't a minor improvement—it exposes a fundamental limitation in how standard attention mechanisms learn from data. 3. The Information Concentration Paradox Conventional wisdom suggests distributed processing across many neurons represents healthy neural function. Our gradient-based importance analysis reveals the opposite truth: Standard transformers diffuse importance across numerous components, creating an "if everything matters, nothing matters" paradox where no clear signal emerges. In contrast, EFT concentrates over 5% of total importance into targeted pathways—demonstrating expert-like decisiveness rather than committee-based hedging. Paradigm Shift: Concentration, not distribution, enables clearer signal extraction and more definitive decision-making. 4. The 85% Dead Neuron Discovery: Attention's Fatal Flaw Our most shocking finding—and the one that fundamentally challenges transformer design principles—is the discovery that in standard transformers, 85% of neurons in a critical self-attention layer contribute absolutely nothing to model function. This is not a minor inefficiency. It reveals that the very mechanism powering modern AI—self-attention—operates with catastrophic waste, with only 15% of its computational resources performing meaningful work. EFT's spectral approach dramatically reduces this inefficiency, with even the worst layer maintaining 81% active neurons. This represents a fundamental rethinking of efficient information processing in neural networks. Revolutionary Implication: Self-attention, the cornerstone of modern AI advancement, is fundamentally flawed in its resource utilization, explaining why models require enormous parameter counts to achieve state-of-the-art performance. 5. Architectural Revolution, Not Evolution 5.1 The False Promise of Distributed Processing Standard transformers promote the illusion of distributed intelligence while actually wasting vast computational resources on inactive pathways. EFT reveals that strategic concentration of computational power generates superior results with greater efficiency. 5.2 Beyond Hybrid Approaches: Fundamental Redesign Rather than merely patching conventional architectures, our findings demand fundamental redesign: Replace inefficient attention mechanisms with spectral processors that maximize neuron utilization Design architectures around focused information pathways rather than diffuse attention Rethink scaling laws based on neuron utilization efficiency rather than raw parameter counts 6. Implications for the Future of AI The 85% dead neuron discovery doesn't merely suggest an incremental improvement—it demands a paradigm shift in how we design and scale AI systems. The environmental and computational costs of training increasingly massive transformer models may be largely unnecessary, driven by fundamental inefficiencies in attention mechanism design. EFT demonstrates that spectral approaches can achieve superior results with dramatically improved neuronal efficiency. This insight points toward a future where AI advances through smarter architecture rather than brute-force scaling—potentially reducing environmental impact while improving model performance. By exposing the hidden crisis in attention mecha
Introduction
What began as a satirical thought experiment in "Attention? You Don't Need It" has evolved into a groundbreaking discovery that challenges the foundation of modern AI. Our ElasticFourierTransformer (EFT) doesn't merely offer an alternative to conventional architectures—it exposes a catastrophic inefficiency hidden at the heart of transformer design. Through rigorous neural autopsy, we've uncovered that up to 85% of neurons in critical self-attention layers contribute nothing to model performance, revealing why our spectral approach achieves superior results with more efficient computation.
1. Neural Autopsy: Revealing What Accuracy Metrics Hide
Traditional evaluation metrics have blinded us to the internal wastage of modern architectures. Our comprehensive neural autopsy framework pierces this veil by examining three critical dimensions:
- Generalization Capacity: Quantifying the true learning-memorization balance
- Neuronal Importance: Mapping the flow of decision-making power
- Dead Neuron Detection: Identifying computational resources wasted on inactive pathways
These diagnostics expose the hidden reality of transformer inefficiency that performance benchmarks systematically obscure.
2. The Generalization Crisis in Standard Transformers
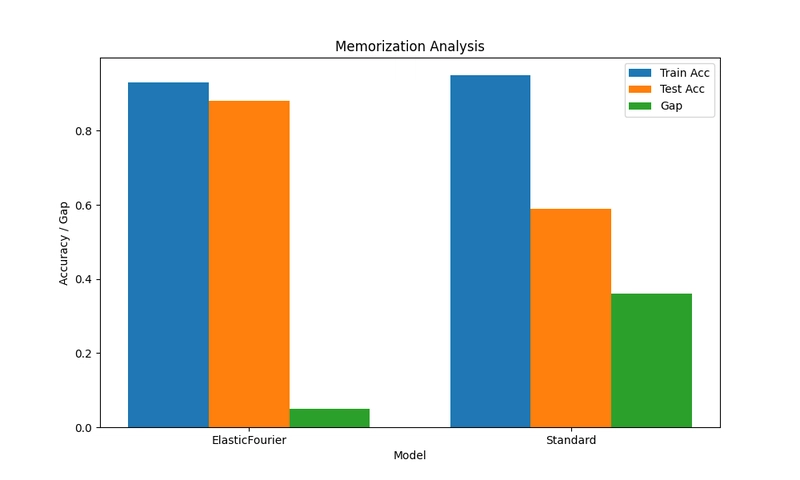
Our experiments reveal a shocking disparity: while EFT maintains robust 88% validation accuracy against 93% training performance (a modest 5% gap), standard transformers collapse to 59% validation accuracy despite 95% training performance—revealing a catastrophic 36% memorization gap.
Critical Insight: This 7.2× difference in generalization capability isn't a minor improvement—it exposes a fundamental limitation in how standard attention mechanisms learn from data.
3. The Information Concentration Paradox
Conventional wisdom suggests distributed processing across many neurons represents healthy neural function. Our gradient-based importance analysis reveals the opposite truth:
Standard transformers diffuse importance across numerous components, creating an "if everything matters, nothing matters" paradox where no clear signal emerges. In contrast, EFT concentrates over 5% of total importance into targeted pathways—demonstrating expert-like decisiveness rather than committee-based hedging.

Paradigm Shift: Concentration, not distribution, enables clearer signal extraction and more definitive decision-making.
4. The 85% Dead Neuron Discovery: Attention's Fatal Flaw
Our most shocking finding—and the one that fundamentally challenges transformer design principles—is the discovery that in standard transformers, 85% of neurons in a critical self-attention layer contribute absolutely nothing to model function.
This is not a minor inefficiency. It reveals that the very mechanism powering modern AI—self-attention—operates with catastrophic waste, with only 15% of its computational resources performing meaningful work.
EFT's spectral approach dramatically reduces this inefficiency, with even the worst layer maintaining 81% active neurons. This represents a fundamental rethinking of efficient information processing in neural networks.

Revolutionary Implication: Self-attention, the cornerstone of modern AI advancement, is fundamentally flawed in its resource utilization, explaining why models require enormous parameter counts to achieve state-of-the-art performance.
5. Architectural Revolution, Not Evolution
5.1 The False Promise of Distributed Processing
Standard transformers promote the illusion of distributed intelligence while actually wasting vast computational resources on inactive pathways. EFT reveals that strategic concentration of computational power generates superior results with greater efficiency.
5.2 Beyond Hybrid Approaches: Fundamental Redesign
Rather than merely patching conventional architectures, our findings demand fundamental redesign:
- Replace inefficient attention mechanisms with spectral processors that maximize neuron utilization
- Design architectures around focused information pathways rather than diffuse attention
- Rethink scaling laws based on neuron utilization efficiency rather than raw parameter counts
6. Implications for the Future of AI
The 85% dead neuron discovery doesn't merely suggest an incremental improvement—it demands a paradigm shift in how we design and scale AI systems. The environmental and computational costs of training increasingly massive transformer models may be largely unnecessary, driven by fundamental inefficiencies in attention mechanism design.
EFT demonstrates that spectral approaches can achieve superior results with dramatically improved neuronal efficiency. This insight points toward a future where AI advances through smarter architecture rather than brute-force scaling—potentially reducing environmental impact while improving model performance.
By exposing the hidden crisis in attention mechanisms, we open the door to a new generation of efficient architectures that could fundamentally transform the trajectory of AI development.



