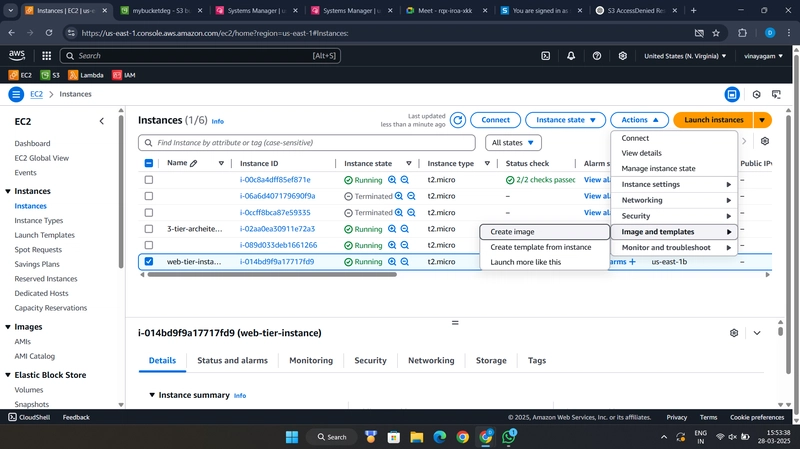


















































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)





























































































































![From Accountant to Data Engineer with Alyson La [Podcast #168]](https://cdn.hashnode.com/res/hashnode/image/upload/v1744420903260/fae4b593-d653-41eb-b70b-031591aa2f35.png?#)







































































































.png?#)






















![Apple TV+ Summer Preview 2025 [Video]](https://www.iclarified.com/images/news/96999/96999/96999-640.jpg)





















































































































![Apple Watch SE 2 On Sale for Just $169.97 [Deal]](https://www.iclarified.com/images/news/96996/96996/96996-640.jpg)

![Apple Posts Full First Episode of 'Your Friends & Neighbors' on YouTube [Video]](https://www.iclarified.com/images/news/96990/96990/96990-640.jpg)
























































































































AI กับการจำแนกข้อมูล (Classification) ด้วย Decision Tree
ในยุคที่ข้อมูลมีอยู่รอบตัวเรา การใช้ปัญญาประดิษฐ์ (AI) เพื่อวิเคราะห์และจัดการข้อมูลกลายเป็นสิ่งสำคัญเป็นอย่างมาก หนึ่งในเทคนิคยอดนิยม คือ Machine Learning แบบ Classification ซึ่งเป็นวิธีให้คอมพิวเตอร์เรียนรู้การจำแนกประเภทของข้อมูล ซึ่งบทความนี้จะพาไปเรียนรู้การเขียนโค้ด AI ใน Python อย่างง่ายโดยใช้ Decision Tree และเพื่อจำแนกข้อมูล พร้อมตัวอย่างการประยุกต์ใช้กับข้อมูลจริง Classification คืออะไร? Classification หรือการจำแนกประเภท คือปัญหาในรูปแบบ Supervised Learning ที่ผลลัพธ์ (Output) มีลักษณะเป็นค่าจำกัด เช่น "ใช่/ไม่ใช่", "ผ่าน/ไม่ผ่าน", หรือ "กลุ่ม A/B/C" ตัวอย่างการประยุกต์ใช้ การคาดการณ์ว่าลูกค้าจะยกเลิกบริการหรือไม่ (Churn prediction) การจำแนกอีเมลว่าเป็นสแปมหรือไม่ การคัดกรองผู้ป่วยว่ามีความเสี่ยงติดโรค หรือไม่ ในช่วงที่มีโรคระบาด AI Code นี้ทำอะไร และใช้วิธีไหน? ในบทความนี้เราจะใช้ Machine Learning แบบ Classification โดยเลือกใช้โมเดล Decision Tree ข้อมูลที่ใช้คือ Titanic Dataset ซึ่งบันทึกข้อมูลของผู้โดยสารจากเรือไททานิก ประกอบไปด้วย อายุ เพศ ชั้นโดยสาร ค่าโดยสาร และว่ารอดชีวิตหรือไม่ เป้าหมาย คือ การสร้างโมเดลเพื่อพยากรณ์ว่าผู้โดยสารจะรอดหรือไม่จากข้อมูลเบื้องต้น ตัวอย่างที่ 1 พยากรณ์การรอดชีวิตของผู้โดยสาร ขั้นตอนที่ 1 เราจะเรียกใช้ไลบรารี ต่าง ๆ ดังนี้ pandas ใช้จัดการข้อมูลแบบตาราง seaborn ใช้โหลด dataset และช่วยเรื่อง visualization sklearn.tree.DecisionTreeClassifier เป็นโมเดลที่ใช้สำหรับ Classification classification_report, confusion_matrix ใช้วัดประสิทธิภาพของโมเดล train_test_split ใช้แบ่งข้อมูลออกเป็นชุด Train และ Test ขั้นตอนที่ 2 โหลดข้อมูล Titanic จาก seaborn แต่ละแถว = ผู้โดยสาร 1 คน มีข้อมูล เพศ อายุ ชั้นโดยสาร ราคา และ รอดชีวิตหรือไหม ขั้นตอนที่ 3 เลือกเฉพาะคอลัมน์ที่ต้องใช้ และจัดการข้อมูล(NaN) โดยเลือกเฉพาะ 5 คอลัมน์ที่สำคัญ จากนั้นใช้ dropna() = ลบแถวที่มีค่าว่าง เช่น บางคนไม่มีข้อมูลอายุระบุเอาไว้อยู่ ขั้นตอนที่ 4 ทำการแยกข้อมูล Features กับ Labels โดย X แทนข้อมูลที่ใช้ในการพยากรณ์ (sex, age, fare, pclass) y แทนสิ่งที่เราต้องการทำนาย = survived (0 = ตาย, 1 = รอด) ขั้นตอนที่ 5 แปลงข้อมูล Category ให้เป็นตัวเลข ตัวอย่างเช่น sex เป็นข้อมูลประเภทข้อความ เราต้องแปลงเป็นตัวเลขก่อน หลังแปลงจะได้คอลัมน์ใหม่ชื่อ sex_male ถ้าเป็นเพศชาย = 1 ถ้าเป็นเพศหญิง = 0 ขั้นตอนที่ 6 ทำการแบ่งข้อมูล Train/Test โดย แบ่งข้อมูล 80% สำหรับฝึก (Train), 20% สำหรับทดสอบ (Test) จากนั้นใช้ random_state เพื่อให้ผลลัพธ์เดิมซ้ำได้ ขั้นตอนที่ 7 สร้างและฝึกโมเดล Decision Tree โดยใช้ Entropy เป็นตัวเลือกแยกข้อมูล จำกัดความลึกของต้นไม้ไม่เกิน 10 ชั้น ในส่วนของ .fit(X_train, y_train) จะเป็นการฝึกโมเดลจากข้อมูล Train ขั้นตอนที่ 8 ทำนายผล และประเมินโมเดล โดยใช้โมเดลที่ฝึกแล้ว ทำนายผลจากข้อมูล Test จากนั้น แสดงผล Confusion Matrix และ Classification Report โดย Confusion Matrix คือ ตารางแสดงจำนวนผลลัพธ์ที่ถูกและผิด Classification Report คือ การแสดงค่า Precision, Recall, F1-score และ Accuracy และนี่คือ ตัวอย่าง Output ที่ได้ จากตารางจากผลลัพธ์ที่ได้ [[72 15] [23 33]] โดยมีความแม่นยำประมาณ 73% ความแม่นยำโดยรวมพอใช้ได้ แต่ไม่ได้สูงมาก ซึ่งแสดงให้เห็นว่าโมเดลยังพลาดในการแยก "รอด" กับ "ไม่รอด" บ้าง ตัวอย่างที่ 2 การทำนายการผ่านสอบ เราจะใช้ Machine Learning แบบ Classification โดยเลือกใช้โมเดล Decision Tree ข้อมูลที่ใช้จะเป็นข้อมูลที่สร้างขึ้น ซึ่งบันทึกข้อมูลของนักเรียนแต่ละคน เช่น อ่านหนังสือกี่ชั่วโมง, เข้าเรียนครบไหม เป้าหมาย คือ การสร้างโมเดลเพื่อพยากรณ์ ว่าถ้าเราเพิ่มนักเรียนเรียนอีก 1 คน อ่านหนักสือ 3 ชั่วโมง และ ไม่ขาดเรียน โมเดลจะทำทายผลลัพธ์อย่างไร สมมุติว่าเรามีข้อมูลนักเรียนว่า "อ่านหนังสือกี่ชั่วโมง", "เข้าเรียนครบไหม", และผลลัพธ์คือ "สอบผ่านหรือไม่" เราจะโดยใช้ไลบรารี่ pandas ใช้จัดการกับข้อมูลในรูปแบบตาราง (DataFrame) DecisionTreeClassifier คืออัลกอริธึม Machine Learning ที่ใช้จำแนกข้อมูลแบบ Decision Tree ทำการสร้างข้อมูลจำลองของนักเรียน 5 คน ประกอบไปด้วย study_hours แทนจำนวนชั่วโมงที่อ่านหนังสือ attended_class โดยกำหนดให้ 0 = ไม่เข้าเรียนครบ, 1 = เข้าเรียนครบ passed โดยกำหนดให้ 0 = สอบไม่ผ่าน, 1 = สอบผ่าน สร้างตารางข้อมูล (DataFrame) จาก dictionary เพื่อให้ใช้งานง่ายขึ้น X คือ Feature (ตัวแปรต้น) ที่ใช้ในการพยากรณ์ผลลัพธ์ มี 2 ตัวแปร เวลาอ่านหนังสือ + การเข้าเรียน y คือ Target (ผลลัพธ์) ที่เราต้องการให้โมเดลเรียนรู้ คือ "สอบผ่านหรือไม่" สร้างโมเดล Decision Tree และในส่วนของ .fit(X, y) ให้โมเดลเรียนรู้จากข้อมูล X เพื่อหาความสัมพันธ์กับผลลัพธ์ y สร้างข้อมูลใหม่ของนักเรียน 1 คน ที่อ่านหนังสือ 3 ชั่วโมง เข้าเรียนครบ (1) model.predict(...) จะทำนายว่าเค้าจะสอบ "ผ่าน (1)" หรือ "ไม่ผ่าน (0)" อย่างไรก็ตาม ถ้าได้ลองเอาโค้ดนี้ไปใช้ตามจะพบว่าผลลัพที่ได้นั้น “ไม่เหมือนเดิม”? ซึ่งเราจะมาอธิบายเพิ่มเติมกันว่าทำไม จากโค้ดข้างต้นสิ่งที่เราทำก็ คือ การทำนายข้อมูลใหม่ ซึ่งหมายความว่านักเรียนที่เราสร้างมานั้น อ่านหนังสือ 3 ชั่วโมง เข้าเรียนครบ (1) ซึ่งไม่มีอยู่ในชุดข้อมูลฝึก จากข้อมูลเดิม มีคนที่เข้าเรียนครบ (attended_class = 1) แต่ไม่มีใครที่เข้าเรียนครบและอ่านแค่ 3 ชั่วโมง ดังนั้น Decision Tree จะเดาจากจุดที่ใกล้เคียงที่สุด เช่น มันอาจดูว่า คนที่ study_hours = 2, attended_class = 0 → ไม่ผ่าน หรือ study_hours = 4, attended_class = 1 → ผ่านนั่นเอง สรุปเนื้อหา โดยบทความนี้ได้แสดงตัวอย่าง Class

ในยุคที่ข้อมูลมีอยู่รอบตัวเรา การใช้ปัญญาประดิษฐ์ (AI) เพื่อวิเคราะห์และจัดการข้อมูลกลายเป็นสิ่งสำคัญเป็นอย่างมาก หนึ่งในเทคนิคยอดนิยม คือ Machine Learning แบบ Classification ซึ่งเป็นวิธีให้คอมพิวเตอร์เรียนรู้การจำแนกประเภทของข้อมูล ซึ่งบทความนี้จะพาไปเรียนรู้การเขียนโค้ด AI ใน Python อย่างง่ายโดยใช้ Decision Tree และเพื่อจำแนกข้อมูล พร้อมตัวอย่างการประยุกต์ใช้กับข้อมูลจริง
Classification คืออะไร?
Classification หรือการจำแนกประเภท คือปัญหาในรูปแบบ Supervised Learning ที่ผลลัพธ์ (Output) มีลักษณะเป็นค่าจำกัด เช่น "ใช่/ไม่ใช่", "ผ่าน/ไม่ผ่าน", หรือ "กลุ่ม A/B/C"
ตัวอย่างการประยุกต์ใช้
- การคาดการณ์ว่าลูกค้าจะยกเลิกบริการหรือไม่ (Churn prediction)
- การจำแนกอีเมลว่าเป็นสแปมหรือไม่
- การคัดกรองผู้ป่วยว่ามีความเสี่ยงติดโรค หรือไม่ ในช่วงที่มีโรคระบาด
AI Code นี้ทำอะไร และใช้วิธีไหน?
ในบทความนี้เราจะใช้ Machine Learning แบบ Classification โดยเลือกใช้โมเดล Decision Tree ข้อมูลที่ใช้คือ Titanic Dataset ซึ่งบันทึกข้อมูลของผู้โดยสารจากเรือไททานิก ประกอบไปด้วย อายุ เพศ ชั้นโดยสาร ค่าโดยสาร และว่ารอดชีวิตหรือไม่ เป้าหมาย คือ การสร้างโมเดลเพื่อพยากรณ์ว่าผู้โดยสารจะรอดหรือไม่จากข้อมูลเบื้องต้น
ตัวอย่างที่ 1 พยากรณ์การรอดชีวิตของผู้โดยสาร
ขั้นตอนที่ 1 เราจะเรียกใช้ไลบรารี ต่าง ๆ ดังนี้
- pandas ใช้จัดการข้อมูลแบบตาราง
- seaborn ใช้โหลด dataset และช่วยเรื่อง visualization
- sklearn.tree.DecisionTreeClassifier เป็นโมเดลที่ใช้สำหรับ Classification
- classification_report, confusion_matrix ใช้วัดประสิทธิภาพของโมเดล
- train_test_split ใช้แบ่งข้อมูลออกเป็นชุด Train และ Test
ขั้นตอนที่ 2 โหลดข้อมูล Titanic จาก seaborn แต่ละแถว = ผู้โดยสาร 1 คน มีข้อมูล เพศ อายุ ชั้นโดยสาร ราคา และ รอดชีวิตหรือไหม

ขั้นตอนที่ 3 เลือกเฉพาะคอลัมน์ที่ต้องใช้ และจัดการข้อมูล(NaN) โดยเลือกเฉพาะ 5 คอลัมน์ที่สำคัญ จากนั้นใช้ dropna() = ลบแถวที่มีค่าว่าง เช่น บางคนไม่มีข้อมูลอายุระบุเอาไว้อยู่

ขั้นตอนที่ 4 ทำการแยกข้อมูล Features กับ Labels โดย
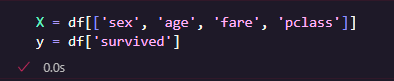
- X แทนข้อมูลที่ใช้ในการพยากรณ์ (sex, age, fare, pclass)
- y แทนสิ่งที่เราต้องการทำนาย = survived (0 = ตาย, 1 = รอด)
ขั้นตอนที่ 5 แปลงข้อมูล Category ให้เป็นตัวเลข ตัวอย่างเช่น sex เป็นข้อมูลประเภทข้อความ เราต้องแปลงเป็นตัวเลขก่อน
หลังแปลงจะได้คอลัมน์ใหม่ชื่อ sex_male
- ถ้าเป็นเพศชาย = 1
- ถ้าเป็นเพศหญิง = 0

ขั้นตอนที่ 6 ทำการแบ่งข้อมูล Train/Test โดย แบ่งข้อมูล 80% สำหรับฝึก (Train), 20% สำหรับทดสอบ (Test) จากนั้นใช้ random_state เพื่อให้ผลลัพธ์เดิมซ้ำได้

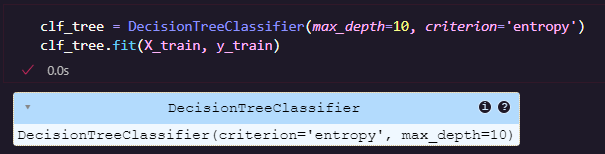
ขั้นตอนที่ 7 สร้างและฝึกโมเดล Decision Tree โดยใช้ Entropy เป็นตัวเลือกแยกข้อมูล จำกัดความลึกของต้นไม้ไม่เกิน 10 ชั้น ในส่วนของ .fit(X_train, y_train) จะเป็นการฝึกโมเดลจากข้อมูล Train
ขั้นตอนที่ 8 ทำนายผล และประเมินโมเดล โดยใช้โมเดลที่ฝึกแล้ว ทำนายผลจากข้อมูล Test จากนั้น แสดงผล Confusion Matrix และ Classification Report โดย
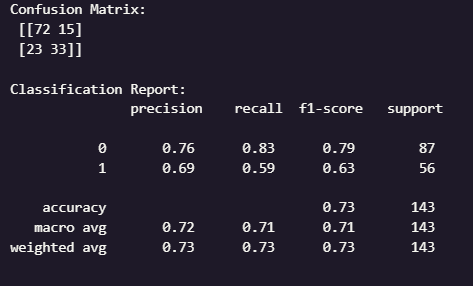
Confusion Matrix คือ ตารางแสดงจำนวนผลลัพธ์ที่ถูกและผิด
Classification Report คือ การแสดงค่า Precision, Recall, F1-score และ Accuracy
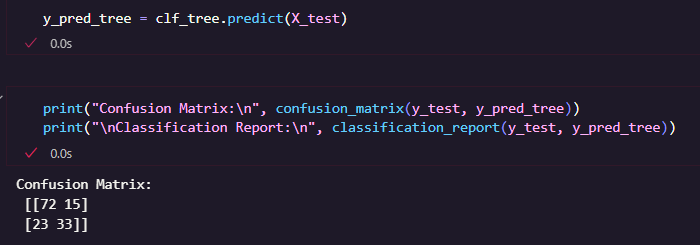
และนี่คือ ตัวอย่าง Output ที่ได้
จากตารางจากผลลัพธ์ที่ได้
[[72 15]
[23 33]]

โดยมีความแม่นยำประมาณ 73% ความแม่นยำโดยรวมพอใช้ได้ แต่ไม่ได้สูงมาก ซึ่งแสดงให้เห็นว่าโมเดลยังพลาดในการแยก "รอด" กับ "ไม่รอด" บ้าง
ตัวอย่างที่ 2 การทำนายการผ่านสอบ
เราจะใช้ Machine Learning แบบ Classification โดยเลือกใช้โมเดล Decision Tree ข้อมูลที่ใช้จะเป็นข้อมูลที่สร้างขึ้น ซึ่งบันทึกข้อมูลของนักเรียนแต่ละคน เช่น อ่านหนังสือกี่ชั่วโมง, เข้าเรียนครบไหม เป้าหมาย คือ การสร้างโมเดลเพื่อพยากรณ์ ว่าถ้าเราเพิ่มนักเรียนเรียนอีก 1 คน อ่านหนักสือ 3 ชั่วโมง และ ไม่ขาดเรียน โมเดลจะทำทายผลลัพธ์อย่างไร
สมมุติว่าเรามีข้อมูลนักเรียนว่า "อ่านหนังสือกี่ชั่วโมง", "เข้าเรียนครบไหม", และผลลัพธ์คือ "สอบผ่านหรือไม่" เราจะโดยใช้ไลบรารี่
- pandas ใช้จัดการกับข้อมูลในรูปแบบตาราง (DataFrame)
- DecisionTreeClassifier คืออัลกอริธึม Machine Learning ที่ใช้จำแนกข้อมูลแบบ Decision Tree
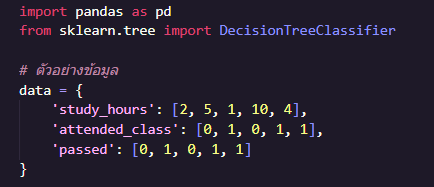
ทำการสร้างข้อมูลจำลองของนักเรียน 5 คน ประกอบไปด้วย
- study_hours แทนจำนวนชั่วโมงที่อ่านหนังสือ
- attended_class โดยกำหนดให้ 0 = ไม่เข้าเรียนครบ, 1 = เข้าเรียนครบ
- passed โดยกำหนดให้ 0 = สอบไม่ผ่าน, 1 = สอบผ่าน
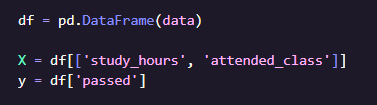
สร้างตารางข้อมูล (DataFrame) จาก dictionary เพื่อให้ใช้งานง่ายขึ้น
- X คือ Feature (ตัวแปรต้น) ที่ใช้ในการพยากรณ์ผลลัพธ์ มี 2 ตัวแปร เวลาอ่านหนังสือ + การเข้าเรียน
- y คือ Target (ผลลัพธ์) ที่เราต้องการให้โมเดลเรียนรู้ คือ "สอบผ่านหรือไม่"
สร้างโมเดล Decision Tree และในส่วนของ .fit(X, y) ให้โมเดลเรียนรู้จากข้อมูล X เพื่อหาความสัมพันธ์กับผลลัพธ์ y
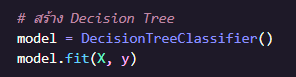
สร้างข้อมูลใหม่ของนักเรียน 1 คน ที่อ่านหนังสือ 3 ชั่วโมง เข้าเรียนครบ (1)
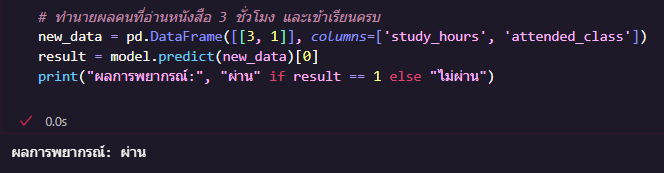
model.predict(...) จะทำนายว่าเค้าจะสอบ "ผ่าน (1)" หรือ "ไม่ผ่าน (0)"
อย่างไรก็ตาม ถ้าได้ลองเอาโค้ดนี้ไปใช้ตามจะพบว่าผลลัพที่ได้นั้น “ไม่เหมือนเดิม”? ซึ่งเราจะมาอธิบายเพิ่มเติมกันว่าทำไม
จากโค้ดข้างต้นสิ่งที่เราทำก็ คือ การทำนายข้อมูลใหม่
![]()
ซึ่งหมายความว่านักเรียนที่เราสร้างมานั้น
- อ่านหนังสือ 3 ชั่วโมง
- เข้าเรียนครบ (1)
ซึ่งไม่มีอยู่ในชุดข้อมูลฝึก

จากข้อมูลเดิม มีคนที่เข้าเรียนครบ (attended_class = 1) แต่ไม่มีใครที่เข้าเรียนครบและอ่านแค่ 3 ชั่วโมง
ดังนั้น Decision Tree จะเดาจากจุดที่ใกล้เคียงที่สุด เช่น มันอาจดูว่า คนที่ study_hours = 2, attended_class = 0 → ไม่ผ่าน หรือ study_hours = 4, attended_class = 1 → ผ่านนั่นเอง
สรุปเนื้อหา
โดยบทความนี้ได้แสดงตัวอย่าง Classification พื้นฐานใน AI ที่ใช้ในการจำแนกข้อมูลออกเป็นกลุ่มๆ เราได้ทดลองใช้ Decision Tree เป็นหลักเพื่อสร้างโมเดลจำแนกผู้รอดชีวิตจาก Titanic dataset และ ยังสร้างโมเดลทำนายผลการสอบของนักเรียนจากชั่วโมงการอ่านหนังสือและการเข้าเรียน เราสามารถทดลองปรับพารามิเตอร์ของโมเดล หรือลองใช้ข้อมูลจากโลกจริงอื่น ๆ เช่น ข้อมูลลูกค้า หรือข้อมูลสุขภาพ เพื่อทำนายพฤติกรรมและแนวโน้มต่าง ๆ ได้อีกด้วย สามารถลองนำโค้ดไปใช้ได้เลยครับ
แหล่งอ้างอิง
ธเนศวร, ผศ.ดร. เก็จแก้ว. (ม.ป.ป.). Classification model. Google Colaboratory. สืบค้นจาก https://colab.research.google.com/drive/1BcbCbMcYxW8u6mmcAQTvsEb8Cq1RGVDE?usp=sharing