








































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)






























































































































![From Accountant to Data Engineer with Alyson La [Podcast #168]](https://cdn.hashnode.com/res/hashnode/image/upload/v1744420903260/fae4b593-d653-41eb-b70b-031591aa2f35.png?#)





































































































.png?#)









































































































































![Apple Watch SE 2 On Sale for Just $169.97 [Deal]](https://www.iclarified.com/images/news/96996/96996/96996-640.jpg)

![Apple Posts Full First Episode of 'Your Friends & Neighbors' on YouTube [Video]](https://www.iclarified.com/images/news/96990/96990/96990-640.jpg)




























































































































When Your AI Agent Lies to You: Tackling Real-World LLM Hallucinations
Overview We @ Connectly AI have been deep in the weeds of building sales and customer support conversational AI since the dawn of the ChatGPT era. After developing AI agents in production, including Sofia Lite & Sofia V3, we’ve identified key pain points we found around hallucination and reliable responses. This is what led us to develop Sofia QA, the latest AI product from Connectly AI, which is built on the wealth of real-world data and learnings from production to ensure high reliability and accuracy within the bot. Through extensive work done to diagnose and mitigate hallucination within the design and architecture of the product, Sofia QA has had strong adoption and stickiness with 77% answer rate across 25 thousand user sessions and customer feedback highlights a 5/5 setup experience, effective inquiry resolution, and improved answer quality. In this blog, we attempt to precisely define the failures we observed and our strategy for evaluating and catching these during the design and implementation of the Sofia QA. Background In this section, we highlight the major shortcomings of the previous iterations of the Sofia bot and categorize the nature of the failure modes. Hallucinations tend to be used as an overloaded catch-all term that describes a wide-range of behaviors. We attempt to precisely define the failures we observed with Sofia Lite and a strategy for evaluating and catching these during the design and implementation of the Sofia QA conversational AI tool. We define a language model hallucination as when a model performs behaviors or makes statements that cannot be verified or supported. Sofia V3, an Autonomous Agentic Architecture Read to learn more about Sofia V3 The unconstrained nature of Sofia V3's Agentic architecture made it difficult to achieve reliable and predictable behavior across a wide range of tasks, from RAG-form question answering to image-based product recommendations. This lack of constraint also resulted in a lack of explainability regarding generated instructions and LLM execution strategy, which in turn made it challenging to train non-experts on the bot's capabilities and how to fine-tune its behavior. Analysis of Agentic Failure Modes: Failure Mode Explanation Conversation Example Why It Is a Challenging Problem Parsing Intent Was Challenging Short and ambiguous messages from the user lend themselves to a variety of interpretations. Additionally, Sofia would infer implicit user intentions that were not actually the user message. User: "Delivery?" Sofia: Incorrectly assumes the user wants to inquire about shipping options instead of checking delivery eligibility to their address. User: "This is too expensive." Sofia: Automatically suggests the user asking for a discount rather than providing alternative cheaper products. Disambiguating intent requires a rich understanding of context, tone, and shared knowledge that is not trivial for an off-the-shelf Large Language model, especially within the realm of a conversational shopping interaction or customer support. On AmiEnt, GPT-4 scored 32% on being able to recognize ambiguity and disentangle possible meanings. CLAMBER shows that LLMs do not even realize when a user’s request is unclear, or fail to ask clarifying questions. Almost all customers had non-English conversations, which tend to see a decline in reasoning performance (mCoT). Self-Refinement Errors There were 2 types of errors we noted: a) false negatives where it would incorrectly flag an instruction that was written correctly & b) false positives where it would ask to rewrite an instruction that was correct, causing it to hallucinate. We did not see in production notable improvements from self-reflection (Reflexion). User: "I ordered shoes two weeks ago and still haven’t received them. What’s going on?" Sofia: Correctly determines the intent is to provide a link to a resource to track the order. Critic: The user wants to know if their shoes order has been submitted. Sofia: Changes its instruction to tell the user their shoes are arriving. Following what was noted in MAGICORE: "Selective refinement avoids over-correcting and improves overall performance. In Section 1, we noted that excessive refinement could potentially hurt performance by flipping correct answers to incorrect ones", we observed that reflection (Reflexion) was not always helpful and actually triggered the LLM to self-correct in an unhelpful manner. Agentic Approach Was Unconstrained In our design, an agent had to a) infer the user intention and b) was responsible for executing its plan through tool-use and c) had to be robust to tools failing at their task. User: "This is too expensive." Sofia: Even if the bot parses the intent correctly as looking for alternate products, then choosing the right tool to search for products in the catalog and then successfully finding a suitable were additional downstream sources of error. This presented 3 possi

Overview
We @ Connectly AI have been deep in the weeds of building sales and customer support conversational AI since the dawn of the ChatGPT era. After developing AI agents in production, including Sofia Lite & Sofia V3, we’ve identified key pain points we found around hallucination and reliable responses. This is what led us to develop Sofia QA, the latest AI product from Connectly AI, which is built on the wealth of real-world data and learnings from production to ensure high reliability and accuracy within the bot. Through extensive work done to diagnose and mitigate hallucination within the design and architecture of the product, Sofia QA has had strong adoption and stickiness with 77% answer rate across 25 thousand user sessions and customer feedback highlights a 5/5 setup experience, effective inquiry resolution, and improved answer quality.
In this blog, we attempt to precisely define the failures we observed and our strategy for evaluating and catching these during the design and implementation of the Sofia QA.
Background
In this section, we highlight the major shortcomings of the previous iterations of the Sofia bot and categorize the nature of the failure modes. Hallucinations tend to be used as an overloaded catch-all term that describes a wide-range of behaviors. We attempt to precisely define the failures we observed with Sofia Lite and a strategy for evaluating and catching these during the design and implementation of the Sofia QA conversational AI tool. We define a language model hallucination as when a model performs behaviors or makes statements that cannot be verified or supported.
Sofia V3, an Autonomous Agentic Architecture
Read to learn more about Sofia V3
The unconstrained nature of Sofia V3's Agentic architecture made it difficult to achieve reliable and predictable behavior across a wide range of tasks, from RAG-form question answering to image-based product recommendations. This lack of constraint also resulted in a lack of explainability regarding generated instructions and LLM execution strategy, which in turn made it challenging to train non-experts on the bot's capabilities and how to fine-tune its behavior.
Analysis of Agentic Failure Modes:
| Failure Mode | Explanation | Conversation Example | Why It Is a Challenging Problem |
|---|---|---|---|
| Parsing Intent Was Challenging | Short and ambiguous messages from the user lend themselves to a variety of interpretations. Additionally, Sofia would infer implicit user intentions that were not actually the user message. | User: "Delivery?" Sofia: Incorrectly assumes the user wants to inquire about shipping options instead of checking delivery eligibility to their address. User: "This is too expensive." Sofia: Automatically suggests the user asking for a discount rather than providing alternative cheaper products. | Disambiguating intent requires a rich understanding of context, tone, and shared knowledge that is not trivial for an off-the-shelf Large Language model, especially within the realm of a conversational shopping interaction or customer support. On AmiEnt, GPT-4 scored 32% on being able to recognize ambiguity and disentangle possible meanings. CLAMBER shows that LLMs do not even realize when a user’s request is unclear, or fail to ask clarifying questions. Almost all customers had non-English conversations, which tend to see a decline in reasoning performance (mCoT). |
| Self-Refinement Errors | There were 2 types of errors we noted: a) false negatives where it would incorrectly flag an instruction that was written correctly & b) false positives where it would ask to rewrite an instruction that was correct, causing it to hallucinate. We did not see in production notable improvements from self-reflection (Reflexion). | User: "I ordered shoes two weeks ago and still haven’t received them. What’s going on?" Sofia: Correctly determines the intent is to provide a link to a resource to track the order. Critic: The user wants to know if their shoes order has been submitted. Sofia: Changes its instruction to tell the user their shoes are arriving. | Following what was noted in MAGICORE: "Selective refinement avoids over-correcting and improves overall performance. In Section 1, we noted that excessive refinement could potentially hurt performance by flipping correct answers to incorrect ones", we observed that reflection (Reflexion) was not always helpful and actually triggered the LLM to self-correct in an unhelpful manner. |
| Agentic Approach Was Unconstrained | In our design, an agent had to a) infer the user intention and b) was responsible for executing its plan through tool-use and c) had to be robust to tools failing at their task. | User: "This is too expensive." Sofia: Even if the bot parses the intent correctly as looking for alternate products, then choosing the right tool to search for products in the catalog and then successfully finding a suitable were additional downstream sources of error. | This presented 3 possible sources of error which contributed to the well-known problem with LLM applications of cascading errors (link, link 2). This means that if we obtained 95% performance on understanding the user intention from the dialog, 95% on tool success, and 95% on plan execution, that would result in a cumulative 0.95^3 = 0.857, 85.7% performance end to end. |
| LLM Verification in Conversations is Difficult | The conversational domain is highly fluid and involves multi-turn interactions. It is difficult to have an LLM verify whether the task was accomplished successfully. | User: "Recommend products for me" Sofia: Provides product recommendations that are unsuitable for the user. User: "What are the latest promotions" Sofia: Showcases promotions that are irrelevant to the user. | As opposed to logical, scientific, or mathematical problem-solving where there is a method to deterministically verify the correctness of response, there are many possible valid responses in a conversational setting, making it hard to define correctness. For example, in question-answering, there are many possible answers for a given question (CDQG). Likewise, it is not obvious to an LLM what products or promotions would be most relevant for the user and requires effective comprehension and theory of mind reasoning on the part of the LLM to self-correct (link). |
| Hallucinations to be able to accomplish their task | The bot made up links, phone numbers, or claimed it could perform deliveries or pickups to answer user requests. | User: "Where can I track my order?" Sofia: "Please log into your account on our website and check the status under 'My Orders'. For further assistance, you can contact our customer service at +254-20-523-0600." (Hallucinated phone number) | Given the flexibility and goal-oriented nature of the agentic design, the model would hallucinate abilities to be able to fulfill a user request. These behaviors would stem from its post-training, the objective of which to maximize human preferences. Wherever there is a gap in its knowledge, it will tend to fill it with erroneous content from content it was exposed to during pretraining (link, link 2). |
| Failure to Pass Context Between Agents | Important context like product details or chunks of documents had to be captured and passed across agents. | User: "How long can I rent a car?” Sofia: Searches the knowledge base for documents and gets 10 relevant documents, one says “1 day rental should go through app instead of rent by hour or day” and the second says “Rentals can be done on a month to month basis”. The LLM would fail to pass all relevant info downstream, only passing the second passage and leading to an incomplete response for the user. | Context summarization techniques often miss on conflicting or ambiguous information while summarizing details. An alternative, which is to pass all documents, tends to add unnecessary noise to the LLM context window, reducing the likelihood of accurately quoting the right response. |
| Struggles with Case-Based Extraction | In an attempt to constrain the behavior of Sofia, we attempted to move away from using a dialogue summary tool (see Observation summarization from HiAgent) to classifying messages into pre-defined intents | Business 1: Adds rule that Medical product inquiries should always go to a human agent. Business 2: Frustrated customers should not be directed to human agents, only customers who are asking for discounts and promotions. | This is still an open research problem as evidenced by Sierra AI’s Tau-bench benchmark that shows models can struggle to take conversational scenarios and direct them to the right tool, where the best models, even Anthropic’s latest Claude 3.7 getting 81.2%/58.4%, have not yet solved that benchmark. It also is difficult to build in a way that tailors to the needs of each business. A pharmacy may want medical products to be treated differently than normal products. Yet, LLMs struggle at rule-following, and we found that more than 3 custom rules became tricky to get the bot to enforce and follow them. We relied on hacky prompting techniques to enforce guardrails. This is also evidenced in RuleBench, which suggests the introduction of 2-3 related rules can reduce rule-following accuracy by 40%. |
| Challenges with Human Handover | Human handover classification was either too sensitive or too lenient in flagging conversations for human review. | User: "I can't register; it says I already have an account." Sofia: Flags for handover incorrectly, even though it doesn't explicitly request human support. | Again this falls under the difficulty in parsing user intent as it is inherently ambiguous and unclear in edge cases as to what the user desires versus what the model perceives the user cares about. Defining precise handover triggers requires significant tuning for the agent to perform reliably. |
Difficulty for Non-Experts to use Agentic App
| Failure Mode | Explanation | Example |
|---|---|---|
| Difficult to Understand and Prompt Engineer for Non-Experts | Customers confused prompting the orchestration vs. response behaviors and thus could not differentiate between programming what the bot would do and how the bot should respond. | One business would write goals into an agent response prompt, an example “Your main goal is to recommend and sell to the user. Do this by (1) learning what they want (2) presenting goods or services that can help the customer and then (3) encouraging the customer to buy, making sure they are well informed about their choices”, all included as a final response instruction rather than as goals for the bot. |
| Inability to Tune the Bot Without Expertise | Customers struggled to know when to add to the knowledge base or when to add custom goals in the prompt for the Agent. | For example, this content was added as a goal for one Sofia bot, “whenever someone asks about tracking an order or the status of an order, inform the customer that they can obtain this information through this link https://www.store.com/my-account/orders”. However, this should exist in the knowledge base as additional information rather than as an explicit rule for the model. |
| Lack of Visibility into Knowledge Base | It was difficult to have visibility into the actual content within the knowledge base of the agent, this was a source of confusion for businesses which did not realize critical information was missing and hence was not available for the bot to use. | If a store is closed for a specific holiday but the documents say the store is open on the weekends, Sofia will say the store is open, making it unclear for businesses and a cause for confusion. Businesses also did not know they uploaded temporary seasonal promotions and these were shown to the user and unexpected promotions or discounts were being offered. |
Sofia QA
Sofia QA was designed to tackle all these major challenges by providing factual, knowledge-based answers, reducing the workload on customer agents, and delivering clear analytics to showcase its impact. It is reliable, easy to set up, self-improving, and maintainable without significant engineering support.
Attribution Strategies
Attribution techniques for Large Language Models (LLMs) aim to improve factual reliability by linking generated text to verifiable sources. These methods ensure that responses are backed by provided content, reducing the underlying risk of hallucination.
These were the 3 strategies we explored for attribution:
- In-line Response Citations – This approach integrates citations directly into responses as they are generated, improving transparency. The Nova RAG Prompt Design structures prompts to enforce inline attributions by guiding LLMs to reference retrieved sources explicitly.
- Chain-of-Thought – CoT has the LLM decompose content and ensures that citations link to high-quality, relevant evidence rather than arbitrary or low-relevance sources.
- Post-attribution (Citation Generation with LLM Attribution or Entailment Model) – Rather than embedding citations during generation, this approach applies an attribution model after the response is drafted. LLMs or entailment models like RoBERTa or other hallucination evaluation models (Patronus, MiniCheck) to analyze statements, match them to retrieve documents, and insert citations post-hoc.
Experimentation
We leverage Metrics-Driven Development to have a measurable baseline dataset to design and optimize our system against. We perform this experimentation on a sample customer dataset of over one hundred and twenty one questions in Spanish. Development of this RAG framework would require identifying the strongest retrieval, citation, and answer generation methods for this specific use-case of multilingual conversational RAG.
A. Retrieval Quality
We explore 3 retrieval approaches:
- One-shot retrieval: This technique retrieves information in a single step, using a hybrid search approach that combines sparse and dense vector search. This is the simplest and fastest retrieval technique.
- Reranking: This technique involves an initial retrieval step, followed by a reranking step that uses an LLM re-ranker to reorder the retrieved results. This technique can improve the quality of the results, but it can also be noisy and add additional time.
- Filtering: This technique uses an LLM to filter the retrieved results, removing any results that are deemed to be irrelevant. This technique can also improve the quality of the results, but at the expense of added response time.
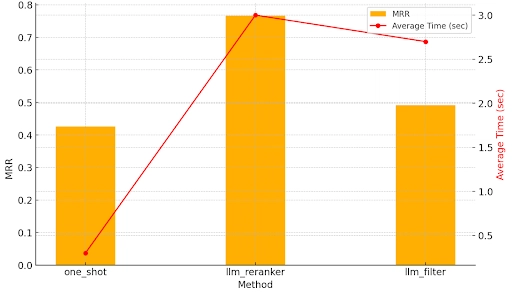
Experiment 1: Retrieval Quality for Different Retrieval Techniques
Conclusion: There is a tradeoff in increased retrieval time with the Reranker and Filtering methods (for the LLM call associated). The strongest final rankings came from using the re-ranker. However, this comes at an extremely high additional cost in response time.
B. Citation Quality
We calculate the citation accuracy by determining the precision of selected citations with respect to the ground truth citations.
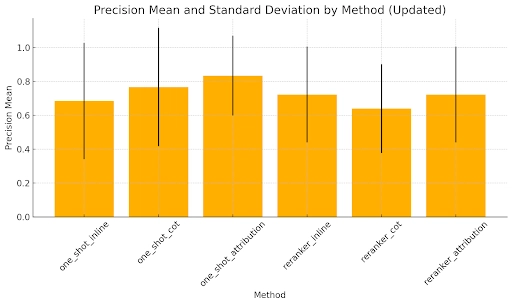
Experiment 2: Citation Precision for Different Citation Techniques
Conclusion: The most precise citation strategy involves an attribution step which is marginally more accurate than CoT or inline citations. Notably, the Reranker with CoT seems to perform worse on our dataset than the comparable one-shot retrieval, which suggests that there is no significant downstream improvement in citation quality through using the Reranker.
C. Answer Quality Metrics
We separate out the dataset to Answerable, questions with a corresponding response in the knowledge base, and Redirect, questions that require sending a fallback or directing to a human agent. To determine which of these citation and retrieval techniques to leverage, we leverage a reference-based LLM-as-a-judge critic to rate the techniques from a scale of 1-4 based on the following prompt:
Rate how well the generated response answers the user query in the conversation.
Provide reasoning in full sentences and then provide the rating.
Output just one number: 4 for strong, 3 for good, 2 for okay, or 1 for weak.
If the original response says it cannot find an answer or does not answer the user query and the generated response says {no\_answer\_string}, then both are in alignment and the rating should be 4\.
If the conversation style is "Redirect", the generated response should say {no\_answer\_string} or redirect to the company contact information.
Conversation Style: {conversation\_style}
Conversation: {conversation}
Assessement:
Lets think through step by step.
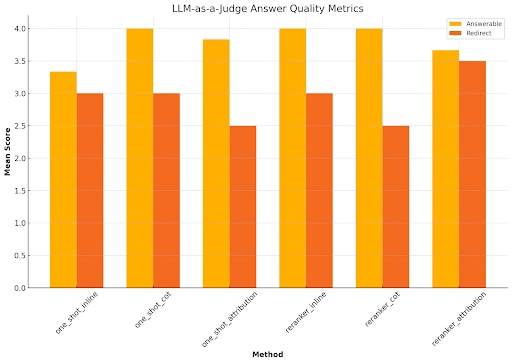
Experiment 3: LLM-as-a-Judge Mean Scores for Answer Quality
Conclusion: One-Shot CoT with citations achieved a perfect 4.0/4.0 mean score on Answerable questions, demonstrating high-quality responses. It also demonstrated strong citation precision of 0.7667 without having to trade off with increased response time associated with using a re-ranker, showing it can mitigate hallucinations and produce high-quality responses. Therefore, in our production deployment, we find that it is most suitable in the tradeoff of answer quality, citation quality, and retrieval time.
Customer Rollout and Adoption
We deployed Sofia QA to several customers and the rollout exceeded all target success metrics, converting two beta customers by February 8 and activating over ten by March 1. By March 31, we measured that more than 50% of inquiries were being successfully resolved. One customer reported a 77% answer rate across 25,000 sessions, while another saw over 50% positive CSAT across 700 conversations. Feedback highlighted a 5/5 setup experience, effective inquiry resolution, and improved answer quality. Customers cited seamless onboarding, no reported bugs, and strong support throughout- demonstrating both the product’s value.
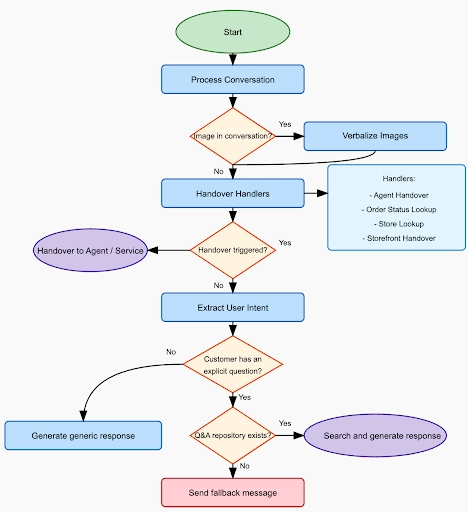
Sofia QA Conversation Flow
Additionally through tracking live user feedback and issuing CSAT surveys, we identified and built several additional capabilities into the Sofia QA bot to improve overall experience. These include specific integrations with Ecommerce Catalog Management and Customer Data platforms to find order status, lookup locations, etc. along with the ability to flag conversations for human review, as shown in the flow diagram above.
Conclusion
Delivering value rapidly with RAG is nontrivial given that a major challenge for adoption is hallucination. Sofia QA demonstrates real-world success of RAG by tackling major challenges informed from practical experience building production-scale user-facing chatbots. Below we highlight the future directions for design and development within RAG.
- Structuring the Knowledge Base: Leveraging more advanced representations of embedded vector DB content through Finite State Machine, Knowledge Graph Representations, or hybrid approaches.
- LLM Performance Optimization: Prompt engineering and LLM performance optimization through automatic model-based techniques.
- Advanced RAG Evaluation Metrics: Advanced model-based assistant evaluation strategies as a proxy for human judgements of RAG performance.
- Planning with LRM: Leveraging RAG within a more advanced information retrieval and decision making AI system to enable multi-hop reasoning and multi-step decision making.
See the Appendix for prompt designs that we explored.
Appendix
A. Prompts & Parameters to Mitigate Hallucinations
Prompting Strategies Note: It may also be useful to include few-shot examples of how to perform citations with example passages.
Chain of Thought: The goal is to improve the accuracy of the outputted result by asking the model to decompose the task and provide its reasoning before giving a response. The intermediate output asks the model to think through the response before providing a final answer.
* Using some system prompt to ask the model to do question answering with citations Pre/Post-Filtering using LLM [Post-filtering] Filtering Out Response Sentence: Given a response provided by the LLM, you can use an LLM to filter out the content that is not supported in the passages.
In-line Sentence Citation: The model will have to cite the passages that are given as context. Then, the message can be post-processed to validate that citations exist and remove them so they do not appear. Preprocess the ID or URL to condense the header sent for the passage, otherwise the model will have a harder time citing long or dense IDs/URLs.
Other citation styles include: [Passage X],
Note: Try to understand what citation formats the model has been trained on. Examples: APA scientific style -(Clark, A. 2009, August 9) or numeric citations- [1]. Leverage those in the instructions provided to the model.
ONE\_SHOT\_RESPONSE\_SYSTEM\_PROMPT \= """In this session, the model has access to search results and a user's question, your job is to answer the user's question using only information from the search results.
Remember to add a citation to the end of your response using markers like %\[1\]%, %\[2\]%, %\[3\]%, etc for the corresponding passage supports the response.
IMPORTANT: If the search results does not contain an answer to the question, you must state exactly "{default\_fallback\_message}".
IMPORTANT: If no passages support the response, do not cite any passages and state exactly "{default\_fallback\_message}".
"""
RESPONSE\_USER\_MESSAGE \= """
{query}
Resource: Search Results: {search\_results}
"""
COT\_RESPONSE\_USER\_MESSAGE\_1 \= """
{query}
Think step-by-step.
"""
COT\_RESPONSE\_USER\_MESSAGE\_2 \= """
{query}
Please follow these steps:
1\. {{Step 1}}
2\. {{Step 2}}
...
"""
COT\_RESPONSE\_USER\_MESSAGE\_3 \= """
{query}
Please follow these steps:
1\. {{Step 1}}
2\. {{Step 2}}
...
{{ User query}}
Think step by step first and then answer. Follow below format when responding
Response Schema:
\
[Post-filtering] Self-Reflection LLM: The strategy of self-reflection encourages the model to critique its own output to self-validate its confidence in the accuracy of its responses. This exists as a separate LLM call that happens after/
COT\_REFLECT\_PROMPT \= """You are an advanced reasoning agent that can improve based on self refection. You will be given a previous reasoning trial in which you were given a question to answer. You were unsuccessful in answering the question either because you guessed the wrong answer with Finish\[\
ATTRIBUTION\_RESPONSE\_CITATION\_PROMPT \= """Add in-line text citations for each of the given statements in \



