













































































































































































![[The AI Show Episode 154]: AI Answers: The Future of AI Agents at Work, Building an AI Roadmap, Choosing the Right Tools, & Responsible AI Use](https://www.marketingaiinstitute.com/hubfs/ep%20154%20cover.png)
![How to Create Your Own AI Toolkit with Taylor Radey [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/MAICON-Speaker_Series-Taylor.png)
![[The AI Show Episode 153]: OpenAI Releases o3-Pro, Disney Sues Midjourney, Altman: “Gentle Singularity” Is Here, AI and Jobs & News Sites Getting Crushed by AI Search](https://www.marketingaiinstitute.com/hubfs/ep%20153%20cover.png)









































































































































































.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)























![GrandChase tier list of the best characters available [June 2025]](https://media.pocketgamer.com/artwork/na-33057-1637756796/grandchase-ios-android-3rd-anniversary.jpg?#)




































































_Frank_Peters_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)







































































































![Apple Weighs Acquisition of AI Startup Perplexity in Internal Talks [Report]](https://www.iclarified.com/images/news/97674/97674/97674-640.jpg)
![Oakley and Meta Launch Smart Glasses for Athletes With AI, 3K Camera, More [Video]](https://www.iclarified.com/images/news/97665/97665/97665-640.jpg)

![How to Get Your Parents to Buy You a Mac, According to Apple [Video]](https://www.iclarified.com/images/news/97671/97671/97671-640.jpg)




















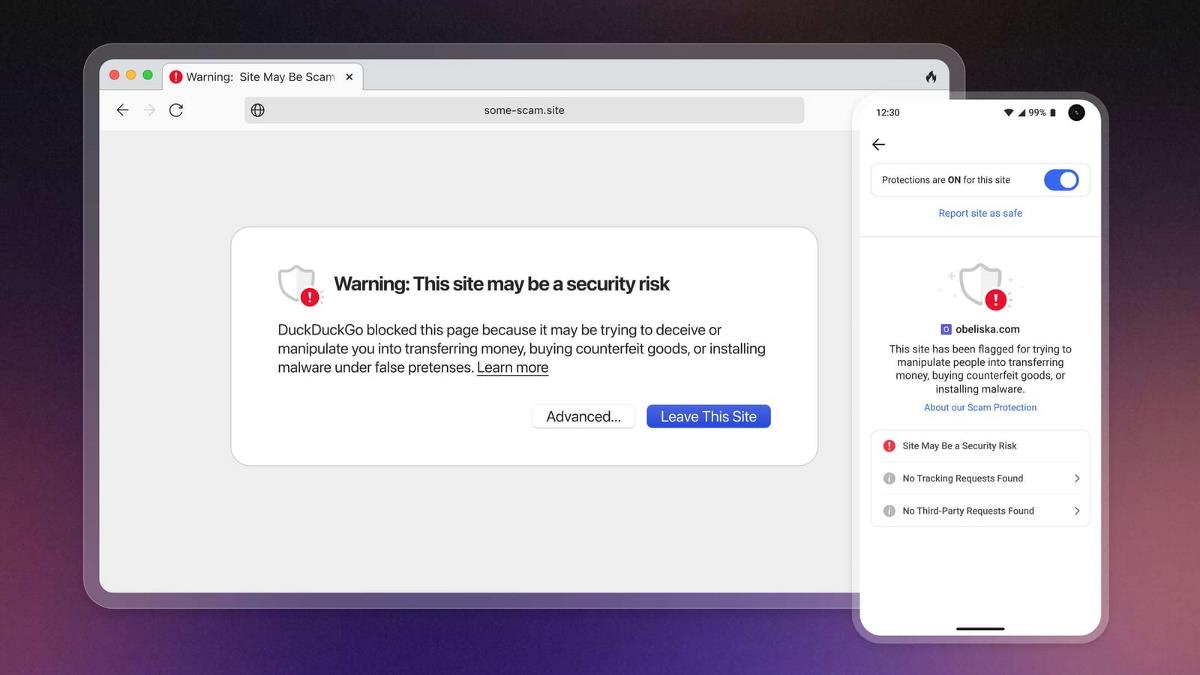
![New accessibility settings announced for Steam Big Picture Mode and SteamOS [Beta]](https://www.ghacks.net/wp-content/uploads/2025/06/New-accessibility-settings-announced-for-Steam-Big-Picture-Mode-and-SteamOS.jpg)










































Pandas vs Polars: Is It Time to Rethink Python’s Trusted DataFrame Library?
For over a decade, Pandas has been the cornerstone of tabular data manipulation in Python. Its intuitive syntax and rich functionality make it the default choice for analysts, data scientists, and researchers worldwide. However, as datasets have grown from megabytes to gigabytes—and now terabytes—the limitations of Pandas are increasingly evident. Enter Polars: a modern, high-performance DataFrame library built for speed and scalability. In this article, we’ll cover: Why Pandas remains popular What makes Polars different A practical benchmark with a large real-world dataset Whether Pandas might eventually be replaced Pandas: A Reliable Workhorse Since its release in 2008, Pandas has dominated data analysis in Python. Its strengths include: Familiar and expressive API (DataFrame, Series) Seamless integration with other Python libraries (NumPy, scikit-learn, matplotlib) Extensive tutorials, examples, and community support However, Pandas was designed for single-threaded execution and expects the entire dataset to fit in memory. This often becomes a bottleneck when working with very large datasets on a laptop or single machine. Polars: A Modern Alternative for High-Performance DataFrames Polars is a newer open-source DataFrame library, written in Rust with Python bindings. It’s designed with performance and scalability in mind: Multi-threaded execution: Polars uses all available CPU cores automatically. Lazy evaluation: Like Spark, Polars can optimize a query plan before executing it. Memory efficiency: Processes data in chunks to avoid excessive memory usage. These design choices allow Polars to handle large datasets much faster and with lower resource consumption than Pandas. Pandas vs Polars: A Real-World Benchmark To see the difference in practice, let’s analyze a real dataset: the NYC Taxi Trip data, which typically has over 20 million rows and is about 3 GB uncompressed. Below is a simple benchmark computing the average trip distance grouped by passenger count, using both libraries. # Install the libraries if needed: # pip install pandas polars import time import pandas as pd import polars as pl # Replace with the path to your CSV file FILE_PATH = "yellow_tripdata_2023-01.csv" # --- Using Pandas --- start = time.time() df_pd = pd.read_csv(FILE_PATH) result_pd = df_pd.groupby("passenger_count")["trip_distance"].mean() print(result_pd) print("Pandas execution time:", time.time() - start) # --- Using Polars --- start = time.time() df_pl = pl.read_csv(FILE_PATH) result_pl = ( df_pl.groupby("passenger_count") .agg(pl.col("trip_distance").mean()) ) print(result_pl) print("Polars execution time:", time.time() - start) Expected results (typical laptop): Pandas: 20–30 seconds, high memory usage Polars: 3–6 seconds, significantly lower memory footprint This highlights how Polars can dramatically speed up large data workflows. When to Use Each Library Aspect Pandas Polars Execution Model Single-threaded Multi-threaded, supports lazy evaluation Performance Good for small to medium data Excellent for large data Memory Usage Entire dataset in RAM Efficient chunk processing API Maturity Highly mature Rapidly evolving Community Support Large & established Growing rapidly Will Pandas Be Replaced? It’s unlikely that Pandas will be phased out anytime soon. Reasons include: Deep integration in the Python ecosystem Many libraries (e.g., scikit-learn, statsmodels) expect Pandas DataFrames Widely taught in courses, bootcamps, and used in countless notebooks In practice, many modern data workflows use both: Pandas for quick exploration and prototyping, Polars for heavy transformations, large datasets, or production-grade pipelines. Key Takeaway Pandas isn’t going anywhere — but Polars is raising the bar for what’s possible on a single machine. If you work with large CSVs, Parquet files, or complex transformations, try Polars on your next project. It’s an easy way to process more data faster, with less hardware overhead. Next Steps Try Polars with your largest dataset Experiment with its lazy API for ETL pipelines Stay comfortable with Pandas for quick analyses and prototyping

For over a decade, Pandas has been the cornerstone of tabular data manipulation in Python. Its intuitive syntax and rich functionality make it the default choice for analysts, data scientists, and researchers worldwide.
However, as datasets have grown from megabytes to gigabytes—and now terabytes—the limitations of Pandas are increasingly evident. Enter Polars: a modern, high-performance DataFrame library built for speed and scalability.
In this article, we’ll cover:
- Why Pandas remains popular
- What makes Polars different
- A practical benchmark with a large real-world dataset
- Whether Pandas might eventually be replaced
Pandas: A Reliable Workhorse
Since its release in 2008, Pandas has dominated data analysis in Python. Its strengths include:
- Familiar and expressive API (
DataFrame,Series) - Seamless integration with other Python libraries (NumPy, scikit-learn, matplotlib)
- Extensive tutorials, examples, and community support
However, Pandas was designed for single-threaded execution and expects the entire dataset to fit in memory. This often becomes a bottleneck when working with very large datasets on a laptop or single machine.
Polars: A Modern Alternative for High-Performance DataFrames
Polars is a newer open-source DataFrame library, written in Rust with Python bindings. It’s designed with performance and scalability in mind:
- Multi-threaded execution: Polars uses all available CPU cores automatically.
- Lazy evaluation: Like Spark, Polars can optimize a query plan before executing it.
- Memory efficiency: Processes data in chunks to avoid excessive memory usage.
These design choices allow Polars to handle large datasets much faster and with lower resource consumption than Pandas.
Pandas vs Polars: A Real-World Benchmark
To see the difference in practice, let’s analyze a real dataset: the NYC Taxi Trip data, which typically has over 20 million rows and is about 3 GB uncompressed.
Below is a simple benchmark computing the average trip distance grouped by passenger count, using both libraries.
# Install the libraries if needed:
# pip install pandas polars
import time
import pandas as pd
import polars as pl
# Replace with the path to your CSV file
FILE_PATH = "yellow_tripdata_2023-01.csv"
# --- Using Pandas ---
start = time.time()
df_pd = pd.read_csv(FILE_PATH)
result_pd = df_pd.groupby("passenger_count")["trip_distance"].mean()
print(result_pd)
print("Pandas execution time:", time.time() - start)
# --- Using Polars ---
start = time.time()
df_pl = pl.read_csv(FILE_PATH)
result_pl = (
df_pl.groupby("passenger_count")
.agg(pl.col("trip_distance").mean())
)
print(result_pl)
print("Polars execution time:", time.time() - start)
Expected results (typical laptop):
- Pandas: 20–30 seconds, high memory usage
- Polars: 3–6 seconds, significantly lower memory footprint
This highlights how Polars can dramatically speed up large data workflows.
When to Use Each Library
| Aspect | Pandas | Polars |
|---|---|---|
| Execution Model | Single-threaded | Multi-threaded, supports lazy evaluation |
| Performance | Good for small to medium data | Excellent for large data |
| Memory Usage | Entire dataset in RAM | Efficient chunk processing |
| API Maturity | Highly mature | Rapidly evolving |
| Community Support | Large & established | Growing rapidly |
Will Pandas Be Replaced?
It’s unlikely that Pandas will be phased out anytime soon. Reasons include:
- Deep integration in the Python ecosystem
- Many libraries (e.g., scikit-learn, statsmodels) expect Pandas DataFrames
- Widely taught in courses, bootcamps, and used in countless notebooks
In practice, many modern data workflows use both:
Pandas for quick exploration and prototyping, Polars for heavy transformations, large datasets, or production-grade pipelines.
Key Takeaway
Pandas isn’t going anywhere — but Polars is raising the bar for what’s possible on a single machine.
If you work with large CSVs, Parquet files, or complex transformations, try Polars on your next project. It’s an easy way to process more data faster, with less hardware overhead.
Next Steps
Try Polars with your largest dataset
Experiment with its lazy API for ETL pipelines
Stay comfortable with Pandas for quick analyses and prototyping


