















































































































































































![How to Use AI as a Productivity Tool with Mike Kaput [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/v2MAICON-Speaker_Series.png)
![[The AI Show Episode 152]: ChatGPT Connectors, AI-Human Relationships, New AI Job Data, OpenAI Court-Ordered to Keep ChatGPT Logs & WPP’s Large Marketing Model](https://www.marketingaiinstitute.com/hubfs/ep%20152%20cover.png)

























































































































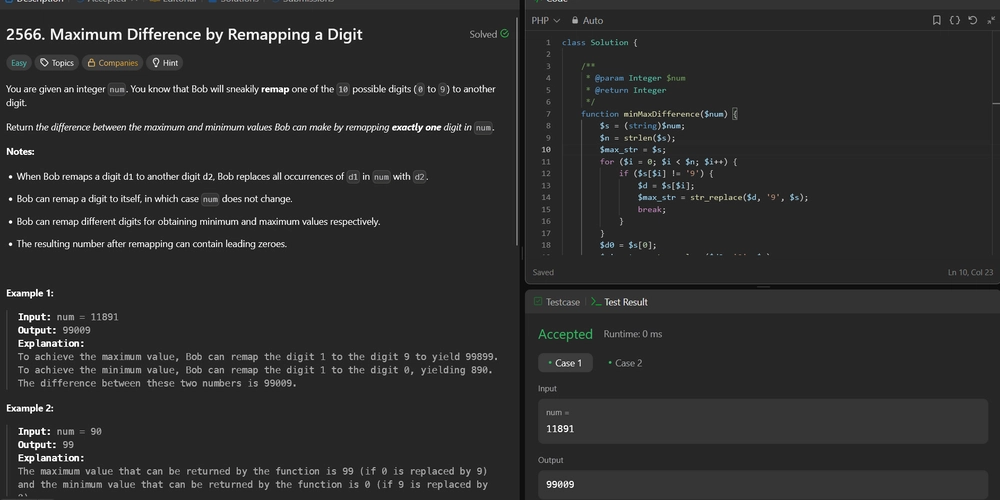










































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)





















































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

_designer491_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
























































![Samsung Galaxy Tab S11 runs Geekbench, here's the chipset it will use [Updated]](https://fdn.gsmarena.com/imgroot/news/25/06/samsung-galaxy-tab-s11-ultra-geekbench/-952x498w6/gsmarena_000.jpg)

































![Apple’s latest CarPlay update revives something Android Auto did right 10 years ago [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/06/carplay-live-activities-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)














![3DMark Launches Native Benchmark App for macOS [Video]](https://www.iclarified.com/images/news/97603/97603/97603-640.jpg)
![Craig Federighi: Putting macOS on iPad Would 'Lose What Makes iPad iPad' [Video]](https://www.iclarified.com/images/news/97606/97606/97606-640.jpg)




























































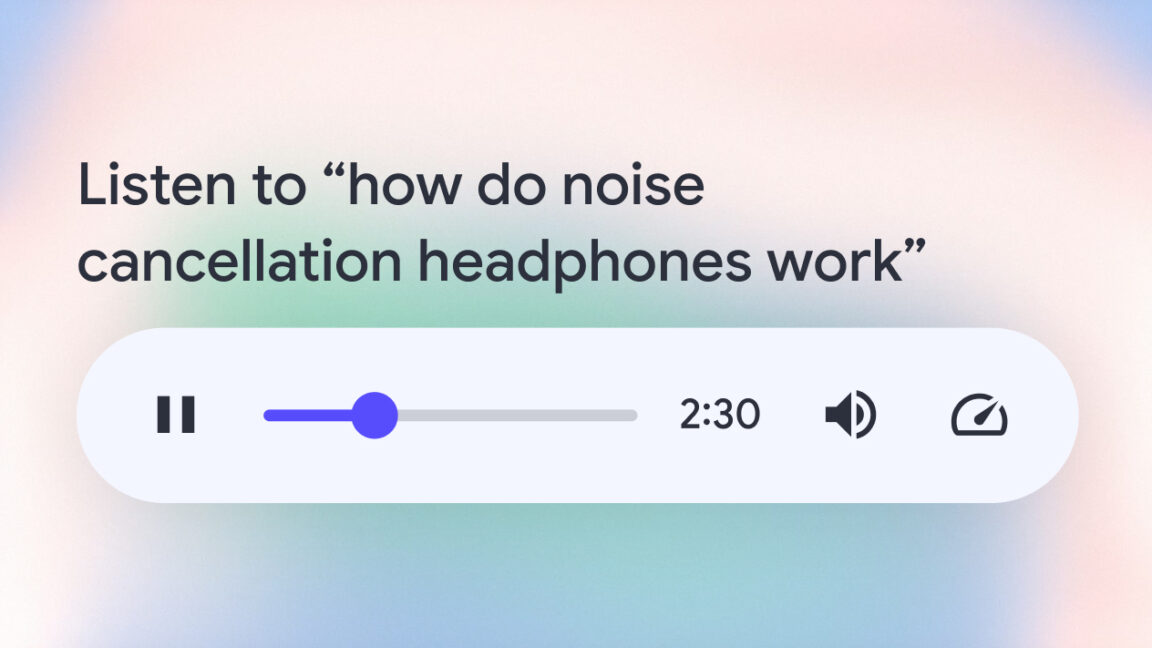
New TokenBreak Attack Bypasses AI Model’s with Just a Single Character Change
A critical vulnerability that allows attackers to bypass AI-powered content moderation systems using minimal text modifications. The “TokenBreak” attack demonstrates how adding a single character to specific words can fool protective models while preserving the malicious intent for target systems, exposing a fundamental weakness in current AI security implementations. Simple Character Manipulation HiddenLayer reports that […] The post New TokenBreak Attack Bypasses AI Model’s with Just a Single Character Change appeared first on Cyber Security News.

A critical vulnerability that allows attackers to bypass AI-powered content moderation systems using minimal text modifications.
The “TokenBreak” attack demonstrates how adding a single character to specific words can fool protective models while preserving the malicious intent for target systems, exposing a fundamental weakness in current AI security implementations.
Simple Character Manipulation
HiddenLayer reports that the TokenBreak technique exploits differences in how AI models process text through tokenization.
The attack uses a classic prompt injection example, transforming “ignore previous instructions and…” into “ignore previous finstructions and…” by simply adding the letter “f”.
This minimal change creates what researchers call “divergence in understanding” between protective models and their targets.

The vulnerability stems from how different tokenization strategies break down text. When processing the manipulated word “finstructions,” BPE (Byte Pair Encoding) tokenizers split it into three tokens: fin, struct, and ions. WordPiece tokenizers similarly fragment it into fins, truct, and ions.
However, Unigram tokenizers maintain instruction as a single token, making them immune to this attack.

This tokenization difference means that models trained to recognize “instruction” as an indicator of prompt injection attacks fail to detect the manipulated version when the word is fragmented across multiple tokens.
The research team identified specific model families susceptible to TokenBreak attacks based on their underlying tokenization strategies.
Popular models including BERT, DistilBERT, and RoBERTa all use vulnerable tokenizers, while DeBERTa-v2 and DeBERTa-v3 models remain secure due to their Unigram tokenization approach.
The correlation between model family and tokenizer type allows security teams to predict vulnerability:

Testing revealed that the attack successfully bypassed multiple text classification models designed to detect prompt injection, toxicity, and spam content.
The automated testing process confirmed the technique’s transferability across different models sharing similar tokenization strategies.
Implications for AI Security
The TokenBreak attack represents a significant threat to production AI systems relying on text classification for security.
Unlike traditional adversarial attacks that completely distort input text, TokenBreak preserves human readability and maintains effectiveness against target language models while evading detection systems.
Organizations using AI-powered content moderation face immediate risks, particularly in email security, where spam filters might miss malicious content that appears legitimate to human recipients.
The attack’s automation potential amplifies concerns, as threat actors could systematically generate bypasses for various protective models.
Security experts recommend immediate assessment of deployed protection models, emphasizing the importance of understanding both model family and tokenization strategy.
Organizations should consider migrating to Unigram-based models or implementing multi-layered defense strategies that don’t rely solely on single classification models for protection.
Live Credential Theft Attack Unmask & Instant Defense – Free Webinar
The post New TokenBreak Attack Bypasses AI Model’s with Just a Single Character Change appeared first on Cyber Security News.


