









































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)





























































































































![From Accountant to Data Engineer with Alyson La [Podcast #168]](https://cdn.hashnode.com/res/hashnode/image/upload/v1744420903260/fae4b593-d653-41eb-b70b-031591aa2f35.png?#)




































































































.png?#)










































































































































![Apple Watch SE 2 On Sale for Just $169.97 [Deal]](https://www.iclarified.com/images/news/96996/96996/96996-640.jpg)

![Apple Posts Full First Episode of 'Your Friends & Neighbors' on YouTube [Video]](https://www.iclarified.com/images/news/96990/96990/96990-640.jpg)


























































































































Llama 4 - 10M Context? Coding? Decent Follow-up?
Meta has brought the long-awaited Llama 4 models on Saturday, April 5. Llama 3 came out on April 26, 2024, so this year Meta came earlier, looks like a good sign. The newer models were retrained on (!)40T tokens, an almost 3x bump from the previous version's 15T training dataset. The model brought plenty of changes, including MoE architecture, multi-modality, huge context windows, a giant 2T version behind the scenes, and evaluations showing that the model matches other SOTA models. And yet I didn't find the release exciting. No Longer "Local LLaMA" None of the released models are of reasonable sizes. Llama 2 had 7B and 13B variants, and Llama 3 came at 8B the first day. The name "llama" became a synonym for LLM hobbyist tinkering with local execution, large communities were formed around the Llama family of models... There are super popular projects that bear the name: llama.cpp is probably the most popular runtime for local models (not just Llama). There's a whole ecosystem with llama.cpp's native GGUF model format Ollama might be the most popular tool to discover, download, and run GGUF models locally. locall_LLaMa is a subreddit with 426K users In 2023 Llama models ignited open-source research in LLMs, papers were published, enthusiasts fine-tuned models on their gaming GPUs, and tinkering recipes flooded the internet. Alpacas, Vicunas, Wizards (and plenty of other fine-tunes) were published as open-weight models. At that time there was the famous "We Have No Moat" leaked document questioning Google's ability to succeed in the LLM race while against Open-source community (equipped with Llama)... With Meta boasting how the smallest 109B Llama 4 Scout can fit into a single $20k H100 GPU I don't see how the new models can be treated as a follow-up Llama 1, 2, 3. As of now the lineage is broken, and there's no clue if true local models are coming. Long Context The new models promised super huge context windows at 1M and 10M tokens - something unseen in open models. There's also a claim of nearly perfect retrieval in the "Needle in the Haystack" test: A few weeks ago I've found an interesting take context window eval, the one testing models' comprehension - if they can truly understand long texts, build mental representations and retaliations between subjects, answer complicated questions - Fiction.liveBench. For some reason their version of the results is not sorted/colorized, here's the April 6 version I formatted: The ranking puts Llama 4 to the bottom :( Coding Another disappointment came from the AIDER benchmark - here the larger 400B Maverick model occupies the bottom part of the leaderboard right below Qwen2.5-Coder-32B-Instruct. Here are a few items from the leaderboard: claude-3-7 (no thinking): 60.4% claude-3-5-sonnet-20241022: 51.6% Qwen2.5-Coder-32B-Instruct: 16.4% Llama 4 Maverick: 15.6% Yet if we look at the coding part of the LiveBench suddenly Maverick is not that bad, it's actually great! The model is above Claude 3.5 and 3.7, Anthropic models that earned the reputation of best ones for programmers. AI Benchmarks Skepticism After I created my own LLM Chess benchmark I care about benchmark scores much less :) My experience with LLMs can be summarised with a simple statement "sometimes they work, sometimes they don't". LLM performance is very task specific, the same model used inside IDE can shine with one request and fail miserably with another. If one took at face value needle-in-the-haystack results for Llama 4, one would be convinced it is the best model long prompts supporting the largest models. The ones coming from Fiction.liveBench would cross out Llama 4 as garbage. The same polar conclusions will come after evaluating coding abilities based on Aider and LiveBench figures. There has been plenty of criticism towards evals. People complain that they don't tell the full story, they do not reflect their real-life experience. E.g. there is valid criticism that HumanEval could be a good coding benchmark in 2021 at the dawn of chat models yet it is barely relevant to the day-to-day routine of software engineers. Many evals are just fixed questions with well-known answers and LLMs are great at memorizing - there's is a valid point questioning any static "question - right answer" kind of benchmark... And suspecting AI labs in "overfitting" (or simply put cheating) on benchmarks - after all there are huge incentives to score great in those press releases. LMArena (aka LMSys, Chatbot Arena) is often one of the key metrics that AI shops boast upon releases - this is a rating score testifying human preferences. Yet for quite some time this score is just noise for me... And this study demonstrated how easy it is to trick humans overoptimizing via RLHF. By the way, there's a sketchy story with a loud intro of Llama 4 as the 2nd best in the arena... Followed by users suspecting something was not playing out and an official cla
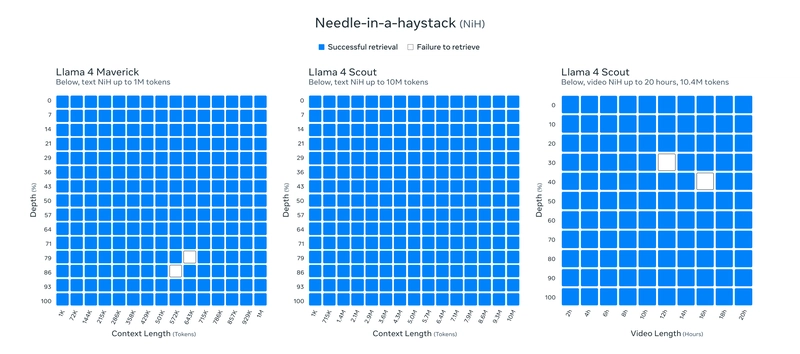
Meta has brought the long-awaited Llama 4 models on Saturday, April 5. Llama 3 came out on April 26, 2024, so this year Meta came earlier, looks like a good sign. The newer models were retrained on (!)40T tokens, an almost 3x bump from the previous version's 15T training dataset. The model brought plenty of changes, including MoE architecture, multi-modality, huge context windows, a giant 2T version behind the scenes, and evaluations showing that the model matches other SOTA models. And yet I didn't find the release exciting.
No Longer "Local LLaMA"
None of the released models are of reasonable sizes. Llama 2 had 7B and 13B variants, and Llama 3 came at 8B the first day. The name "llama" became a synonym for LLM hobbyist tinkering with local execution, large communities were formed around the Llama family of models... There are super popular projects that bear the name:
-
llama.cppis probably the most popular runtime for local models (not just Llama). There's a whole ecosystem with llama.cpp's nativeGGUFmodel format - Ollama might be the most popular tool to discover, download, and run
GGUFmodels locally. -
locall_LLaMais a subreddit with 426K users
In 2023 Llama models ignited open-source research in LLMs, papers were published, enthusiasts fine-tuned models on their gaming GPUs, and tinkering recipes flooded the internet. Alpacas, Vicunas, Wizards (and plenty of other fine-tunes) were published as open-weight models. At that time there was the famous "We Have No Moat" leaked document questioning Google's ability to succeed in the LLM race while against Open-source community (equipped with Llama)...
With Meta boasting how the smallest 109B Llama 4 Scout can fit into a single $20k H100 GPU I don't see how the new models can be treated as a follow-up Llama 1, 2, 3. As of now the lineage is broken, and there's no clue if true local models are coming.
Long Context
The new models promised super huge context windows at 1M and 10M tokens - something unseen in open models. There's also a claim of nearly perfect retrieval in the "Needle in the Haystack" test:
A few weeks ago I've found an interesting take context window eval, the one testing models' comprehension - if they can truly understand long texts, build mental representations and retaliations between subjects, answer complicated questions - Fiction.liveBench.
For some reason their version of the results is not sorted/colorized, here's the April 6 version I formatted:
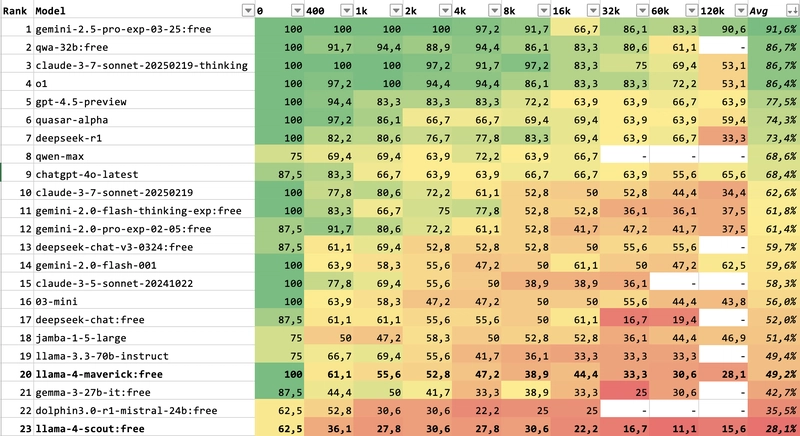
The ranking puts Llama 4 to the bottom :(
Coding
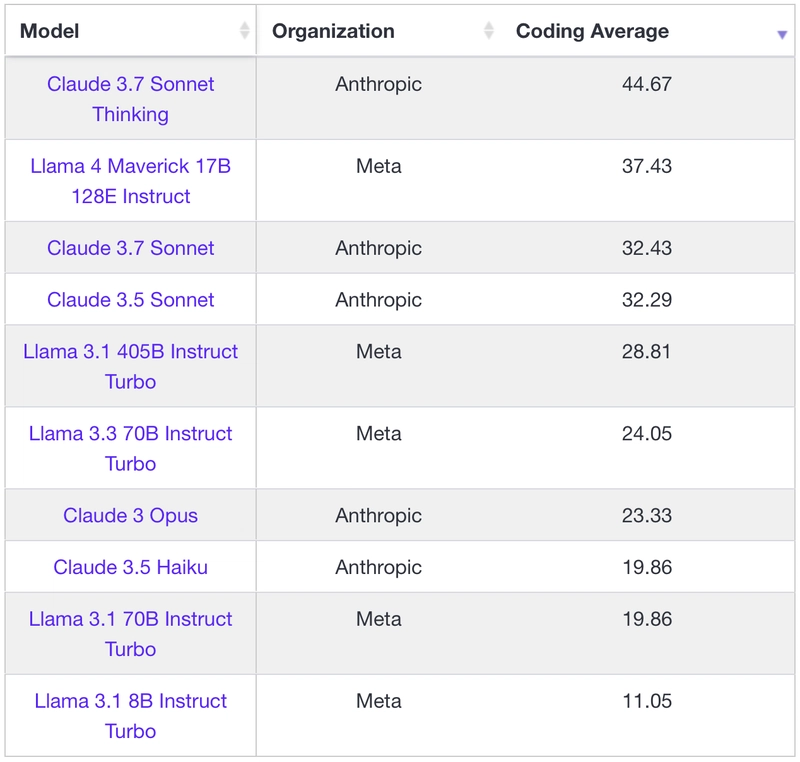
Another disappointment came from the AIDER benchmark - here the larger 400B Maverick model occupies the bottom part of the leaderboard right below Qwen2.5-Coder-32B-Instruct. Here are a few items from the leaderboard:
- claude-3-7 (no thinking): 60.4%
- claude-3-5-sonnet-20241022: 51.6%
- Qwen2.5-Coder-32B-Instruct: 16.4%
- Llama 4 Maverick: 15.6%
Yet if we look at the coding part of the LiveBench suddenly Maverick is not that bad, it's actually great! The model is above Claude 3.5 and 3.7, Anthropic models that earned the reputation of best ones for programmers.
AI Benchmarks Skepticism
After I created my own LLM Chess benchmark I care about benchmark scores much less :) My experience with LLMs can be summarised with a simple statement "sometimes they work, sometimes they don't". LLM performance is very task specific, the same model used inside IDE can shine with one request and fail miserably with another.
If one took at face value needle-in-the-haystack results for Llama 4, one would be convinced it is the best model long prompts supporting the largest models. The ones coming from Fiction.liveBench would cross out Llama 4 as garbage. The same polar conclusions will come after evaluating coding abilities based on Aider and LiveBench figures.
There has been plenty of criticism towards evals. People complain that they don't tell the full story, they do not reflect their real-life experience. E.g. there is valid criticism that HumanEval could be a good coding benchmark in 2021 at the dawn of chat models yet it is barely relevant to the day-to-day routine of software engineers. Many evals are just fixed questions with well-known answers and LLMs are great at memorizing - there's is a valid point questioning any static "question - right answer" kind of benchmark... And suspecting AI labs in "overfitting" (or simply put cheating) on benchmarks - after all there are huge incentives to score great in those press releases.
LMArena (aka LMSys, Chatbot Arena) is often one of the key metrics that AI shops boast upon releases - this is a rating score testifying human preferences. Yet for quite some time this score is just noise for me... And this study demonstrated how easy it is to trick humans overoptimizing via RLHF.
By the way, there's a sketchy story with a loud intro of Llama 4 as the 2nd best in the arena... Followed by users suspecting something was not playing out and an official clarifications that arena's Llama 4 (a) was neither the Scout or Maverick version released and (b) was specifically tuned for human preferences (to score higher). Not cheating, "optimising for human preferences" as they say :)
P.S>
I have my reservations in regards to fictionLive.bench. While I like the idea there's little info on implementation, there's no code, no tech report... There're many things that make the inner perfectionist unhappy: what is the token-size of 0-token story, how many questions are there, why not rank the models by average? If same attention to detail characterises the actual implementation, I question the findings...
P.P.S>
My LLM Chess Eval has recently brought similar contradictions in evals. Gemma 2 was one of the best open models in the leaderboard, it was consistent in the game loop demonstrating solid instruction following - I would say the best out of smaller models. These results related to my own chatting experience putting Gemma 2 models above Llama 3. Gemma 3 release got me excited, I anticipated a successor that will surpass the previous model. And it didn't happen :)
P.P.P.S>
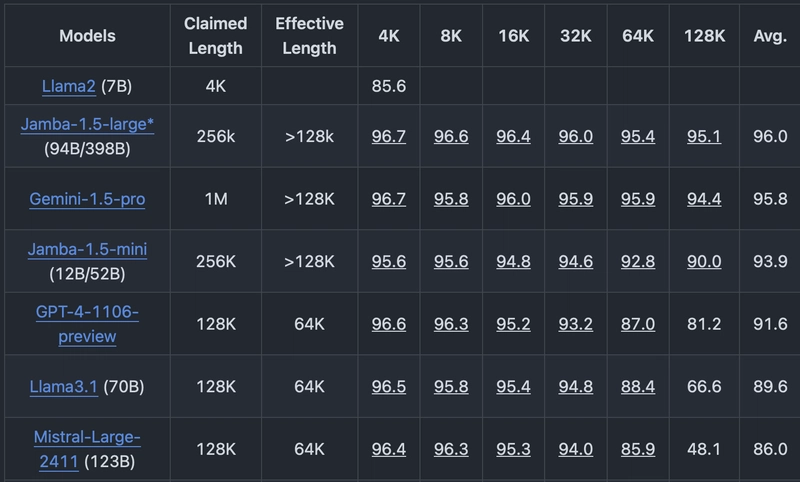
Context window size interested me for quite a while. Here's my article putting into perspective token sizes of various artifacts. I've been keeping eye on related evals, unfortunately, there're not many (the aforementioned needle in the haystack, Ruler). My own intuition is that even 10% or 20% percent of context can be too much and degrade LLM performance - I am one of those guys who starts clean chats for every small conversation.
When you check the headboards you can notice that there's always never 100% accuracy in retrieval or it drops right away, e.g. at 1k tokens. Take from example Ruler:
When I used tools such as Perplexity, or DeepResearch, or ant RAG based chatbot I always have this at the back of my mind, anticipation that there're plenty inaccuracies and missed bits in the generated responses.
Here's a my story of (unproductive) use of GPT-4.5 to convert the aforementioned fiction.live Bench into a table to colorize and sort in Excel (the screenshot I shared above).



