








































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)






























































































































![From Accountant to Data Engineer with Alyson La [Podcast #168]](https://cdn.hashnode.com/res/hashnode/image/upload/v1744420903260/fae4b593-d653-41eb-b70b-031591aa2f35.png?#)





































































































.png?#)









































































































































![Apple Watch SE 2 On Sale for Just $169.97 [Deal]](https://www.iclarified.com/images/news/96996/96996/96996-640.jpg)

![Apple Posts Full First Episode of 'Your Friends & Neighbors' on YouTube [Video]](https://www.iclarified.com/images/news/96990/96990/96990-640.jpg)




























































































































Hera Developer Survey 2025
We recently ran the first-ever Hera developer survey, with great results! The goal of this survey was to inform the roadmap of Hera, so we are thrilled with the 34 responses and the broad range of feedback and insights that we’ve got. This post will summarise and interpret some of the results – look out for the roadmap coming at a later date! Roles and Use Cases We had a good spread of roles, but mainly Software Engineers and Machine Learning Engineers representing just over 50% of responses. A few respondents added their own answer with some variation of “all of the above”, so they are collected together in the results. We had only two Data Engineer responses, which could mean people consider “data engineering” to be a part of their day-to-day and not their job title, or that Data Engineers aren’t using Hera (or Argo Workflows) – tough to make any conclusions here. In terms of use cases, for this question, respondents were asked to select the 3 most relevant options. Machine Learning and Data Science lead the pack, with Batch Data Processing not far behind. There are varying data processing use cases, including ETL/ELT (which suggests the respondents do consider Data Engineering a part of the day-to-day) and Image/Video Processing. Finally, some folks are using Hera for CI/CD (which is surprising!) and other task automation (via custom responses). Hera Features Usage In this section of the survey we wanted to confirm where the main value-adds of Hera are, which means finding out the features that are being actively used. The results show a roughly equal balance of users generating YAML for separate consumption / processing, and users interacting with the Argo Workflows server directly through Hera. What was especially surprising was that no respondents said they are using Hera in Jupyter Notebooks! There are a few possible conclusions we can draw from that: Respondents don’t use Jupyter at all There is no need to use Hera in Notebooks There is a need, but it’s not possible to use Hera in Notebooks (note, only inline script templates can be used in Notebooks, as runner templates require an image of the code to be built) Considering the lack of GitHub issues and Slack questions mentioning Jupyter, I’m inclined to say it’s at least not the third option. The next question was to confirm the key feature of Hera, turning Python functions into templates, was being used by the community, and if so, which flavour – “inline” or “runner”. It’s surprising to see a substantial number, ~20%, only use Hera to arrange non-script templates, which suggests Hera is still valuable just to be able to define Workflows in Python, even if the business logic isn’t contained in Python functions. Beyond this use case, we see good adoption of the Hera Runner, while the “inline” templates make up the majority percentage of the results, suggesting we should still look to improve the template authoring experience for these users, for example through better input Parameter / Artifact handling. Where the Community Gets Updates The final closed-options question was looking to find out where users learn about Hera’s newest features. The docs website leads the results, which suggests a specific section to shout-out “new features” for readers would be helpful. This could be combined with a “breaking changes” section (though we have generally avoided breaking changes to non-experimental features). Users also naturally explore the code themselves, so we should aim to keep the codebase clean and commented. The GitHub release notes are automated, while the Slack announcement is adapted from the release notes, and often expanded on, so we’ll keep doing these!
We recently ran the first-ever Hera developer survey, with great results! The goal of this survey was to inform the roadmap of Hera, so we are thrilled with the 34 responses and the broad range of feedback and insights that we’ve got. This post will summarise and interpret some of the results – look out for the roadmap coming at a later date!
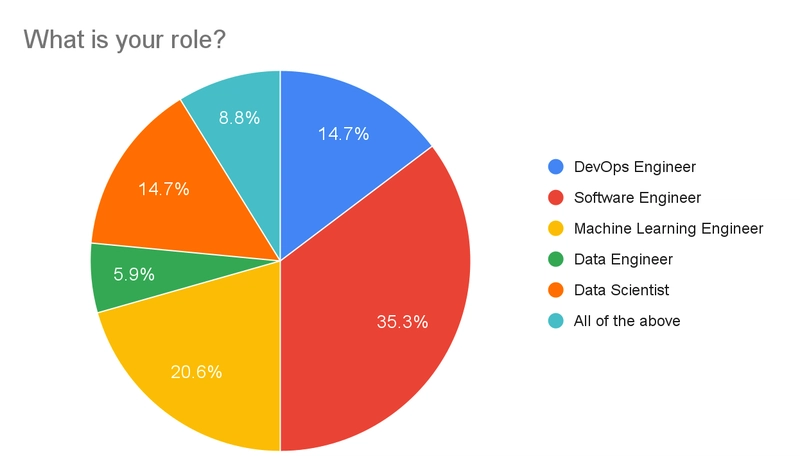
Roles and Use Cases
We had a good spread of roles, but mainly Software Engineers and Machine Learning Engineers representing just over 50% of responses. A few respondents added their own answer with some variation of “all of the above”, so they are collected together in the results. We had only two Data Engineer responses, which could mean people consider “data engineering” to be a part of their day-to-day and not their job title, or that Data Engineers aren’t using Hera (or Argo Workflows) – tough to make any conclusions here.
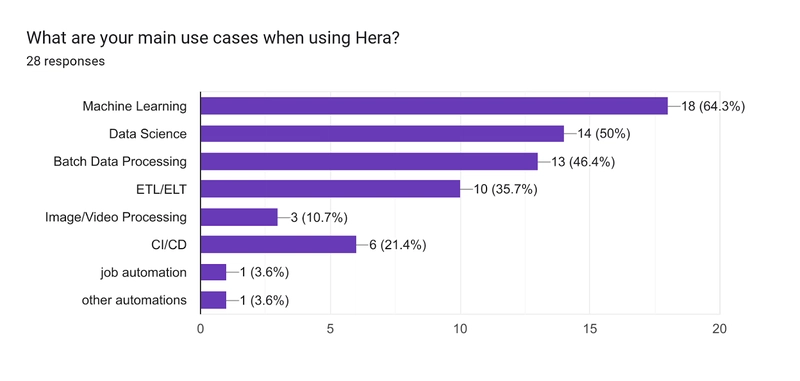
In terms of use cases, for this question, respondents were asked to select the 3 most relevant options. Machine Learning and Data Science lead the pack, with Batch Data Processing not far behind. There are varying data processing use cases, including ETL/ELT (which suggests the respondents do consider Data Engineering a part of the day-to-day) and Image/Video Processing. Finally, some folks are using Hera for CI/CD (which is surprising!) and other task automation (via custom responses).
Hera Features Usage
In this section of the survey we wanted to confirm where the main value-adds of Hera are, which means finding out the features that are being actively used.
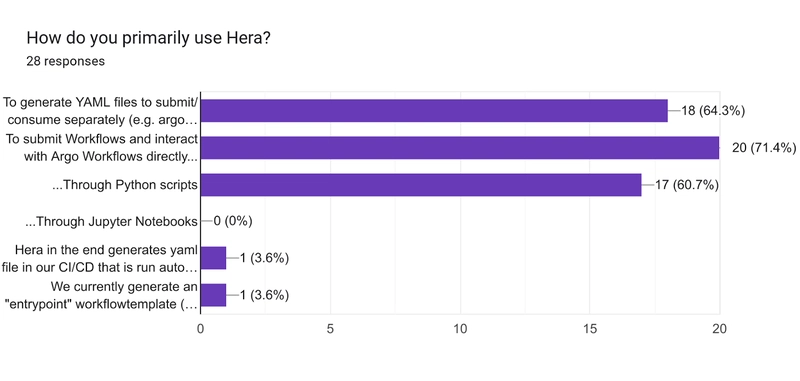
The results show a roughly equal balance of users generating YAML for separate consumption / processing, and users interacting with the Argo Workflows server directly through Hera.
What was especially surprising was that no respondents said they are using Hera in Jupyter Notebooks! There are a few possible conclusions we can draw from that:
- Respondents don’t use Jupyter at all
- There is no need to use Hera in Notebooks
- There is a need, but it’s not possible to use Hera in Notebooks (note, only inline script templates can be used in Notebooks, as runner templates require an image of the code to be built)
Considering the lack of GitHub issues and Slack questions mentioning Jupyter, I’m inclined to say it’s at least not the third option.
The next question was to confirm the key feature of Hera, turning Python functions into templates, was being used by the community, and if so, which flavour – “inline” or “runner”.
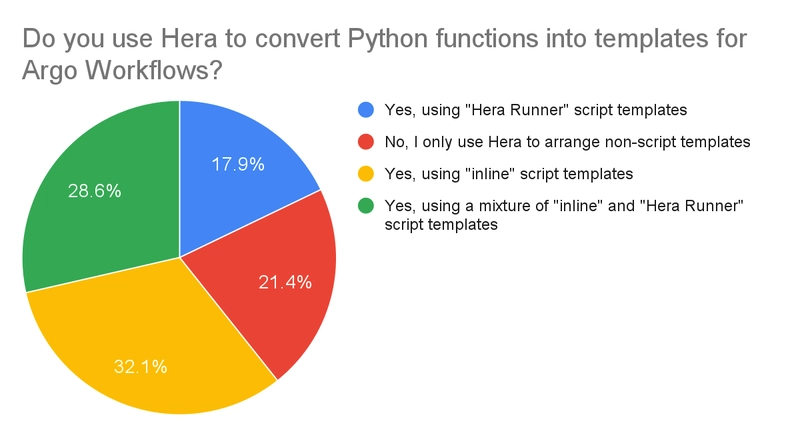
It’s surprising to see a substantial number, ~20%, only use Hera to arrange non-script templates, which suggests Hera is still valuable just to be able to define Workflows in Python, even if the business logic isn’t contained in Python functions. Beyond this use case, we see good adoption of the Hera Runner, while the “inline” templates make up the majority percentage of the results, suggesting we should still look to improve the template authoring experience for these users, for example through better input Parameter / Artifact handling.
Where the Community Gets Updates
The final closed-options question was looking to find out where users learn about Hera’s newest features.
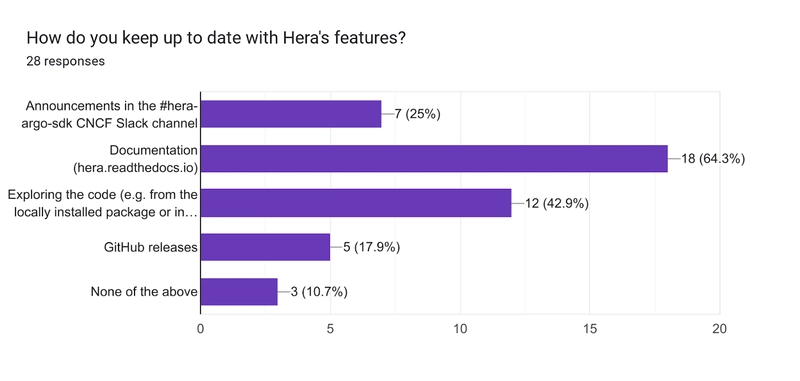
The docs website leads the results, which suggests a specific section to shout-out “new features” for readers would be helpful. This could be combined with a “breaking changes” section (though we have generally avoided breaking changes to non-experimental features). Users also naturally explore the code themselves, so we should aim to keep the codebase clean and commented. The GitHub release notes are automated, while the Slack announcement is adapted from the release notes, and often expanded on, so we’ll keep doing these!



