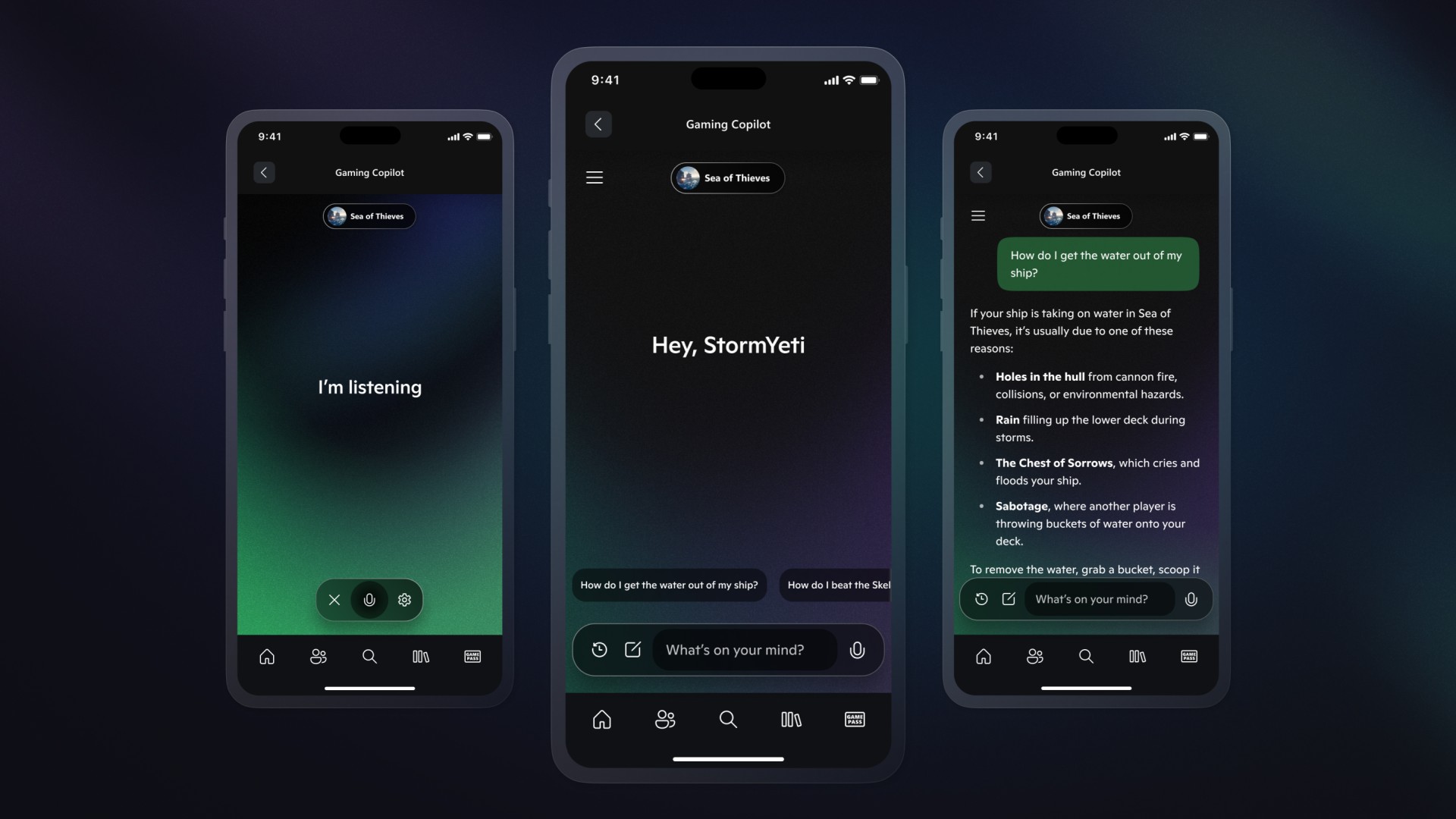
![[The AI Show Episode 154]: AI Answers: The Future of AI Agents at Work, Building an AI Roadmap, Choosing the Right Tools, & Responsible AI Use](https://www.marketingaiinstitute.com/hubfs/ep%20154%20cover.png)
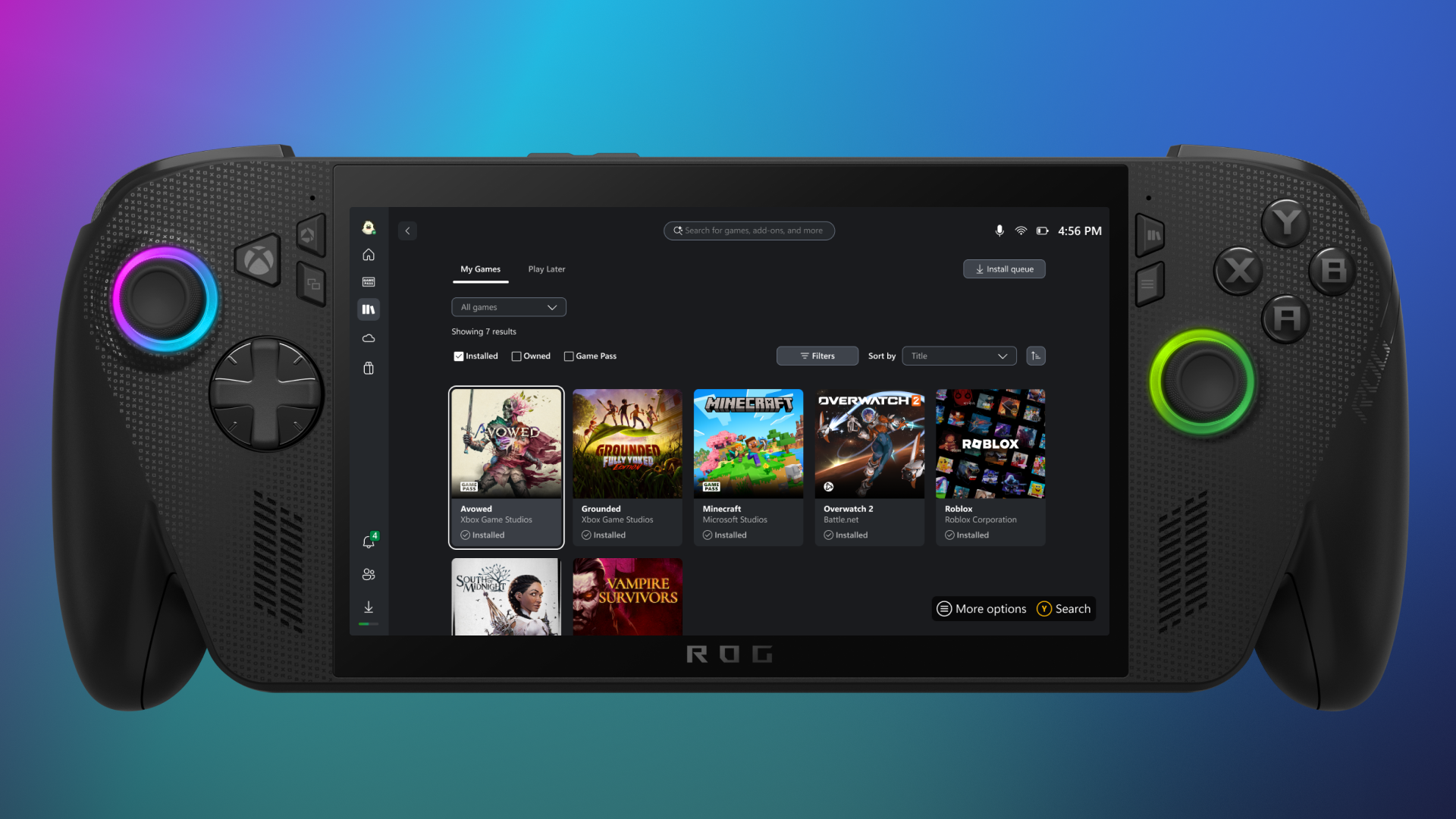
![How to Create Your Own AI Toolkit with Taylor Radey [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/MAICON-Speaker_Series-Taylor.png)
![[The AI Show Episode 153]: OpenAI Releases o3-Pro, Disney Sues Midjourney, Altman: “Gentle Singularity” Is Here, AI and Jobs & News Sites Getting Crushed by AI Search](https://www.marketingaiinstitute.com/hubfs/ep%20153%20cover.png)






























































































































































































![GrandChase tier list of the best characters available [June 2025]](https://media.pocketgamer.com/artwork/na-33057-1637756796/grandchase-ios-android-3rd-anniversary.jpg?#)






































.jpg?#)

























_marcos_alvarado_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)


























































































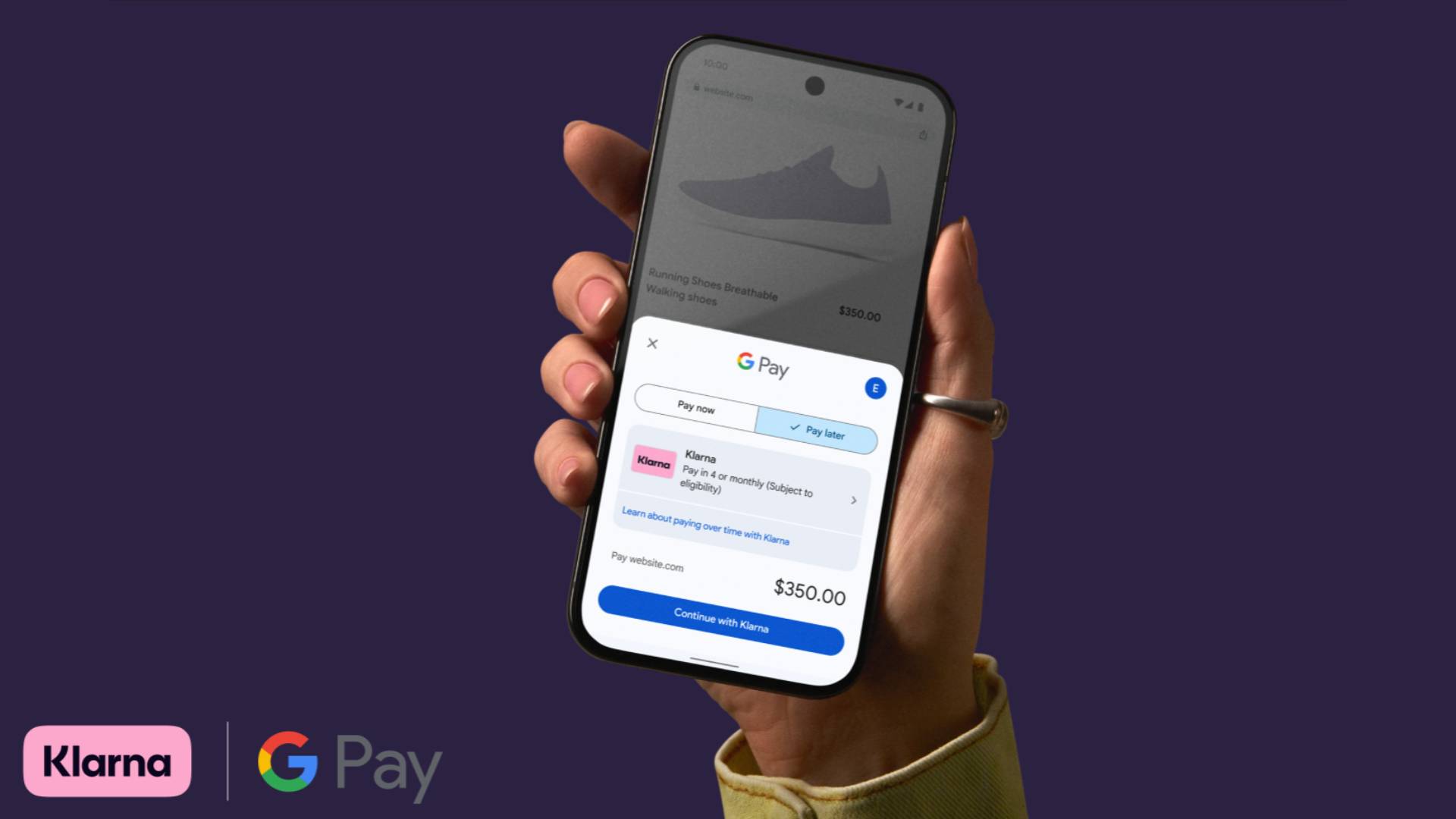




















![Apple in Last-Minute Talks to Avoid More EU Fines Over App Store Rules [Report]](https://www.iclarified.com/images/news/97680/97680/97680-640.jpg)


![Apple Seeds tvOS 26 Beta 2 to Developers [Download]](https://www.iclarified.com/images/news/97691/97691/97691-640.jpg)


























































Gradient Descent on Token Input Embeddings: A ModernBERT experiment
Input Embedding Space Gradients This is the first in a series of posts on the question: "Can we extract meaningful information or interesting behavior from gradients on 'input embedding space'?" I'm defining 'input embedding space' as the token embeddings prior to positional encoding. The basic procedure for obtaining input space gradients is as follows: Transform tokens into input embeddings (but do not apply positional embedding). Run an ordinary forward pass on the input embeddings to obtain a predicted token distribution. Measure cross-entropy of the predicted distribution with a target token distribution. Use autograd to calculate gradients on the input embeddings with respect to cross entropy. The result is a tensor of the same shape as the input embeddings that points in the direction of minimizing the difference between the predicted and target distribution. Implementation These experiments were performed with HuggingFace's transformers library and the ModernBERT-large model. ModernBERT-large was chosen because it is relatively lightweight model with a strong visualization suite and a simplified attention mask (full cross-attention) that is easy to reason about. It would be interesting to see if the results in this post hold across other models. I used HuggingFace's transformers because it allowed for fairly low level access to model internals - which was quite necessary as we will see. Obtaining input embeddings prior to positional embeddings was a little tricky but no means impossible: tokenizer = AutoTokenizer.from_pretrained(MODEL) model = AutoModelForMaskedLM.from_pretrained(MODEL) tokenized = tokenizer(sentences, return_tensors="pt", padding=True) inputs_embeds = model.model.embeddings.tok_embeddings(tokenized['input_ids']) Luckily for us, we can pass input_embeds directly into the model's forward pass with a little bit of surgery, and this works out of the box. tokenized_no_input_ids = { key: value for (key,value) in tokenized.items() if key != "input_ids" } model_result = model(**tokenized_no_input_ids, inputs_embeds=inputs_embeds) Finally, we can use torch's built-in autograd capabilities to get our input space embedding: inputs_embeds_grad = torch.autograd.grad( outputs=loss, inputs=inputs_embeds, create_graph=False, retain_graph=False, allow_unused=False ) Case Study: Horses and Dogs, Neighs and Barks To make things more concrete, let's start with two prompts: "The animal that says bark is a ____" "The animal that says neigh is a ____" The token distributions as predicted by ModernBERT-large are, respectively: Representing the left distribution as

Input Embedding Space Gradients
This is the first in a series of posts on the question:
"Can we extract meaningful information or interesting behavior from gradients on 'input embedding space'?"
I'm defining 'input embedding space' as the token embeddings prior to positional encoding.
The basic procedure for obtaining input space gradients is as follows:
- Transform tokens into input embeddings (but do not apply positional embedding).
- Run an ordinary forward pass on the input embeddings to obtain a predicted token distribution.
- Measure cross-entropy of the predicted distribution with a target token distribution.
- Use autograd to calculate gradients on the input embeddings with respect to cross entropy.
The result is a tensor of the same shape as the input embeddings that points in the direction of minimizing the difference between the predicted and target distribution.
Implementation
These experiments were performed with HuggingFace's transformers library and the ModernBERT-large model.
ModernBERT-large was chosen because it is relatively lightweight model with a strong visualization suite and a simplified attention mask (full cross-attention) that is easy to reason about. It would be interesting to see if the results in this post hold across other models.
I used HuggingFace's transformers because it allowed for fairly low level access to model internals - which was quite necessary as we will see.
Obtaining input embeddings prior to positional embeddings was a little tricky but no means impossible:
tokenizer = AutoTokenizer.from_pretrained(MODEL)
model = AutoModelForMaskedLM.from_pretrained(MODEL)
tokenized = tokenizer(sentences, return_tensors="pt", padding=True)
inputs_embeds = model.model.embeddings.tok_embeddings(tokenized['input_ids'])
Luckily for us, we can pass input_embeds directly into the model's forward pass with a little bit of surgery, and this works out of the box.
tokenized_no_input_ids = {
key: value
for (key,value) in tokenized.items()
if key != "input_ids"
}
model_result = model(**tokenized_no_input_ids,
inputs_embeds=inputs_embeds)
Finally, we can use torch's built-in autograd capabilities to get our input space embedding:
inputs_embeds_grad = torch.autograd.grad(
outputs=loss,
inputs=inputs_embeds,
create_graph=False,
retain_graph=False,
allow_unused=False
)
Case Study: Horses and Dogs, Neighs and Barks
To make things more concrete, let's start with two prompts:
- "The animal that says bark is a ____"
- "The animal that says neigh is a ____"
The token distributions as predicted by ModernBERT-large are, respectively:
Representing the left distribution as