











































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)































































































































![Ditching a Microsoft Job to Enter Startup Purgatory with Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)





























































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)



























































































































































-xl.jpg)



























![New iPad 11 (A16) On Sale for Just $277.78! [Lowest Price Ever]](https://www.iclarified.com/images/news/97273/97273/97273-640.jpg)

![Apple Foldable iPhone to Feature New Display Tech, 19% Thinner Panel [Rumor]](https://www.iclarified.com/images/news/97271/97271/97271-640.jpg)









































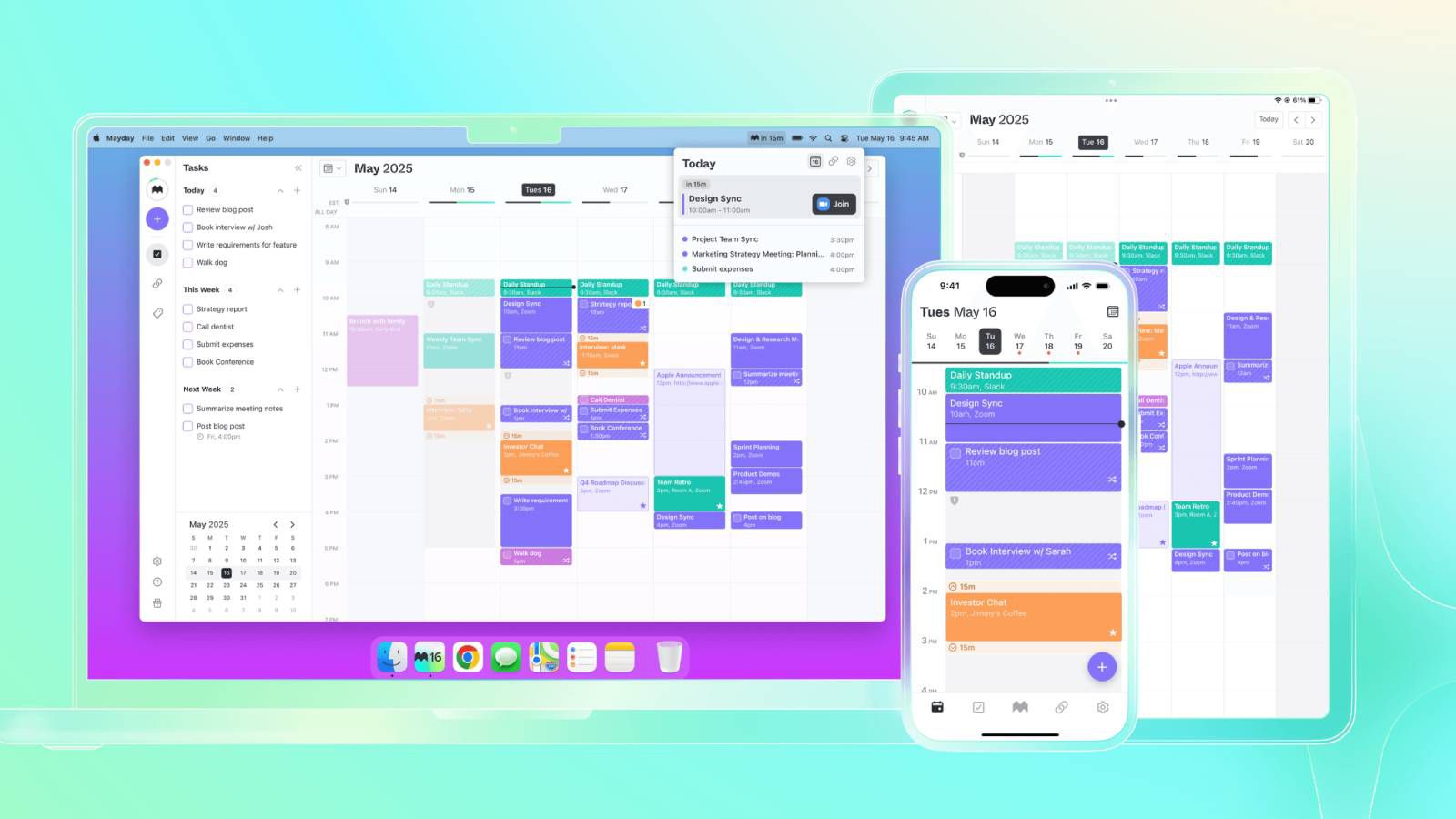



















































AWS Databases Unlocked: Choosing the Right Engine for Your Application in 2025
Ever felt that dizzying sensation looking at the AWS console, or trying to pick a database? "Should I use RDS? Or is DynamoDB better? What about Aurora? Or Redshift for this analytics thing?" If you've been there, you're in good company! Choosing the right database on AWS is a pivotal decision that can significantly impact your application's performance, scalability, cost-efficiency, and even your team's development velocity. With AWS offering a purpose-built database for virtually any workload, navigating this landscape can feel like finding a specific book in a colossal library. But fear not! This guide is your compass. Whether you're a cloud novice wondering where to start, or an experienced engineer looking to refine your database strategy, I'll demystify AWS's database services. I'll explore the "why" behind different database types, dive into key AWS offerings, and arm you with practical insights to make informed choices. Let's unlock the power of AWS databases together! Table of Contents Why AWS Databases are a Game-Changer Database 101: Simplifying the Core Concepts Deep Dive: Exploring Key AWS Database Services Relational Databases: RDS & Aurora NoSQL Powerhouses: DynamoDB, DocumentDB, Keyspaces Data Warehousing: Amazon Redshift In-Memory Stores: ElastiCache Specialized Databases: Neptune, Timestream, QLDB Real-World Scenario: Building a Modern E-commerce Platform Common Mistakes & Pitfalls (And How to Dodge Them) Pro Tips & Hidden Gems for AWS Database Mastery Conclusion: Your Journey to Database Excellence on AWS Level Up Your Skills & Connect 1. Why AWS Databases are a Game-Changer In today's data-driven world, the ability to store, manage, and access data efficiently is paramount. Traditional on-premises databases often come with heavy burdens: upfront hardware costs, complex licensing, manual patching, scaling limitations, and significant operational overhead. AWS revolutionized this by offering managed database services. This means AWS handles the undifferentiated heavy lifting – provisioning, patching, backup, recovery, scaling – allowing you to focus on application development and innovation. Key Advantages: Purpose-Built: AWS champions the idea of using the right tool for the job. Instead of a one-size-fits-all approach, they offer a diverse portfolio catering to specific needs (relational, key-value, document, graph, etc.). Scalability & Elasticity: Scale your database resources up or down based on demand, often automatically, paying only for what you use. High Availability & Durability: Features like Multi-AZ deployments and automated backups ensure your data is safe and accessible. Global Reach: Deploy databases closer to your users worldwide for lower latency. Innovation: AWS continually releases new features and services, keeping you at the cutting edge. For instance, the advancements in serverless databases and AI/ML integration into database services are truly transformative. Just look at the growth and adoption statistics – millions of active customers use AWS databases, and services like Amazon Aurora are among the fastest-growing in AWS history. This isn't just hype; it's a fundamental shift in how we manage data. What's the biggest database challenge you've faced that led you to explore cloud options? Share in the comments! 2. Database 101: Simplifying the Core Concepts Before diving into specific AWS services, let's quickly refresh some fundamental database concepts. Think of databases like specialized storage containers, each designed for different types of "items" and ways to access them. Relational Databases (SQL): Analogy: Like a collection of perfectly organized spreadsheets (tables) where data is structured in rows and columns. Relationships between tables are clearly defined (e.g., a Customers table linked to an Orders table). Use when: You need strong consistency (ACID properties), structured data, and complex queries involving joins across multiple tables. Examples: Storing customer information, product catalogs, financial transactions. NoSQL Databases (Non-Relational): Analogy: A flexible filing system. It's not one type, but a category. Key-Value Stores: Like a giant dictionary where you look up a value using a unique key. Super fast for simple lookups. (e.g., user session data). Document Stores: Store data in flexible, JSON-like documents. Great for evolving schemas and semi-structured data (e.g., product details with varying attributes). Graph Databases: Focus on relationships between data points. Think social networks, recommendation engines. Column-Family Stores: Optimized for high-volume writes and reads over massive datasets, often used in Big Data. Use when: You need high scalability, flexibility in data structure, and often prioritize availability and partition tolerance over strict consistency (BASE properties). Data
Ever felt that dizzying sensation looking at the AWS console, or trying to pick a database? "Should I use RDS? Or is DynamoDB better? What about Aurora? Or Redshift for this analytics thing?" If you've been there, you're in good company!
Choosing the right database on AWS is a pivotal decision that can significantly impact your application's performance, scalability, cost-efficiency, and even your team's development velocity. With AWS offering a purpose-built database for virtually any workload, navigating this landscape can feel like finding a specific book in a colossal library.
But fear not! This guide is your compass. Whether you're a cloud novice wondering where to start, or an experienced engineer looking to refine your database strategy, I'll demystify AWS's database services. I'll explore the "why" behind different database types, dive into key AWS offerings, and arm you with practical insights to make informed choices. Let's unlock the power of AWS databases together!
Table of Contents
- Why AWS Databases are a Game-Changer
- Database 101: Simplifying the Core Concepts
- Deep Dive: Exploring Key AWS Database Services
- Relational Databases: RDS & Aurora
- NoSQL Powerhouses: DynamoDB, DocumentDB, Keyspaces
- Data Warehousing: Amazon Redshift
- In-Memory Stores: ElastiCache
- Specialized Databases: Neptune, Timestream, QLDB
- Real-World Scenario: Building a Modern E-commerce Platform
- Common Mistakes & Pitfalls (And How to Dodge Them)
- Pro Tips & Hidden Gems for AWS Database Mastery
- Conclusion: Your Journey to Database Excellence on AWS
- Level Up Your Skills & Connect
1. Why AWS Databases are a Game-Changer
In today's data-driven world, the ability to store, manage, and access data efficiently is paramount. Traditional on-premises databases often come with heavy burdens: upfront hardware costs, complex licensing, manual patching, scaling limitations, and significant operational overhead.
AWS revolutionized this by offering managed database services. This means AWS handles the undifferentiated heavy lifting – provisioning, patching, backup, recovery, scaling – allowing you to focus on application development and innovation.
Key Advantages:
- Purpose-Built: AWS champions the idea of using the right tool for the job. Instead of a one-size-fits-all approach, they offer a diverse portfolio catering to specific needs (relational, key-value, document, graph, etc.).
- Scalability & Elasticity: Scale your database resources up or down based on demand, often automatically, paying only for what you use.
- High Availability & Durability: Features like Multi-AZ deployments and automated backups ensure your data is safe and accessible.
- Global Reach: Deploy databases closer to your users worldwide for lower latency.
- Innovation: AWS continually releases new features and services, keeping you at the cutting edge. For instance, the advancements in serverless databases and AI/ML integration into database services are truly transformative.
Just look at the growth and adoption statistics – millions of active customers use AWS databases, and services like Amazon Aurora are among the fastest-growing in AWS history. This isn't just hype; it's a fundamental shift in how we manage data.
What's the biggest database challenge you've faced that led you to explore cloud options? Share in the comments!
2. Database 101: Simplifying the Core Concepts
Before diving into specific AWS services, let's quickly refresh some fundamental database concepts. Think of databases like specialized storage containers, each designed for different types of "items" and ways to access them.
-
Relational Databases (SQL):
- Analogy: Like a collection of perfectly organized spreadsheets (tables) where data is structured in rows and columns. Relationships between tables are clearly defined (e.g., a
Customerstable linked to anOrderstable). - Use when: You need strong consistency (ACID properties), structured data, and complex queries involving joins across multiple tables.
- Examples: Storing customer information, product catalogs, financial transactions.
- Analogy: Like a collection of perfectly organized spreadsheets (tables) where data is structured in rows and columns. Relationships between tables are clearly defined (e.g., a
-
NoSQL Databases (Non-Relational):
- Analogy: A flexible filing system. It's not one type, but a category.
- Key-Value Stores: Like a giant dictionary where you look up a value using a unique key. Super fast for simple lookups. (e.g., user session data).
- Document Stores: Store data in flexible, JSON-like documents. Great for evolving schemas and semi-structured data (e.g., product details with varying attributes).
- Graph Databases: Focus on relationships between data points. Think social networks, recommendation engines.
- Column-Family Stores: Optimized for high-volume writes and reads over massive datasets, often used in Big Data.
- Use when: You need high scalability, flexibility in data structure, and often prioritize availability and partition tolerance over strict consistency (BASE properties).
- Analogy: A flexible filing system. It's not one type, but a category.
-
Data Warehouses:
- Analogy: A massive, specialized library optimized for historical data analysis and business intelligence. Stores huge volumes of data from various sources.
- Use when: You need to run complex analytical queries on large datasets to find trends, generate reports, and gain insights.
-
In-Memory Databases/Caches:
- Analogy: Keeping frequently accessed items on your desk instead of a faraway filing cabinet for lightning-fast retrieval.
- Use when: You need sub-millisecond latency for frequently accessed data, like caching query results or user sessions.
Understanding these fundamental differences is key to choosing the right AWS database service.
3. Deep Dive: Exploring Key AWS Database Services
AWS offers a rich tapestry of database services. Let's explore the most popular ones:
Relational Databases: RDS & Aurora
-
Amazon RDS (Relational Database Service):
- What it is: A managed service that makes it easy to set up, operate, and scale relational databases in the cloud. Supports popular engines:
- MySQL
- PostgreSQL
- MariaDB
- Microsoft SQL Server
- Oracle
- Use Cases: Web and mobile applications, e-commerce platforms, enterprise applications requiring transactional consistency.
- Pricing: Based on instance hours, storage, I/O, and data transfer. Offers On-Demand, Reserved Instances, and Spot Instances (for SQL Server).
- Key Features: Automated patching, backups, Multi-AZ for high availability, Read Replicas for read scaling, Performance Insights.
- CLI Example (creating a small PostgreSQL instance):
aws rds create-db-instance \ --db-instance-identifier my-pg-instance \ --db-instance-class db.t3.micro \ --engine postgres \ --allocated-storage 20 \ --master-username myadmin \ --master-user-password ComplexPassword123 \ --backup-retention-period 7 \ --multi-az | # For production, consider true # Ensure you have proper VPC, subnet group, and security group configurations(Note: For actual use, ensure you set a strong password and manage it securely, e.g., via AWS Secrets Manager.)
- What it is: A managed service that makes it easy to set up, operate, and scale relational databases in the cloud. Supports popular engines:
-
Amazon Aurora:
- What it is: A MySQL and PostgreSQL-compatible relational database built for the cloud. Offers superior performance, scalability, and availability compared to traditional engines on RDS.
- Use Cases: High-throughput applications, mission-critical enterprise workloads, SaaS applications.
- Pricing: Based on instance hours, storage consumed (not provisioned), and I/O operations. Aurora Serverless offers pay-per-use capacity.
- Key Features: Up to 5x throughput of standard MySQL and 3x of standard PostgreSQL, auto-scaling storage up to 128TB, fault-tolerant and self-healing storage, Global Database, Aurora Serverless.

NoSQL Powerhouses: DynamoDB, DocumentDB, Keyspaces
-
Amazon DynamoDB:
- What it is: A fully managed, serverless, key-value and document NoSQL database designed for single-digit millisecond performance at any scale.
- Use Cases: Mobile apps, gaming, AdTech, IoT, session stores, leaderboards, applications requiring massive scale and low latency.
- Pricing: Based on provisioned or on-demand read/write capacity units (RCUs/WCUs) and storage.
- Key Features: Virtually unlimited throughput and storage, built-in security, backup and restore, DynamoDB Accelerator (DAX) for in-memory caching, Global Tables for multi-region replication.
- Boto3 (Python) Snippet (putting an item):
import boto3 dynamodb = boto3.resource('dynamodb', region_name='us-east-1') table = dynamodb.Table('MyUsersTable') response = table.put_item( Item={ 'username': 'johndoe', 'first_name': 'John', 'last_name': 'Doe', 'age': 30 } ) print("PutItem succeeded:", response) -
Amazon DocumentDB (with MongoDB compatibility):
- What it is: A fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads.
- Use Cases: Content management, catalogs, user profiles, applications migrating from MongoDB.
- Pricing: Based on instance hours, storage, and I/O.
-
Amazon Keyspaces (for Apache Cassandra):
- What it is: A scalable, highly available, and managed Apache Cassandra-compatible database service. Serverless, so you pay only for what you use.
- Use Cases: Applications requiring Cassandra's wide-column store model with low latency, built using Cassandra APIs and drivers.
Data Warehousing: Amazon Redshift
- What it is: A fast, fully managed, petabyte-scale data warehouse service.
- Use Cases: Business intelligence, analytics, reporting, data mining on large datasets.
- Pricing: Based on node type and number of nodes (provisioned cluster) or Redshift Serverless compute and storage used.
- Key Features: Massively Parallel Processing (MPP) architecture, columnar storage, data compression, Redshift Spectrum for querying data in S3, Concurrency Scaling.
In-Memory Stores: ElastiCache
- Amazon ElastiCache:
- What it is: A web service that makes it easy to deploy, operate, and scale an in-memory cache in the cloud. Supports two open-source engines:
- Memcached: Simpler, good for scaling out.
- Redis: Richer feature set (data structures, pub/sub, persistence options).
- Use Cases: Caching database query results, session management, real-time leaderboards, reducing latency for read-heavy applications.
- Pricing: Based on node type and hours.
- What it is: A web service that makes it easy to deploy, operate, and scale an in-memory cache in the cloud. Supports two open-source engines:
Specialized Databases: Neptune, Timestream, QLDB
- Amazon Neptune: A fast, reliable, fully managed graph database service. Ideal for social networking, recommendation engines, fraud detection.
- Amazon Timestream: A fast, scalable, and serverless time series database for IoT, operational applications, and DevOps data.
- Amazon Quantum Ledger Database (QLDB): A fully managed ledger database that provides a transparent, immutable, and cryptographically verifiable transaction log. Ideal for systems of record where data integrity and verifiability are crucial.
Which of these AWS database services are you most curious about or already using? Let me know!
4. Real-World Scenario: Building a Modern E-commerce Platform
Let's imagine we're building a new e-commerce platform, "AwesomeCart." How would we leverage AWS's purpose-built databases?
-
Product Catalog & Orders (Structured, Transactional Data):
- Choice: Amazon Aurora (PostgreSQL compatible).
- Why: We need ACID compliance for orders, relational integrity for product data (categories, SKUs, inventory), and the ability to run complex queries for product listings and filtering. Aurora provides performance and scalability.
- Setup Notes: Multi-AZ for high availability. Read Replicas to offload product browsing queries.
-
User Sessions & Shopping Carts (Volatile, High-Speed Access):
- Choice: Amazon ElastiCache for Redis or Amazon DynamoDB.
- Why:
- ElastiCache (Redis): Sub-millisecond latency for storing and retrieving shopping cart data and user session tokens. Perfect for frequently changing, temporary data.
- DynamoDB: Also excellent for session state and carts due to its scalability and key-value access patterns. Could persist carts longer if needed.
- Impact: Fast page loads, responsive user experience.
-
User Profiles & Preferences (Flexible Schema):
- Choice: Amazon DynamoDB.
- Why: User profiles can have varying attributes (e.g., some users have loyalty status, others have wish lists). DynamoDB's flexible schema handles this well. Fast lookups by
userID.
-
Product Recommendations (Relationship-Based):
- Choice: Amazon Neptune.
- Why: To model relationships like "users who bought X also bought Y" or "products frequently viewed together." Graph queries can power sophisticated recommendations.
- Alternative: Machine learning models outputting recommendations stored in DynamoDB for quick retrieval.
-
Sales Analytics & Reporting (Business Intelligence):
- Choice: Amazon Redshift.
- Why: To analyze terabytes of historical sales data, customer behavior, inventory trends, and generate reports for business decisions.
- Data Flow: Order data from Aurora and clickstream data (potentially via Kinesis) would be ETL'd into Redshift.
Security & Cost Considerations:
- Security:
- Use IAM roles for EC2/Lambda to access databases.
- Place databases in private subnets within a VPC.
- Utilize Security Groups to control network traffic.
- Enable encryption at rest and in transit.
- Cost:
- Choose appropriate instance sizes for RDS/Aurora/Redshift.
- Consider Reserved Instances for predictable workloads.
- Leverage Aurora Serverless or DynamoDB On-Demand for spiky or unpredictable traffic to optimize costs.
- Monitor with AWS Cost Explorer and set up billing alarms.
This polyglot persistence approach (using multiple database types) allows AwesomeCart to optimize each part of its application for performance, scale, and features.
5. Common Mistakes & Pitfalls (And How to Dodge Them)
Navigating the AWS database landscape is powerful, but it's easy to stumble. Here are common pitfalls:
-
The "One Database Fits All" Trap:
- Mistake: Trying to force a relational database (like RDS MySQL) to handle workloads better suited for NoSQL (e.g., massive-scale key-value lookups) or vice-versa.
- Avoidance: Understand your data model, access patterns, and scalability needs before choosing. Embrace purpose-built databases.
-
Ignoring Scalability & Performance Needs from Day One:
- Mistake: Starting with the smallest instance and hoping for the best, or overprovisioning wildly "just in case." For DynamoDB, poor partition key design can lead to hot partitions.
- Avoidance: Roughly estimate your current and future load. For RDS/Aurora, understand read vs. write patterns to plan for Read Replicas. For DynamoDB, design your keys thoughtfully for even data distribution. Use AWS tools like Performance Insights (RDS) and CloudWatch metrics.
-
Neglecting Backups and Disaster Recovery:
- Mistake: Relying solely on default automated backups without understanding retention periods or testing recovery processes. Not considering Multi-AZ for critical production databases.
- Avoidance: Configure appropriate backup retention. For critical systems, use Multi-AZ (RDS/Aurora) or Global Tables (DynamoDB). Regularly test your restore procedures!
-
Lax Security Practices:
- Mistake: Using root credentials, overly permissive IAM policies, public accessibility for databases, or not encrypting sensitive data.
- Avoidance: Follow the principle of least privilege. Use IAM roles. Keep databases in private subnets. Encrypt data at rest and in transit. Regularly review security group rules.
-
Misunderstanding Consistency Models:
- Mistake: Expecting strong consistency from eventually consistent systems (like DynamoDB by default) without designing the application to handle it, or vice-versa.
- Avoidance: Understand the consistency guarantees of your chosen database (e.g., ACID for RDS/Aurora, eventual vs. strong consistency options for DynamoDB).

What's a database mistake you've made or seen that taught you a valuable lesson? Sharing helps us all learn!
6. Pro Tips & Hidden Gems for AWS Database Mastery
Ready to level up your AWS database game? Here are some tips:
- RDS Performance Insights: Don't just guess where your RDS/Aurora bottlenecks are. Performance Insights provides an intuitive dashboard showing database load and wait events, helping you pinpoint problematic queries or resource contention.
- RDS Proxy: For applications with many short-lived connections (e.g., Lambda functions), RDS Proxy provides connection pooling, improving performance and resilience by reducing the load of opening/closing connections on your database.
- DynamoDB Accelerator (DAX): If you have read-heavy DynamoDB workloads and need microsecond latency, DAX is an in-memory cache that sits in front of DynamoDB. It's transparent to your application.
- DynamoDB Global Tables: For globally distributed applications, Global Tables provide fully managed, multi-region, multi-active replication. Write to any region, and data replicates automatically.
- Aurora Serverless v2: It scales instantly and granularly to support even the most demanding and unpredictable workloads. Great for spiky traffic patterns and can significantly reduce costs if your load varies a lot.
- Redshift Concurrency Scaling: Automatically adds transient cluster capacity to handle bursts of read queries, ensuring consistently fast performance for your BI users.
- Leverage AWS SDKs Wisely: SDKs often have built-in retry mechanisms and best practices. Understand how they handle connections and errors for your chosen database.
- Tagging: Tag your database resources meticulously. It's crucial for cost allocation, automation, and organization.
- CloudWatch Alarms: Don't wait for users to complain. Set up CloudWatch Alarms for key metrics like CPU utilization, free storage space, read/write latency, and error rates for your databases.
- Infrastructure as Code (IaC): Use tools like AWS CloudFormation or Terraform to define and manage your database infrastructure. This ensures repeatability, version control, and easier updates.
7. Conclusion: Your Journey to Database Excellence on AWS
The AWS database ecosystem is vast and incredibly powerful. The key takeaway is this: AWS empowers you to choose the right, purpose-built database for each specific job. Moving away from a monolithic, one-size-fits-all approach can unlock significant gains in performance, scalability, resilience, and cost-efficiency.
We've journeyed from understanding fundamental database types to exploring the capabilities of services like RDS, Aurora, DynamoDB, Redshift, and more. We've seen how to combine them in a real-world scenario and learned to avoid common pitfalls.

Your learning journey doesn't stop here!
- Dive Deeper: Explore the official AWS Databases documentation.
- Hands-On: Try AWS Free Tier offerings for various database services.
- Certify Your Skills: Consider the AWS Certified Database - Specialty certification to validate your expertise.
The world of data is constantly evolving, and AWS databases are at the forefront of that evolution. Embrace the learning, experiment, and build amazing applications!
8. Level Up Your Skills & Connect
I hope this deep dive into AWS databases has been valuable for you! Helping developers and cloud professionals navigate the complexities of AWS is my passion.



