










































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)















































































































![How to Refactor Monolithic Repositories for Embedded “Bare Metal” Applications and Shared Libraries with Inter-Dependencies? [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)














![From Accountant to Data Engineer with Alyson La [Podcast #168]](https://cdn.hashnode.com/res/hashnode/image/upload/v1744420903260/fae4b593-d653-41eb-b70b-031591aa2f35.png?#)









































































































.png?#)































































































































![What Google Messages features are rolling out [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2023/12/google-messages-name-cover.png?resize=1200%2C628&quality=82&strip=all&ssl=1)











![iPadOS 19 Will Be More Like macOS [Gurman]](https://www.iclarified.com/images/news/97001/97001/97001-640.jpg)
![Apple TV+ Summer Preview 2025 [Video]](https://www.iclarified.com/images/news/96999/96999/96999-640.jpg)
![Apple Watch SE 2 On Sale for Just $169.97 [Deal]](https://www.iclarified.com/images/news/96996/96996/96996-640.jpg)



























































































































AI ตรวจจับคำหยาบในข้อความภาษาไทยด้วย Machine Learning
ในยุคที่โลกออนไลน์เป็นศูนย์กลางของการสื่อสาร การแสดงความคิดเห็นในแพลตฟอร์มต่างๆ เช่น Facebook, Twitter, YouTube หรือแม้แต่เว็บไซต์ข่าวสาร กลายเป็นเรื่องธรรมดา แต่สิ่งที่ตามมาคือ "ข้อความไม่เหมาะสม" หรือ "คำหยาบคาย" ที่อาจสร้างความไม่สบายใจให้กับผู้อื่น การมีระบบอัตโนมัติที่ช่วยตรวจจับและกรองคำเหล่านี้จึงเป็นเรื่องจำเป็น บทความนี้จะพาคุณไปรู้จักกับวิธีการสร้าง AI ง่ายๆ ที่สามารถตรวจจับคำหยาบในข้อความภาษาไทย โดยใช้เทคนิค Natural Language Processing (NLP) ร่วมกับ Machine Learning แบบ Supervised Learning โดยเราจะใช้ภาษา Python และรันได้ง่ายๆ บน Google Colab พร้อมโค้ดตัวอย่างที่สามารถนำไปประยุกต์ใช้ได้ทันที AI ตัวนี้ทำงานอย่างไร? AI ที่เราจะสร้างอยู่ในกลุ่มของ Supervised Learning - Text Classification โดยเป้าหมายคือการจำแนกข้อความออกเป็น 2 ประเภท: สุภาพ (0) เช่น “สวัสดีครับ”, “ขอบคุณมากๆ” ไม่สุภาพ (1) เช่น “ไอสัส”, “โง่ชิบหาย” กระบวนการโดยรวมของการสร้าง AI มีดังนี้: 1.เตรียม Dataset ที่มีตัวอย่างข้อความ พร้อม label ว่าเป็นคำสุภาพหรือไม่ 2.ทำการ ตัดคำและลบคำฟุ่มเฟือย ด้วยเทคนิค NLP (Natural Language Processing) 3.แปลงข้อความเป็นเวกเตอร์ตัวเลขด้วย TF-IDF Vectorization 4.สร้างโมเดล Machine Learning ด้วย Logistic Regression 5.ทดสอบผลลัพธ์และลองใช้งานจริงด้วยข้อความใหม่ ขั้นตอนที่ 1: เริ่มต้นจากการเตรียมข้อมูล สำหรับบทความนี้ เราจะสร้าง Dataset แบบง่ายๆ ด้วยตนเองก่อน เพื่อให้เข้าใจภาพรวม โดยแต่ละบรรทัดคือข้อความภาษาไทย พร้อม label ว่าเป็นคำสุภาพหรือคำหยาบ ตัวอย่างของ Dataset แบบง่ายๆ สามารถ copy code และนำไปเพิ่มเติมข้อมูลได้ตามใจชอบ ตัวอย่างผลที่ได้จาก code หมายเหตุ: ในงานจริงควรใช้ Dataset ที่มีขนาดใหญ่กว่านี้ และหลากหลายคำมากขึ้น เพื่อให้โมเดลแม่นยำยิ่งขึ้น ขั้นตอนที่ 2: การเตรียมข้อความด้วย NLP (Tokenization & Stopword Removal) ภาษาธรรมชาติอย่างภาษาไทยจะต้องผ่านขั้นตอน "ตัดคำ" (เพราะไม่มีการเว้นวรรคเหมือนภาษาอังกฤษ) และลบคำฟุ่มเฟือย เช่น “ที่”, “คือ”, “แล้ว” ที่ไม่มีผลกับความหมายของข้อความ ตัวอย่างเช่น: “ขอความกรุณาด้วยครับ” → [ขอ, ความกรุณา] “ไอสัส” → [ไอ, สัส] ผลลัพธ์ที่ได้ ขั้นตอนที่ 3: แปลงข้อความเป็นเวกเตอร์ตัวเลข (TF-IDF Vectorization) เพื่อให้โมเดลสามารถเรียนรู้จากข้อความ เราต้องแปลงข้อความเป็นตัวเลขก่อน ซึ่ง TF-IDF จะช่วยแปลงข้อความแต่ละประโยคเป็นเวกเตอร์ที่มีน้ำหนักของแต่ละคำ X จะกลายเป็น matrix ของข้อความที่มีค่าน้ำหนัก TF-IDF ของแต่ละคำ ขั้นตอนที่ 4: สร้างและเทรนโมเดลด้วย Logistic Regression เราใช้โมเดล Logistic Regression ซึ่งเหมาะกับงานจำแนกประเภทแบบ binary (เช่น สุภาพ / ไม่สุภาพ) ผลลัพธ์จะได้ precision, recall และ accuracy ของโมเดล ซึ่งแสดงถึงความสามารถของโมเดลในการจำแนกข้อความ ตัวอย่างการใช้งานจริง เราจะลองเขียนฟังก์ชันให้ผู้ใช้พิมพ์ข้อความแล้วตรวจว่าเป็นคำหยาบหรือไม่ ผลลัพธ์ สรุป จากบทความนี้เราได้เรียนรู้วิธีการสร้างโมเดล AI สำหรับตรวจจับคำหยาบในข้อความภาษาไทย โดยใช้เทคนิค NLP และ Logistic Regression ซึ่งเหมาะกับการใช้งานเบื้องต้น หากต้องการความแม่นยำสูงขึ้น อาจพิจารณาใช้เทคนิคขั้นสูง เช่น: Word Embedding (เช่น fastText, Word2Vec) Deep Learning (เช่น LSTM, BERT) เพิ่ม Dataset ที่หลากหลายยิ่งขึ้น ในอนาคตสามารถพัฒนาให้ดียิ่งขึ้นด้วยการใช้ Deep Learning, LSTM หรือ Transformer เพื่อความแม่นยำที่สูงขึ้นได้ แหล่งอ้างอิง (References) PyThaiNLP Documentation https://pythainlp.github.io/docs/ scikit-learn: Machine Learning in Python https://scikit-learn.org/stable/ TF-IDF Explained (จาก MonkeyLearn) https://monkeylearn.com/blog/what-is-tf-idf/ Thai Text Classification Example by PyThaiNLP https://github.com/PyThaiNLP/tutorials Kaggle: Natural Language Processing (Text Classification Tutorial) https://www.kaggle.com/learn/natural-language-processing

ในยุคที่โลกออนไลน์เป็นศูนย์กลางของการสื่อสาร การแสดงความคิดเห็นในแพลตฟอร์มต่างๆ เช่น Facebook, Twitter, YouTube หรือแม้แต่เว็บไซต์ข่าวสาร กลายเป็นเรื่องธรรมดา แต่สิ่งที่ตามมาคือ "ข้อความไม่เหมาะสม" หรือ "คำหยาบคาย" ที่อาจสร้างความไม่สบายใจให้กับผู้อื่น การมีระบบอัตโนมัติที่ช่วยตรวจจับและกรองคำเหล่านี้จึงเป็นเรื่องจำเป็น
บทความนี้จะพาคุณไปรู้จักกับวิธีการสร้าง AI ง่ายๆ ที่สามารถตรวจจับคำหยาบในข้อความภาษาไทย โดยใช้เทคนิค Natural Language Processing (NLP) ร่วมกับ Machine Learning แบบ Supervised Learning โดยเราจะใช้ภาษา Python และรันได้ง่ายๆ บน Google Colab พร้อมโค้ดตัวอย่างที่สามารถนำไปประยุกต์ใช้ได้ทันที
AI ตัวนี้ทำงานอย่างไร?
AI ที่เราจะสร้างอยู่ในกลุ่มของ Supervised Learning - Text Classification โดยเป้าหมายคือการจำแนกข้อความออกเป็น 2 ประเภท:
สุภาพ (0) เช่น “สวัสดีครับ”, “ขอบคุณมากๆ”
ไม่สุภาพ (1) เช่น “ไอสัส”, “โง่ชิบหาย”
กระบวนการโดยรวมของการสร้าง AI มีดังนี้:
1.เตรียม Dataset ที่มีตัวอย่างข้อความ พร้อม label ว่าเป็นคำสุภาพหรือไม่
2.ทำการ ตัดคำและลบคำฟุ่มเฟือย ด้วยเทคนิค NLP (Natural Language Processing)
3.แปลงข้อความเป็นเวกเตอร์ตัวเลขด้วย TF-IDF Vectorization
4.สร้างโมเดล Machine Learning ด้วย Logistic Regression
5.ทดสอบผลลัพธ์และลองใช้งานจริงด้วยข้อความใหม่
ขั้นตอนที่ 1: เริ่มต้นจากการเตรียมข้อมูล
สำหรับบทความนี้ เราจะสร้าง Dataset แบบง่ายๆ ด้วยตนเองก่อน เพื่อให้เข้าใจภาพรวม โดยแต่ละบรรทัดคือข้อความภาษาไทย พร้อม label ว่าเป็นคำสุภาพหรือคำหยาบ
ตัวอย่างของ Dataset แบบง่ายๆ สามารถ copy code และนำไปเพิ่มเติมข้อมูลได้ตามใจชอบ
ตัวอย่างผลที่ได้จาก code
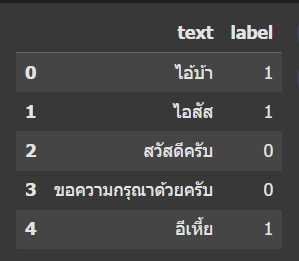
หมายเหตุ: ในงานจริงควรใช้ Dataset ที่มีขนาดใหญ่กว่านี้ และหลากหลายคำมากขึ้น เพื่อให้โมเดลแม่นยำยิ่งขึ้น
ขั้นตอนที่ 2: การเตรียมข้อความด้วย NLP (Tokenization & Stopword Removal)
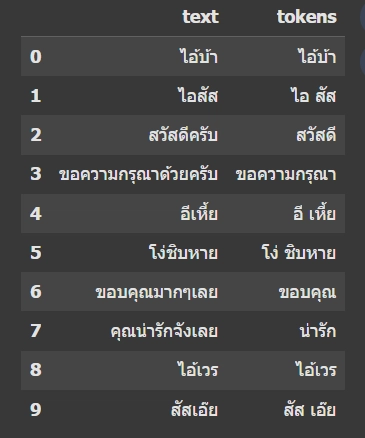
ภาษาธรรมชาติอย่างภาษาไทยจะต้องผ่านขั้นตอน "ตัดคำ" (เพราะไม่มีการเว้นวรรคเหมือนภาษาอังกฤษ) และลบคำฟุ่มเฟือย เช่น “ที่”, “คือ”, “แล้ว” ที่ไม่มีผลกับความหมายของข้อความ

ตัวอย่างเช่น:
“ขอความกรุณาด้วยครับ” → [ขอ, ความกรุณา]
“ไอสัส” → [ไอ, สัส]
ผลลัพธ์ที่ได้
ขั้นตอนที่ 3: แปลงข้อความเป็นเวกเตอร์ตัวเลข (TF-IDF Vectorization)
เพื่อให้โมเดลสามารถเรียนรู้จากข้อความ เราต้องแปลงข้อความเป็นตัวเลขก่อน ซึ่ง TF-IDF จะช่วยแปลงข้อความแต่ละประโยคเป็นเวกเตอร์ที่มีน้ำหนักของแต่ละคำ
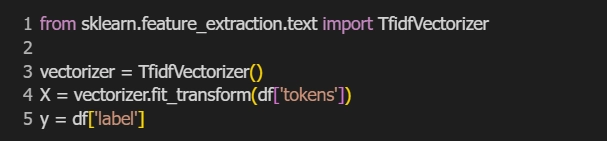
X จะกลายเป็น matrix ของข้อความที่มีค่าน้ำหนัก TF-IDF ของแต่ละคำ
ขั้นตอนที่ 4: สร้างและเทรนโมเดลด้วย Logistic Regression
เราใช้โมเดล Logistic Regression ซึ่งเหมาะกับงานจำแนกประเภทแบบ binary (เช่น สุภาพ / ไม่สุภาพ)

ผลลัพธ์จะได้ precision, recall และ accuracy ของโมเดล ซึ่งแสดงถึงความสามารถของโมเดลในการจำแนกข้อความ
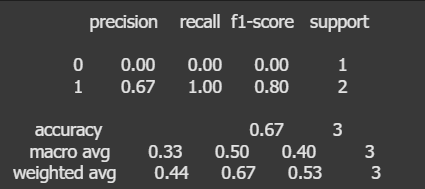
ตัวอย่างการใช้งานจริง
เราจะลองเขียนฟังก์ชันให้ผู้ใช้พิมพ์ข้อความแล้วตรวจว่าเป็นคำหยาบหรือไม่

ผลลัพธ์

สรุป
จากบทความนี้เราได้เรียนรู้วิธีการสร้างโมเดล AI สำหรับตรวจจับคำหยาบในข้อความภาษาไทย โดยใช้เทคนิค NLP และ Logistic Regression ซึ่งเหมาะกับการใช้งานเบื้องต้น
หากต้องการความแม่นยำสูงขึ้น อาจพิจารณาใช้เทคนิคขั้นสูง เช่น:
- Word Embedding (เช่น fastText, Word2Vec)
- Deep Learning (เช่น LSTM, BERT)
- เพิ่ม Dataset ที่หลากหลายยิ่งขึ้น ในอนาคตสามารถพัฒนาให้ดียิ่งขึ้นด้วยการใช้ Deep Learning, LSTM หรือ Transformer เพื่อความแม่นยำที่สูงขึ้นได้
แหล่งอ้างอิง (References)
PyThaiNLP Documentation
https://pythainlp.github.io/docs/scikit-learn: Machine Learning in Python
https://scikit-learn.org/stable/TF-IDF Explained (จาก MonkeyLearn)
https://monkeylearn.com/blog/what-is-tf-idf/Thai Text Classification Example by PyThaiNLP
https://github.com/PyThaiNLP/tutorialsKaggle: Natural Language Processing (Text Classification Tutorial)
https://www.kaggle.com/learn/natural-language-processing



