


















































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)



























































































































![From Accountant to Data Engineer with Alyson La [Podcast #168]](https://cdn.hashnode.com/res/hashnode/image/upload/v1744420903260/fae4b593-d653-41eb-b70b-031591aa2f35.png?#)










































































































.png?#)































































































































![What Google Messages features are rolling out [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2023/12/google-messages-name-cover.png?resize=1200%2C628&quality=82&strip=all&ssl=1)











![iPadOS 19 Will Be More Like macOS [Gurman]](https://www.iclarified.com/images/news/97001/97001/97001-640.jpg)
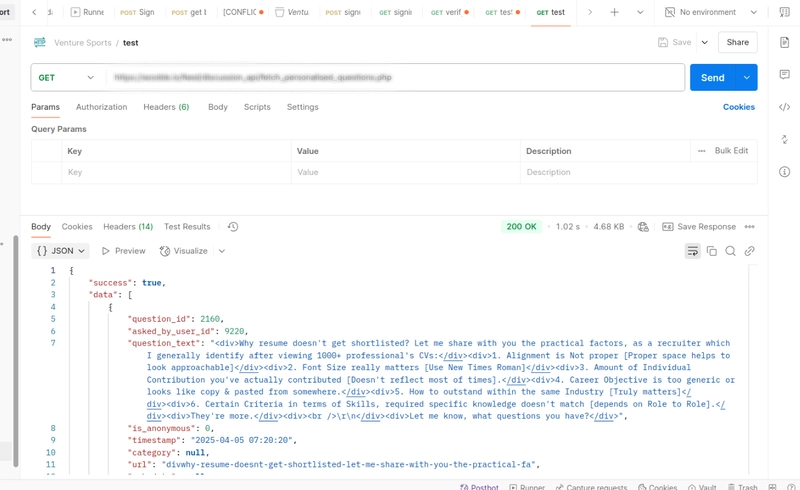
![Apple TV+ Summer Preview 2025 [Video]](https://www.iclarified.com/images/news/96999/96999/96999-640.jpg)
![Apple Watch SE 2 On Sale for Just $169.97 [Deal]](https://www.iclarified.com/images/news/96996/96996/96996-640.jpg)


























































































































A Practical Guide to Data Architecture: Real-World Use Cases from Lakes to Warehouses
In today’s data-driven world, choosing the right architecture is crucial. This article compares Data Warehouses, Data Lakes, Data Lakehouse’s, and Data Marts through real-world business use cases—exploring how data flows from raw sources to decision-making dashboards. Each serves a unique purpose, and choosing the right one depends on your team's goals, tools, and data maturity. Data Lakes Data lake is a large repository that stores huge amounts of raw data in its original format until you need to use it. There are no fixed limitations on data lake storage. That means that considerations — like format, file type, and specific purpose — do not apply. It is used when organizations need flexibility is required in data processing and analysis. Data lakes can store any type of data from multiple sources, whether that data is structured, semi-structured, or unstructured. As a result, data lakes are highly scalable, which makes them ideal for larger organizations that collect a vast amount of data. Let’s better understand Data Lakes end to end with a real-world example: A real-world example would be a tech company that leverages Data Lakes for storing large-scale logs and unstructured user interaction data for product analytics. What might the data source for this example look like? Data might come through various sources such as web application logs, mobile application events, social media data. How does extraction, transformation and loading (ETL) the data from the source to the Data Lake look like? The raw data gets continuously streamed (real time processing) into Data Lakes (usually cloud storage). A thing to note is that there is no upfront transformation as it uses schema-on-read approach Data Lake Tools: Amazon S3, Azure Data Lake, or Goolgle Cloud Storage Who might be the End Users and how would they use it? Data Scientist using data for exploratory analysis purposes and applying machine learning using Spark or Python notebooks for identifying user behavior patterns, improving product features through ML models. Data Warehouse Data in Data Warehouse is collected from a variety of sources, but this typically takes the form of processed data from internal and external systems in an organization. This data consists of specific insights such as product, customer, or employee information. It is best used for reporting and data analysis, storing historical data. Let’s better understand Data Warehouse end to end with a real-world example: One of the prime examples where Data Warehouses are used is in very large retail chains where they would like to store and analyze customer purchases and their sales data. What might the data source for this example look like? It could be their Point of Sales (POS) Systems, online transactions, CRM data How does this data get extracted, transformed and loaded (ETL) from the source to the Data Warehouse? • As a first step, data gets extracted in batches at night from operational databases (quick detour: they are also called Online Transaction Processing – OLTP systems and are used to run day-to-day business operations. These are the systems where data is first created, updated, or deleted in real time during routine transactions). • The second step in this case would be to transform the data where cleaning, deduplication and normalization takes place. • The final step would be loading the data into the data warehouse (schema-on-write). Tools for Data Warehouse: Snowflake, Amazon Redshift or Google BigQuery. End Users of Data Warehouse? As one of the usages, it could be used by Analysts to create PowerBI or Tableau dashboards for creating daily sales reports, profitability analysis or inventory forecast. Data Lakehouse Data Lakehouse is a hybrid approach that combines the best of Data Warehouse and Data Lake. It combines the management and performance capabilities of data warehouses with the scalability of data lakes. It supports semi-structured, structured, and unstructured data. Let’s better understand Data Lakehouse end to end with a real-world example: Taking an example of financial services that would use Data Lakehouse for building real-time fraud detection and regulatory reporting. What might the data source for this example look like? Real-time transactional data through core banking systems, Customer Profiles with KYC info from CRM systems, fraud alert signals through Fraud Detection APIs and through external data feeds from credit bureaus, etc How does hybrid ETL/ELT data load from the sources to the Data Lakehouse look like? Loading the data into Data Lakehouse maybe either take an ETL or ELT route. • ETL may be used when data must be cleaned and validated before loading, if there are strict schema and audit requirements. In this case when customer data from CRM systems needs Personal Information masking, standardization of names/addresses or if we aggregation is required before loading • ELT is used when data is coming fast and freq

In today’s data-driven world, choosing the right architecture is crucial. This article compares Data Warehouses, Data Lakes, Data Lakehouse’s, and Data Marts through real-world business use cases—exploring how data flows from raw sources to decision-making dashboards. Each serves a unique purpose, and choosing the right one depends on your team's goals, tools, and data maturity.
Data Lakes
Data lake is a large repository that stores huge amounts of raw data in its original format until you need to use it. There are no fixed limitations on data lake storage. That means that considerations — like format, file type, and specific purpose — do not apply. It is used when organizations need flexibility is required in data processing and analysis. Data lakes can store any type of data from multiple sources, whether that data is structured, semi-structured, or unstructured. As a result, data lakes are highly scalable, which makes them ideal for larger organizations that collect a vast amount of data.
Let’s better understand Data Lakes end to end with a real-world example:
A real-world example would be a tech company that leverages Data Lakes for storing large-scale logs and unstructured user interaction data for product analytics.
What might the data source for this example look like?
Data might come through various sources such as web application logs, mobile application events, social media data.
How does extraction, transformation and loading (ETL) the data from the source to the Data Lake look like?
The raw data gets continuously streamed (real time processing) into Data Lakes (usually cloud storage). A thing to note is that there is no upfront transformation as it uses schema-on-read approach
Data Lake Tools:
Amazon S3, Azure Data Lake, or Goolgle Cloud Storage
Who might be the End Users and how would they use it?
Data Scientist using data for exploratory analysis purposes and applying machine learning using Spark or Python notebooks for identifying user behavior patterns, improving product features through ML models.
Data Warehouse
Data in Data Warehouse is collected from a variety of sources, but this typically takes the form of processed data from internal and external systems in an organization. This data consists of specific insights such as product, customer, or employee information. It is best used for reporting and data analysis, storing historical data.
Let’s better understand Data Warehouse end to end with a real-world example:
One of the prime examples where Data Warehouses are used is in very large retail chains where they would like to store and analyze customer purchases and their sales data.
What might the data source for this example look like?
It could be their Point of Sales (POS) Systems, online transactions, CRM data
How does this data get extracted, transformed and loaded (ETL) from the source to the Data Warehouse?
• As a first step, data gets extracted in batches at night from operational databases (quick detour: they are also called Online Transaction Processing – OLTP systems and are used to run day-to-day business operations. These are the systems where data is first created, updated, or deleted in real time during routine transactions).
• The second step in this case would be to transform the data where cleaning, deduplication and normalization takes place.
• The final step would be loading the data into the data warehouse (schema-on-write).
Tools for Data Warehouse:
Snowflake, Amazon Redshift or Google BigQuery.
End Users of Data Warehouse?
As one of the usages, it could be used by Analysts to create PowerBI or Tableau dashboards for creating daily sales reports, profitability analysis or inventory forecast.
Data Lakehouse
Data Lakehouse is a hybrid approach that combines the best of Data Warehouse and Data Lake. It combines the management and performance capabilities of data warehouses with the scalability of data lakes. It supports semi-structured, structured, and unstructured data.
Let’s better understand Data Lakehouse end to end with a real-world example:
Taking an example of financial services that would use Data Lakehouse for building real-time fraud detection and regulatory reporting.
What might the data source for this example look like?
Real-time transactional data through core banking systems, Customer Profiles with KYC info from CRM systems, fraud alert signals through Fraud Detection APIs and through external data feeds from credit bureaus, etc
How does hybrid ETL/ELT data load from the sources to the Data Lakehouse look like?
Loading the data into Data Lakehouse maybe either take an ETL or ELT route.
• ETL may be used when data must be cleaned and validated before loading, if there are strict schema and audit requirements. In this case when customer data from CRM systems needs Personal Information masking, standardization of names/addresses or if we aggregation is required before loading
• ELT is used when data is coming fast and frequently or if it’s better to land raw data first and clean it later. In this case, storing real-time transactions streamed via Apache Kafka and landing immediately into data lakehouse or fraud alerts from external APIs storing as is.
Lakehouse tools:
Databricks Lakehouse Platform with Delta Lake, Apache Iceberg.
End Users of Data Lakehouse?
Analysts and Data Scientists who run real-time data queries which could be used for creating regulatory reports and creating real-time fraud detection models that could be integrated into BI dashboards.
Data Marts
Data Marts are specialized and focused. It is a subset of data warehouses which allow your team to access relevant datasets without the pain of dealing with an entire complex warehouse. It is a great solution for you if you are looking to enable self-service analytics for individual departments
Let’s better understand Data Marts end to end with a real-world example:
Let’s take an example of a sales team in a pharmaceutical company that needs specific analytics for their product lines.
What might the data source for this example look like?
It will come through Data Warehouse, in this case Enterprise Data Warehouse (e.g. Snowflake), sales CRM, and marketing data.
How would the loading process (ETL) look like?
Creating a subset from the main data warehouse and loading pre-aggregated or filter data relevant specifically to the sales team.
Data Mart Tools:
It could be smaller databases like SQL Server, Snowflake, or simplified Redshift instances.
End Users of Data Mart:
For this use case, the sales team accessing the specialized reports through dedicated Tableau or PowerBI dashboards.
References
1) https://medium.com/@onliashish/exploring-data-architecture-design-patterns-3a9241862f2e
2) https://www.splunk.com/en_us/blog/learn/data-warehouse-vs-data-lake.html