![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)




































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)


















![QA - Best methods for getting large amount of test data into event consuming applications generated from an API application [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)

























.jpeg?#)





































































-11.11.2024-4-49-screenshot.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)





















_jvphoto_Alamy.jpg?#)










































































































![Apple Debuts Official Trailer for 'Murderbot' [Video]](https://www.iclarified.com/images/news/96972/96972/96972-640.jpg)
![Alleged Case for Rumored iPhone 17 Pro Surfaces Online [Image]](https://www.iclarified.com/images/news/96969/96969/96969-640.jpg)

![Apple Rushes Five Planes of iPhones to US Ahead of New Tariffs [Report]](https://www.iclarified.com/images/news/96967/96967/96967-640.jpg)


















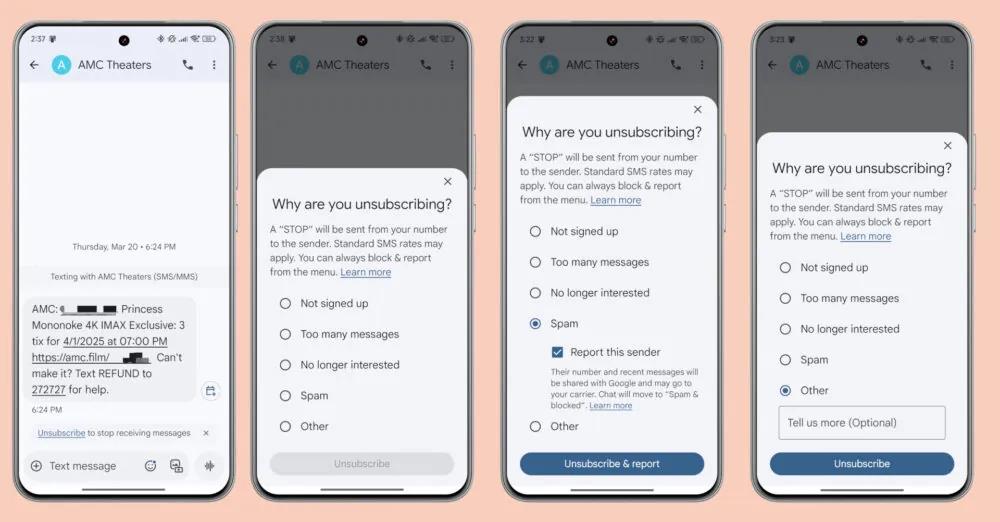





























































































Working with Parquet files
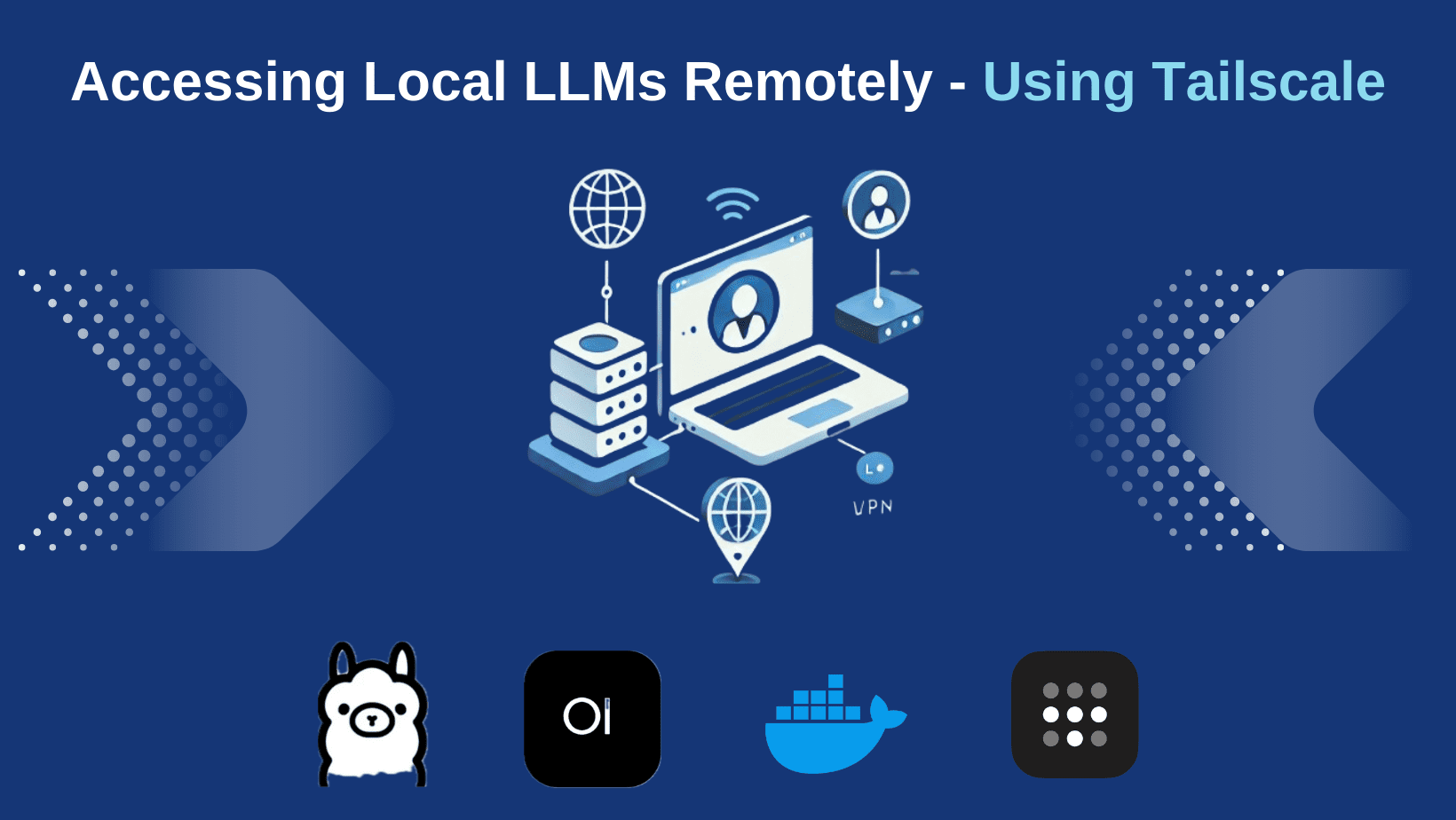
Parquet files offer significant advantages over traditional formats like CSV or JSON. This is more relevant in analytical workloads and processing. Tools like parquet-tools and DuckDB make it easy to create, manipulate, and query these files. parquet-tools https://github.com/hangxie/parquet-tools DuckDB https://duckdb.org/docs/stable/data/parquet/overview 1) parquet-tool display data to terminal in json (default) or jsonl, or csv parquet-tools cat data_file.parquet | jq . or display in jsonl only two lines/records parquet-tools cat --format jsonl --limit 2 data_file.parquet Get the meta data about the parquet file parquet-tools meta data_file.parquet **2) DuckDB DuckDB is an embedded SQL database that supports reading and writing Parquet files. Example: Generate a Parquet file: COPY (SELECT 'example' AS col1) TO 'data_file.parquet' (FORMAT 'parquet'); Read a Parquet file: SELECT * FROM read_parquet('data_file.parquet'); Lately, I have been using DuckDB for most of my analytics (dealing with Gigabytes of data) and it can handle both local and cloud-based files efficiently. What is the Parquet file format? Read about the Apache project's Overview/Motivation page https://parquet.apache.org/docs/overview/motivation/ and the project Documentation Parquet is built to support very efficient compression and encoding schemes. Multiple projects have demonstrated the performance impact of applying the right compression and encoding scheme to the data. Parquet allows compression schemes to be specified on a per-column level, and is future-proofed to allow adding more encodings as they are invented and implemented. For a good easy reading, go to this great blog article:https://blog.matthewrathbone.com/2019/12/20/parquet-or-bust.html

Parquet files offer significant advantages over traditional formats like CSV or JSON. This is more relevant in analytical workloads and processing.
Tools like parquet-tools and DuckDB make it easy to create, manipulate, and query these files.
parquet-toolshttps://github.com/hangxie/parquet-tools
1) parquet-tool
display data to terminal in json (default) or jsonl, or csv
parquet-tools cat data_file.parquet | jq .
or
display in jsonl only two lines/records
parquet-tools cat --format jsonl --limit 2 data_file.parquet
Get the meta data about the parquet file
parquet-tools meta data_file.parquet
**2) DuckDB
DuckDB is an embedded SQL database that supports reading and writing Parquet files.
Example:
Generate a Parquet file:
COPY (SELECT 'example' AS col1) TO 'data_file.parquet' (FORMAT 'parquet');
Read a Parquet file:
SELECT * FROM read_parquet('data_file.parquet');
Lately, I have been using DuckDB for most of my analytics (dealing with Gigabytes of data) and it can handle both local and cloud-based files efficiently.
What is the Parquet file format?
- Read about the Apache project's Overview/Motivation page https://parquet.apache.org/docs/overview/motivation/ and the project Documentation
Parquet is built to support very efficient compression and encoding schemes. Multiple projects have demonstrated the performance impact of applying the right compression and encoding scheme to the data. Parquet allows compression schemes to be specified on a per-column level, and is future-proofed to allow adding more encodings as they are invented and implemented.
- For a good easy reading, go to this great blog article:https://blog.matthewrathbone.com/2019/12/20/parquet-or-bust.html