










































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)
































































































































![Ditching a Microsoft Job to Enter Startup Purgatory with Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)





























































































































































































































-xl.jpg)












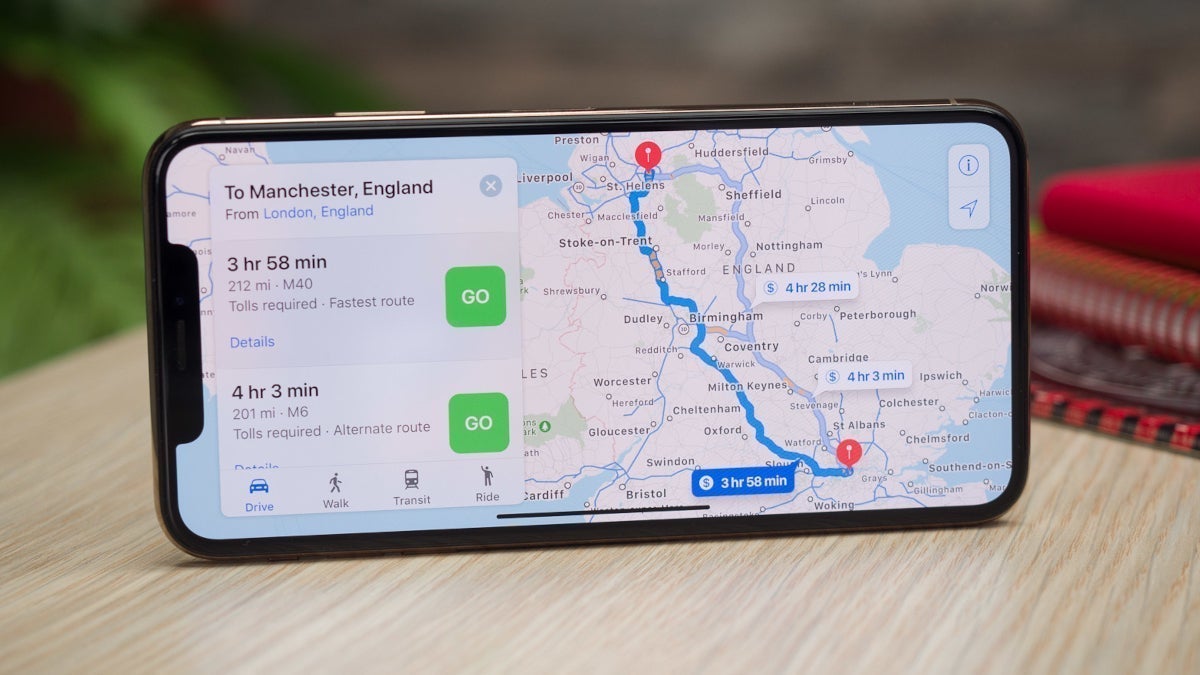
![As Galaxy Watch prepares a major change, which smartwatch design to you prefer? [Poll]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/07/Galaxy-Watch-Ultra-and-Apple-Watch-Ultra-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)












![Apple M4 iMac Drops to New All-Time Low Price of $1059 [Deal]](https://www.iclarified.com/images/news/97281/97281/97281-640.jpg)
![Beats Studio Buds + On Sale for $99.95 [Lowest Price Ever]](https://www.iclarified.com/images/news/96983/96983/96983-640.jpg)

![New iPad 11 (A16) On Sale for Just $277.78! [Lowest Price Ever]](https://www.iclarified.com/images/news/97273/97273/97273-640.jpg)





































![Apple's 11th Gen iPad Drops to New Low Price of $277.78 on Amazon [Updated]](https://images.macrumors.com/t/yQCVe42SNCzUyF04yj1XYLHG5FM=/2500x/article-new/2025/03/11th-gen-ipad-orange.jpeg)



![[Exclusive] Infinix GT DynaVue: a Prototype that could change everything!](https://www.gizchina.com/wp-content/uploads/images/2025/05/Screen-Shot-2025-05-10-at-16.07.40-PM-copy.png)


















































Python for Data Science Cheatsheet
Pandas is a panda package for data manipulation and visualization. Pandas is built ontop of Numpy and Matlplotlib(data visualization). In pandas, data analysis is done on rectangular data which is represented as dataframes, in SQL they are referred to as tables. We will be using the data Exploring a Dataframe using the table Returns first few rows of the dataframe print(alcohol_df.head()) To get the names of columns, and their data types and if they contain missing values print(alcohol_df.info()) To get the number of rows and columns of the datframe displayed as a tuple. This is an attribute, not a method. print(alcohol_df.shape) To get the summary statistics of the dataframe; print(alcohol_df.describe()) To get the values in a 2D NumPy array print(alcohol_df.values) To get the column names print(alcohol_df.columns) To get row numbers/row names print(alcohol_df.index) 1. Dataframes Change order of the rows by sorting them using a particular column. This automatically sorts be ascending order, from smallest to the largest. sorted_drinks = alcohol_df.sort_values("region") print(sorted_drinks) To sort by descending order sorted_drinks = alcohol_df.sort_values("region", ascending=False) print(sorted_drinks) Sort my multiple variables by passing a list to the method sorted_drinks = alcohol_df.sort_values(["region", "year"], ascending=[True, False]) print(sorted_drinks) Subset columns to only see the data in a particular column print(alcohol_df["region"]) To subset multiple columns to only see the data in the particular columns print(alcohol_df[["region", "year"]]) 2. Aggregating Data 3. Slicing and Indexing Data 4. Creating and Visualizing data

Pandas is a panda package for data manipulation and visualization. Pandas is built ontop of Numpy and Matlplotlib(data visualization). In pandas, data analysis is done on rectangular data which is represented as dataframes, in SQL they are referred to as tables.
We will be using the data
Exploring a Dataframe using the table
Returns first few rows of the dataframe
print(alcohol_df.head())
To get the names of columns, and their data types and if they contain missing values
print(alcohol_df.info())
To get the number of rows and columns of the datframe displayed as a tuple. This is an attribute, not a method.
print(alcohol_df.shape)
To get the summary statistics of the dataframe;
print(alcohol_df.describe())
To get the values in a 2D NumPy array
print(alcohol_df.values)
To get the column names
print(alcohol_df.columns)
To get row numbers/row names
print(alcohol_df.index)
1. Dataframes
Change order of the rows by sorting them using a particular column. This automatically sorts be ascending order, from smallest to the largest.
sorted_drinks = alcohol_df.sort_values("region")
print(sorted_drinks)
To sort by descending order
sorted_drinks = alcohol_df.sort_values("region", ascending=False)
print(sorted_drinks)
Sort my multiple variables by passing a list to the method
sorted_drinks = alcohol_df.sort_values(["region", "year"], ascending=[True, False])
print(sorted_drinks)
Subset columns to only see the data in a particular column
print(alcohol_df["region"])
To subset multiple columns to only see the data in the particular columns
print(alcohol_df[["region", "year"]])