










































































































































































![[The AI Show Episode 146]: Rise of “AI-First” Companies, AI Job Disruption, GPT-4o Update Gets Rolled Back, How Big Consulting Firms Use AI, and Meta AI App](https://www.marketingaiinstitute.com/hubfs/ep%20146%20cover.png)
































































































































![Ditching a Microsoft Job to Enter Startup Purgatory with Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)



























































































































































































































-xl.jpg)













![As Galaxy Watch prepares a major change, which smartwatch design to you prefer? [Poll]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/07/Galaxy-Watch-Ultra-and-Apple-Watch-Ultra-1.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)












![Apple M4 iMac Drops to New All-Time Low Price of $1059 [Deal]](https://www.iclarified.com/images/news/97281/97281/97281-640.jpg)
![Beats Studio Buds + On Sale for $99.95 [Lowest Price Ever]](https://www.iclarified.com/images/news/96983/96983/96983-640.jpg)

![New iPad 11 (A16) On Sale for Just $277.78! [Lowest Price Ever]](https://www.iclarified.com/images/news/97273/97273/97273-640.jpg)






































![Apple's 11th Gen iPad Drops to New Low Price of $277.78 on Amazon [Updated]](https://images.macrumors.com/t/yQCVe42SNCzUyF04yj1XYLHG5FM=/2500x/article-new/2025/03/11th-gen-ipad-orange.jpeg)



![[Exclusive] Infinix GT DynaVue: a Prototype that could change everything!](https://www.gizchina.com/wp-content/uploads/images/2025/05/Screen-Shot-2025-05-10-at-16.07.40-PM-copy.png)


















































JavaRaft: Raft-Based Distributed Key-Value Store
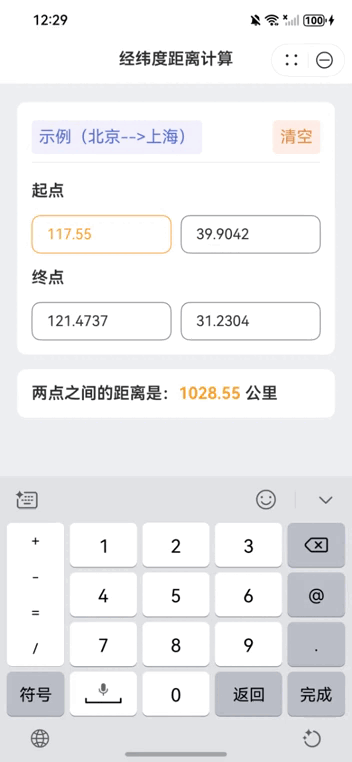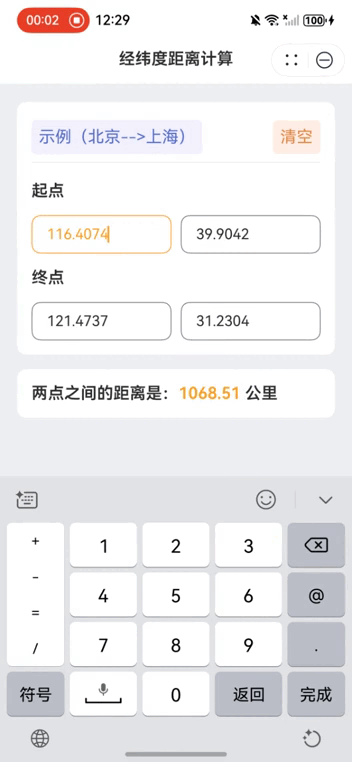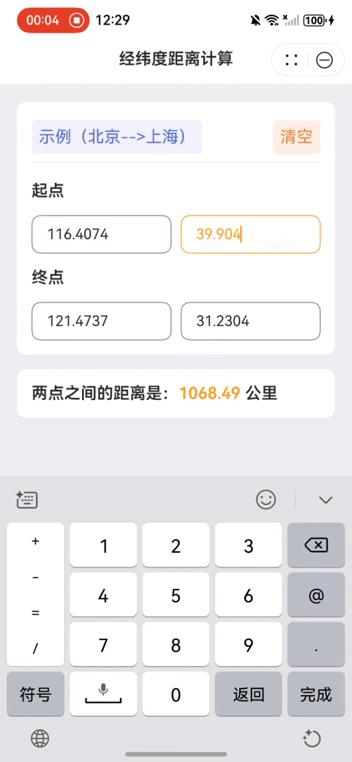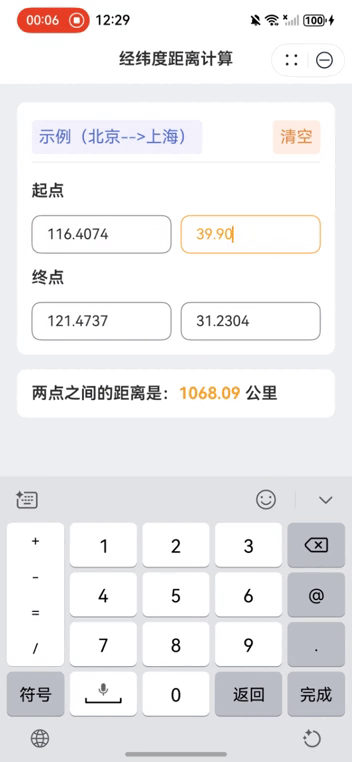
While studying for System Design interviews, I picked up some basic knowledge and got interested in distributed systems. After some studies, I still found many distributed systems algorithms a bit abstract and hand-wavy. To gain some hands-on experience, I decided to build a distributed key-value store based on Raft consensus algorithm from scratch. It took me a few weeks to fully understand the Raft paper and implement the core algorithm. In this post, I want to reiterate on my learning of some key details of my Raft-based distributed key-value store. seungwonlee003 / distributed-key-value-store A distributed key-value store using Raft consensus algorithm and custom LSM storage engine Introduction Demo video. This blog post walks through the code. This is a distributed key-value store implemented using the Raft consensus algorithm and custom LSM storage engine It offers a simple key-value lookup endpoints and it is designed to be fault-tolerant (as long as majority of nodes are alive) and linearizable. It is implemented in Java using Spring Boot with Lombok and SLF4J dependencies. Features Leader election (§5.2) Log replication (§5.3) Election restriction (§5.4.1) Committing entries from previous terms (§5.4.2) Follower and candidate crashes (§5.5) Implementing linearizable semantics (§8) Usage Try out the distributed key-value API. Configure application properties for nodes and build the JAR (skipping tests): mvn clean package -DskipTests Terminal 1 java -jar target/distributed_key_value_store-0.0.1-SNAPSHOT.jar --spring.profiles.active=node1 Terminal 2 java -jar target/distributed_key_value_store-0.0.1-SNAPSHOT.jar --spring.profiles.active=node2 Terminal 3 java -jar target/distributed_key_value_store-0.0.1-SNAPSHOT.jar --spring.profiles.active=node3 Endpoints All operations must be sent to the leader node. Redirection is not implemented, and follower reads/writes are blocked. Get operation:… View on GitHub While my implementation is far from production-ready, my goal was to build a system that works under basic conditions and demonstrates the core ideas. To keep things focused, I won’t go into line-by-line code or the fine-grained interactions between components. Instead, I’ll walk through a high-level overview of how I implemented the core Raft algorithm. Leader election (§5.2): The first module I developed is the leader election. In Raft, all nodes begin as followers, and a leader is elected when a follower’s election timer expires. To enable this, I implemented an election timer that triggers an election upon expiration. It is called when the node transition its state to a follower. // If election timeout elapses without receiving AppendEntries RPC from current leader or granting vote to candidate: // convert to candidate (§5.2) public void reset() { cancel(); long minTimeout = config.getElectionTimeoutMillisMin(); long maxTimeout = config.getElectionTimeoutMillisMax(); long timeout = minTimeout + random.nextInt((int)(maxTimeout - minTimeout)); electionFuture = scheduler.schedule(() -> { electionManager.startElection(); }, timeout, TimeUnit.MILLISECONDS); } The ElectionManager class includes two primary methods: startElection() and handleVoteRequest(). The startElection() method allocates threads from a pool based on the number of peers and sends asynchronous vote requests to each follower via their /requestVote endpoint. Then, the main thread completes the method by resetting the election timer. Here, a timeout, configured in the RestTemplate, ensures responses arrive within a duration shorter than the election timer, preventing overlapping elections on the same node. If a peer’s response indicates a higher term, the node immediately steps down to the follower state, and the election concludes. If less than majority of responses are received, the election timer resets. Otherwise, the node becomes a leader, cancels the ongoing election timer to prevent any new elections, and starts sending heartbeats to the follower nodes. HandleVoteRequest method implementation is rather straightforward following the Raft paper, so will be skipped. /** * On conversion to candidate, start election: * Increment currentTerm, vote for self, reset election timer, send RequestVote RPCs to all other servers. */ public void startElection() { lockManager.getStateWriteLock().lock(); lockManager.getLogReadLock().lock(); try { if (nodeState.getCurrentRole() == Role.LEADER) { return; } nodeState.setCurrentRole(Role.CANDIDATE); nodeState.incrementTerm(); nodeState.setVotedFor(nodeState.getNodeId()); int currentTerm = nodeState.getCurrentTerm(); int lastLogIndex = raftLog.getLastIndex(); int lastLogTerm = raftLog.getLastTerm(); List voteFutures
While studying for System Design interviews, I picked up some basic knowledge and got interested in distributed systems. After some studies, I still found many distributed systems algorithms a bit abstract and hand-wavy. To gain some hands-on experience, I decided to build a distributed key-value store based on Raft consensus algorithm from scratch.
It took me a few weeks to fully understand the Raft paper and implement the core algorithm. In this post, I want to reiterate on my learning of some key details of my Raft-based distributed key-value store.
 seungwonlee003
/
distributed-key-value-store
seungwonlee003
/
distributed-key-value-store
A distributed key-value store using Raft consensus algorithm and custom LSM storage engine
Introduction
Demo video.
This blog post walks through the code.
This is a distributed key-value store implemented using the Raft consensus algorithm and custom LSM storage engine It offers a simple key-value lookup endpoints and it is designed to be fault-tolerant (as long as majority of nodes are alive) and linearizable. It is implemented in Java using Spring Boot with Lombok and SLF4J dependencies.
Features
- Leader election (§5.2)
- Log replication (§5.3)
- Election restriction (§5.4.1)
- Committing entries from previous terms (§5.4.2)
- Follower and candidate crashes (§5.5)
- Implementing linearizable semantics (§8)
Usage
Try out the distributed key-value API.
Configure application properties for nodes and build the JAR (skipping tests):
mvn clean package -DskipTests
Terminal 1
java -jar target/distributed_key_value_store-0.0.1-SNAPSHOT.jar --spring.profiles.active=node1
Terminal 2
java -jar target/distributed_key_value_store-0.0.1-SNAPSHOT.jar --spring.profiles.active=node2
Terminal 3
java -jar target/distributed_key_value_store-0.0.1-SNAPSHOT.jar --spring.profiles.active=node3
Endpoints
All operations must be sent to the leader node. Redirection is not implemented, and follower reads/writes are blocked.
Get operation:
…While my implementation is far from production-ready, my goal was to build a system that works under basic conditions and demonstrates the core ideas.
To keep things focused, I won’t go into line-by-line code or the fine-grained interactions between components. Instead, I’ll walk through a high-level overview of how I implemented the core Raft algorithm.
Leader election (§5.2):
The first module I developed is the leader election. In Raft, all nodes begin as followers, and a leader is elected when a follower’s election timer expires.
To enable this, I implemented an election timer that triggers an election upon expiration. It is called when the node transition its state to a follower.
// If election timeout elapses without receiving AppendEntries RPC from current leader or granting vote to candidate:
// convert to candidate (§5.2)
public void reset() {
cancel();
long minTimeout = config.getElectionTimeoutMillisMin();
long maxTimeout = config.getElectionTimeoutMillisMax();
long timeout = minTimeout + random.nextInt((int)(maxTimeout - minTimeout));
electionFuture = scheduler.schedule(() -> {
electionManager.startElection();
}, timeout, TimeUnit.MILLISECONDS);
}
The ElectionManager class includes two primary methods: startElection() and handleVoteRequest(). The startElection() method allocates threads from a pool based on the number of peers and sends asynchronous vote requests to each follower via their /requestVote endpoint. Then, the main thread completes the method by resetting the election timer. Here, a timeout, configured in the RestTemplate, ensures responses arrive within a duration shorter than the election timer, preventing overlapping elections on the same node.
If a peer’s response indicates a higher term, the node immediately steps down to the follower state, and the election concludes. If less than majority of responses are received, the election timer resets. Otherwise, the node becomes a leader, cancels the ongoing election timer to prevent any new elections, and starts sending heartbeats to the follower nodes. HandleVoteRequest method implementation is rather straightforward following the Raft paper, so will be skipped.
/**
* On conversion to candidate, start election:
* Increment currentTerm, vote for self, reset election timer, send RequestVote RPCs to all other servers.
*/
public void startElection() {
lockManager.getStateWriteLock().lock();
lockManager.getLogReadLock().lock();
try {
if (nodeState.getCurrentRole() == Role.LEADER) {
return;
}
nodeState.setCurrentRole(Role.CANDIDATE);
nodeState.incrementTerm();
nodeState.setVotedFor(nodeState.getNodeId());
int currentTerm = nodeState.getCurrentTerm();
int lastLogIndex = raftLog.getLastIndex();
int lastLogTerm = raftLog.getLastTerm();
List<CompletableFuture<VoteResponseDto>> voteFutures = new ArrayList<>();
ExecutorService executor = Executors.newCachedThreadPool();
for (String peerUrl : config.getPeerUrls().values()) {
CompletableFuture<VoteResponseDto> voteFuture = CompletableFuture
.supplyAsync(() -> requestVote(
currentTerm,
nodeState.getNodeId(),
lastLogIndex,
lastLogTerm,
peerUrl
), executor)
.orTimeout(config.getElectionRpcTimeoutMillis(), TimeUnit.MILLISECONDS)
.exceptionally(throwable -> {
return new VoteResponseDto(currentTerm, false);
});
voteFutures.add(voteFuture);
}
int majority = (config.getPeerUrls().size() + 1) / 2 + 1;
AtomicInteger voteCount = new AtomicInteger(1);
// If votes received from majority of servers: become leader (§5.2).
for (CompletableFuture<VoteResponseDto> future : voteFutures) {
future.thenAccept(response -> {
lockManager.getStateWriteLock().lock();
try {
if (nodeState.getCurrentRole() != Role.CANDIDATE || nodeState.getCurrentTerm() != currentTerm) {
return;
}
if (response != null && response.isVoteGranted()) {
int newVoteCount = voteCount.incrementAndGet();
if (newVoteCount >= majority) {
stateManager.becomeLeader();
}
}
} finally {
lockManager.getStateWriteLock().unlock();
}
});
}
stateManager.resetElectionTimer();
} finally {
lockManager.getLogReadLock().unlock();
lockManager.getStateWriteLock().unlock();
}
}
Log replication (§5.3):
The second module I implemented is the log replication. Given the complexity of this logic, I splitted the responsibilities into three separate classes: one for handling client write requests, another for initiating log replication, and lastly for processing append entries.
AppendEntriesHandler.java
ClientRequestHandler.java
LogReplicator.java
RaftReplicationManager.java
To manage these interactions, I used the Facade design pattern, introducing a centralized ReplicationManager class to delegate calls to the appropriate classes.
...
public class RaftReplicationManager {
...
public boolean handleClientRequest(LogEntry entry) {
return clientRequestHandler.handle(entry);
}
public void startLogReplication() {
logReplicator.start();
}
public AppendEntriesResponseDTO handleAppendEntries(AppendEntriesDTO dto) {
return appendEntriesHandler.handle(dto);
}
public void initializeIndices() {
logReplicator.initializeIndices();
}
}
The replication process begins with the start() method in the LogReplicator class. This method relies on several key data structures defined by Raft: nextIndex[] and matchIndex[], which track replication progress for each follower, and a pendingReplication[] map to manage ongoing replication tasks.
When a node becomes the leader after winning an election, this method iterates over all followers in the pendingReplication[] map and launches asynchronous log replication for each one if not already launched, utilizing threads from a fixed thread pool.
// Upon election: send initial empty AppendEntries RPCs (heartbeat) to each server; repeat during idle periods
// to prevent election timeouts (§5.2)
public void start() {
lockManager.getStateReadLock().lock();
try {
if (nodeState.getCurrentRole() != Role.LEADER) return;
} finally {
lockManager.getStateReadLock().unlock();
}
for (String peer : config.getPeerUrls().values()) {
if (!pendingReplication.getOrDefault(peer, false)) {
pendingReplication.put(peer, true);
executor.submit(() -> replicateLoop(peer));
}
}
}
For each follower, an asynchronous thread executes the replicateLoop() method. This method runs a while loop that continuously replicates new log entries to the /appendEntries endpoint of the follower, catches followers up on missing entries, or sends empty log entries as heartbeats to maintain leadership. The loop’s back-off period aligns with the heartbeat interval.
// Sends heartbeats/log entries to peer, adjusting sleep time to match heartbeat interval
private void replicateLoop(String peer) {
int backoff = config.getHeartbeatIntervalMillis();
while (true) {
lockManager.getStateReadLock().lock();
try {
if (nodeState.getCurrentRole() != Role.LEADER) break;
} finally {
lockManager.getStateReadLock().unlock();
}
lockManager.getLogWriteLock().lock();
lockManager.getStateWriteLock().lock();
lockManager.getStateMachineWriteLock().lock();
long startTime = System.currentTimeMillis();
try {
boolean ok = replicate(peer);
if (ok) updateCommitIndex();
} finally {
lockManager.getStateMachineWriteLock().unlock();
lockManager.getStateWriteLock().unlock();
lockManager.getLogWriteLock().unlock();
}
long duration = System.currentTimeMillis() - startTime;
long sleepTime = Math.max(0, backoff - duration);
try {
Thread.sleep(sleepTime);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
pendingReplication.put(peer, false);
}
Here, the RestTemplate timeout is configured to prevent the loop from stalling indefinitely, which could otherwise trigger a unneccessary election on a follower.
When the replication loop succeeds—assuming no follower responds with a higher term—the leader updates the corresponding nextIndex[] and matchIndex[] values and invokes updateCommitIndex() method.
// If last log index >= nextIndex for a follower: send AppendEntries RPC with log entries starting at nextIndex.
private boolean replicate(String peer) {
int ni = nextIndex.get(peer);
int prevIdx = ni - 1;
int prevTerm = (prevIdx >= 0) ? raftLog.getTermAt(prevIdx) : 0;
List<LogEntry> entries = raftLog.getEntriesFrom(ni);
AppendEntriesRequestDto dto = new AppendEntriesRequestDto(
nodeState.getCurrentTerm(), nodeState.getNodeId(),
prevIdx, prevTerm, entries, raftLog.getCommitIndex()
);
String peerId = config.getPeerUrls().entrySet().stream()
.filter(entry -> entry.getValue().equals(peer))
.map(Map.Entry::getKey)
.map(String::valueOf)
.findFirst()
.orElse("unknown");
try {
String url = peer + "/raft/appendEntries";
ResponseEntity<AppendEntriesResponseDto> res = restTemplate.postForEntity(url, dto, AppendEntriesResponseDto.class);
AppendEntriesResponseDto body = res.getBody() != null ? res.getBody() : new AppendEntriesResponseDto(-1, false);
if (body.getTerm() > nodeState.getCurrentTerm()) {
nodeStateManager.becomeFollower(body.getTerm());
return false;
}
if (body.isSuccess()) {
nextIndex.put(peer, ni + entries.size());
matchIndex.put(peer, ni + entries.size() - 1);
return true;
} else {
int newNextIndex = Math.max(0, ni - 1);
nextIndex.put(peer, newNextIndex);
return false;
}
} catch (ResourceAccessException e) {
return false;
} catch (Exception e) {
return false;
}
}
This, in turn, triggers applyEntries() method, which applies log entries up to the commit index to the data store. Additionally, when advancing the commit index, it ensures that only entries from the leader’s current term are committed. This upholds Raft’s safety guarantee, preventing the application of stale entries from prior terms. This is shown below:
private void updateCommitIndex() {
int majority = (config.getPeerUrlList().size() + 1) / 2 + 1;
int term = nodeState.getCurrentTerm();
for (int i = log.getLastIndex(); i > log.getCommitIndex(); i--) {
int count = 1;
for (int idx : matchIndex.values()) {
if (idx >= i) count++;
}
if (count >= majority && log.getTermAt(i) == term) {
log.setCommitIndex(i);
applyEntries();
break;
}
}
}
From the follower’s perspective, the handle() method in the AppendEntriesHandler class processes the AppendEntriesDTO received from the leader.
It first verifies the sender’s leadership by checking the term. Next, it compares its log with the leader’s nextIndex[] for that follower. If the follower’s log is not up-to-date due to a mismatch in prior entries, it rejects the request, prompting the leader to decrement the follower’s nextIndex[] by one and retry.
If the log matches, the follower accepts the entries according to the log matching property (§5.2), updates its commit index, and applies the entries to its state machine up to the new commit index.
public AppendEntriesResponseDto handle(AppendEntriesRequestDto dto) {
lockManager.getLogWriteLock().lock();
lockManager.getStateWriteLock().lock();
lockManager.getStateMachineWriteLock().lock();
try {
int term = nodeState.getCurrentTerm();
int leaderTerm = dto.getTerm();
// Reply false if term < currentTerm (§5.1)
if (leaderTerm < term) return new AppendEntriesResponseDto(term, false);
// If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1)
if (leaderTerm > term) {
stateManager.becomeFollower(leaderTerm);
term = leaderTerm;
}
nodeState.setCurrentLeader(dto.getLeaderId());
// Reply false if log doesn't contain an entry at prevLogIndex whose term matches prevLogTerm (§5.3)
if (dto.getPrevLogIndex() > 0 &&
(!raftLog.containsEntryAt(dto.getPrevLogIndex()) ||
raftLog.getTermAt(dto.getPrevLogIndex()) != dto.getPrevLogTerm())) {
stateManager.resetElectionTimer();
return new AppendEntriesResponseDto(term, false);
}
// If an existing entry conflicts with a new one (same index but different terms), delete the existing
// entry and all that follow it (§5.3). Append any new entries not already in the log.
int index = dto.getPrevLogIndex() + 1;
List<LogEntry> entries = dto.getEntries();
if (!entries.isEmpty()) {
for (int i = 0; i < entries.size(); i++) {
int logIndex = index + i;
if (raftLog.containsEntryAt(logIndex) && raftLog.getTermAt(logIndex) != entries.get(i).getTerm()) {
raftLog.deleteFrom(logIndex);
raftLog.appendAll(entries.subList(i, entries.size()));
break;
}
}
if (!raftLog.containsEntryAt(index)) {
raftLog.appendAll(entries);
}
}
// If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of the last new entry)
if (dto.getLeaderCommit() > raftLog.getCommitIndex()) {
int lastNew = dto.getPrevLogIndex() + entries.size();
raftLog.setCommitIndex(Math.min(dto.getLeaderCommit(), lastNew));
applyEntries();
}
stateManager.resetElectionTimer();
return new AppendEntriesResponseDto(term, true);
} finally {
lockManager.getStateMachineWriteLock().unlock();
lockManager.getStateWriteLock().unlock();
lockManager.getLogWriteLock().unlock();
}
}
Finally, the ClientRequestHandler manages client writes to the database. Its handle() method appends the entry to the leader’s log for replication and monitors the entry’s index. It returns a success response only when the last applied index surpasses the entry’s index, confirming that the write has been applied to the state machine.
This mechanism supports linearizability, ensuring that subsequent client reads following a successful write reflect the updated state machine.
// If command received from the client: append entry to local log, respond after entry applied
// to state machine (§5.3)
public boolean handle(LogEntry clientEntry) {
lockManager.getStateReadLock().lock();
lockManager.getLogWriteLock().lock();
int entryIndex;
try {
if (!raftNodeState.isLeader()) return false;
raftLog.append(clientEntry);
entryIndex = raftLog.getLastIndex();
} finally {
lockManager.getLogWriteLock().unlock();
lockManager.getStateReadLock().unlock();
}
long start = System.currentTimeMillis();
long timeoutMillis = raftConfig.getClientRequestTimeoutMillis();
while (true) {
lockManager.getLogReadLock().lock();
lockManager.getStateReadLock().lock();
try {
if (raftNodeState.getCurrentRole() != Role.LEADER) {
return false;
}
if (raftNodeState.getLastApplied() >= entryIndex) {
return true;
}
} finally {
lockManager.getStateReadLock().unlock();
lockManager.getLogReadLock().unlock();
}
if (System.currentTimeMillis() - start > timeoutMillis) {
return false;
}
try {
Thread.sleep(50);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return false;
}
}
}
Here, a slight latency is introduced because client writes are aligned with the heartbeat cycle. If the heartbeat interval is 1 second, the leader may wait up to 1 second before replicating the write. While the Raft protocol allows independent AppendEntries RPCs for writes (separate from heartbeats), I chose to synchronize client writes with the heartbeat cycle to simplify concurrency handling and to take advantage of batched replication.
Before concluding, I want to address concurrency concerns. In Raft, concurrent threads handling RequestVote, AppendEntries, and election timeouts can introduce race conditions by simultaneously modifying shared node state (such as currentTerm, votedFor, and the log). To ensure serializability and prevent such race conditions, I implemented a centralized read-write lock that guards access to the node’s state, log, and state machine.
This concludes the explanation of the core Raft logics. Now, I want to talk about the fundamental concern that I addressed per the Raft paper known as "Implementing linearizable semantics" (§8).
Ensuring Lineraizable Semantics
In Raft, writes are committed once they reach a majority quorum, and the leader is guaranteed to hold all committed log entries. However, this does not inherently ensure that reads routed to the leader always reflect the most up-to-date state, which is necessary for linearizability.
Consider a scenario where a client is connected to a leader that loses its leadership due to a network partition, isolating it from the majority of the cluster. If the client reconnects to this former leader before the partition heals, the node may still consider itself the leader and serve stale data from its state machine data that could have been superseded by a new leader. This violates linearizability, as the read does not reflect the latest committed writes.
Raft paper proposes different solutions to this and I implemented a mechanism where the client get operation will always send no-op entry to the followers to confirm leadership. If majority of nodes accepts the entry through /appendEntries endpoint logic, it guarantees that the leader is not stale, thereby confirming reads as linearizable. While this introduces extra network round trip, it provides just-enough solution given my current implementation.
More efficient alternatives, such as ReadIndex or lease-based reads, exist, but I chose this straightforward approach. Sorry for the messy code below: this was because I didn’t plan to extend this class any further.
@GetMapping("/get")
public ResponseEntity<String> get(@RequestParam String key) {
final String NO_OP_ENTRY = "NO_OP_ENTRY";
try {
handleRead(new WriteRequestDto(NO_OP_ENTRY, Long.MAX_VALUE, NO_OP_ENTRY, NO_OP_ENTRY));
} catch (Exception e) {
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR)
.body("Failed to process read request: " + e.getMessage());
}
lockManager.getStateMachineReadLock().lock();
try {
String value = kvStore.get(key);
if (value == null) {
return ResponseEntity.status(HttpStatus.NOT_FOUND)
.body("Key not found: " + key);
}
return ResponseEntity.ok(value);
} catch (Exception e) {
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR)
.body("Error retrieving key: " + e.getMessage());
} finally {
lockManager.getStateMachineReadLock().unlock();
}
}
private void handleRead(WriteRequestDto request) {
LogEntry entry = new LogEntry(
nodeState.getCurrentTerm(),
request.getKey(),
request.getValue(),
LogEntry.Operation.PUT,
request.getClientId(),
request.getSequenceNumber()
);
boolean committed = replicationManager.handleClientRequest(entry);
if (!committed) throw new RuntimeException("Can't process the read at this moment");
}
Ensuring Lineraizable Semantics 2
Raft paper discusses a scenario where “if the leader crashes after committing the log entry but before responding to the client, the client will retry the command with a new leader, causing it to be executed a second time”. Client-side deduplication solves this by attaching a unique identifier (e.g., a sequence number) to each request. The server tracks these IDs, rejecting duplicates. This preserves both correctness and linearizability, addressing one of the key challenges.
In the implementation, I modified the apply() method in the StateMachine class. Before applying a write, it queries the database (in-memory) to compare the log entry’s sequence number with the last recorded sequence number for that client ID. The write is applied only if the new sequence number is greater, confirming it as a fresh operation rather than a duplicate.
@Override
public void apply(LogEntry entry) {
if (entry == null) {
throw new IllegalArgumentException("Log entry cannot be null");
}
// deduplication check
String clientId = entry.getClientId();
long sequenceNumber = entry.getSequenceNumber();
Long lastSequenceNumber = kvStore.getLastSequenceNumber(clientId);
if (lastSequenceNumber != null && sequenceNumber <= lastSequenceNumber) {
return;
}
...
}
Persistence
The final requirement to establish a fully functional database is persistence. The state machine must guarantee durability, ensuring no data is lost during a crash. While I initially tested Raft’s core components using an in-memory implementation, I later incorporated disk-based persistence.
The DB class embodies this approach. I used my custom-built embedded database as a state machine. For the Raft log, I implemented a file-backed, append-only log to ensure durability on disk.
With these components in place, I’ve addressed the essential elements of my Raft-based key-value store. I believe my implementation isn’t perfect and there should be far more tedious conditions and corner cases that I simply am not aware of. Numerous ways for subtle bugs.
Nonetheless, this was quite an exciting journey as it taught me areas to consider in designing a distributed systems.



