









































































































































































![[The AI Show Episode 153]: OpenAI Releases o3-Pro, Disney Sues Midjourney, Altman: “Gentle Singularity” Is Here, AI and Jobs & News Sites Getting Crushed by AI Search](https://www.marketingaiinstitute.com/hubfs/ep%20153%20cover.png)

































































































































































































![GrandChase tier list of the best characters available [June 2025]](https://media.pocketgamer.com/artwork/na-33057-1637756796/grandchase-ios-android-3rd-anniversary.jpg?#)
































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

















































![[Fixed] How to Recover Unsaved Word Document on Windows 10/11](https://www.pcworld.com/wp-content/uploads/2025/06/How-to-recover-unsaved-word-document-main.png?#)




























































![Google Mocks Apple's 'New' iOS 26 Features in Pixel Ad [Video]](https://www.iclarified.com/images/news/97638/97638/97638-640.jpg)



































































How Latent Vector Fields Reveal the Inner Workings of Neural Autoencoders
Autoencoders and the Latent Space Neural networks are designed to learn compressed representations of high-dimensional data, and autoencoders (AEs) are a widely-used example of such models. These systems employ an encoder-decoder structure to project data into a low-dimensional latent space and then reconstruct it back to its original form. In this latent space, the patterns […] The post How Latent Vector Fields Reveal the Inner Workings of Neural Autoencoders appeared first on MarkTechPost.

Autoencoders and the Latent Space
Neural networks are designed to learn compressed representations of high-dimensional data, and autoencoders (AEs) are a widely-used example of such models. These systems employ an encoder-decoder structure to project data into a low-dimensional latent space and then reconstruct it back to its original form. In this latent space, the patterns and features of the input data become more interpretable, allowing for the performance of various downstream tasks. Autoencoders have been extensively utilized in domains such as image classification, generative modeling, and anomaly detection thanks to their ability to represent complex distributions through more manageable, structured representations.
Memorization vs. Generalization in Neural Models
A persistent issue with neural models, particularly autoencoders, is determining how they strike a balance between memorizing training data and generalizing to unseen examples. This balance is critical: if a model overfits, it may fail to perform on new data; if it generalizes too much, it may lose useful detail. Researchers are especially interested in whether these models encode knowledge in a way that can be revealed and measured, even in the absence of direct input data. Understanding this balance can help optimize model design and training strategies, providing insight into what neural models retain from the data they process.

Existing Probing Methods and Their Limitations
Current techniques for probing this behavior often analyze performance metrics, such as reconstruction error, but these only scratch the surface. Other approaches utilize modifications to the model or input to gain insight into internal mechanisms. However, they usually don’t reveal how model structure and training dynamics influence learning outcomes. The need for a deeper representation has driven research into more intrinsic and interpretable methods of studying model behavior that go beyond conventional metrics or architectural tweaks.
The Latent Vector Field Perspective: Dynamical Systems in Latent Space
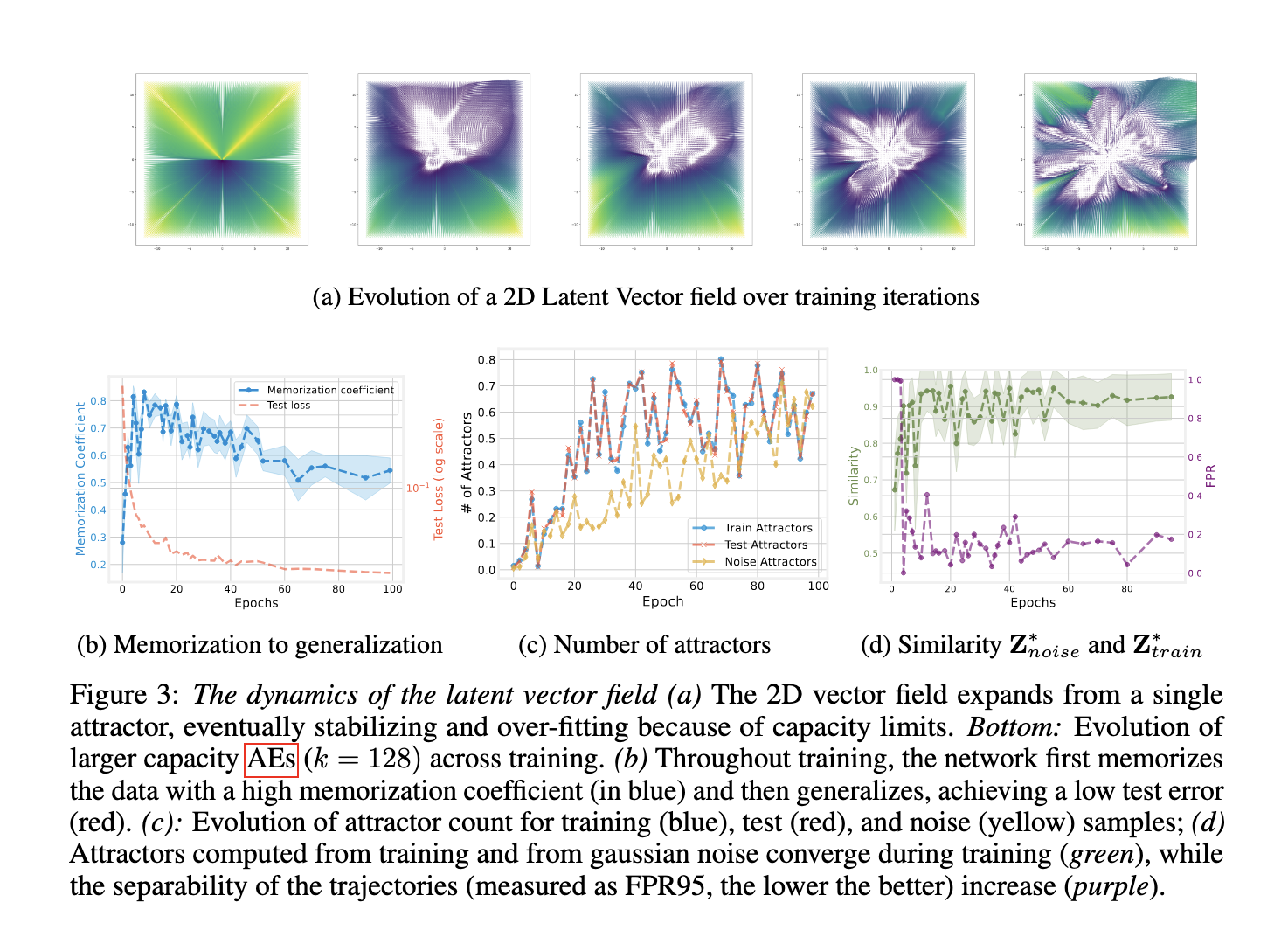
Researchers from IST Austria and Sapienza University introduced a new way to interpret autoencoders as dynamical systems operating in latent space. By repeatedly applying the encoding-decoding function on a latent point, they construct a latent vector field that uncovers attractors—stable points in latent space where data representations settle. This field inherently exists in any autoencoder and doesn’t require changes to the model or additional training. Their method helps visualize how data moves through the model and how these movements relate to generalization and memorization. They tested this across datasets and even foundation models, extending their insights beyond synthetic benchmarks.
Iterative Mapping and the Role of Contraction
The method involves treating the repeated application of the encoder-decoder mapping as a discrete differential equation. In this formulation, any point in latent space is mapped iteratively, forming a trajectory defined by the residual vector between each iteration and its input. If the mapping is contractive—meaning each application shrinks the space—the system stabilizes to a fixed point or attractor. The researchers demonstrated that common design choices, such as weight decay, small bottleneck dimensions, and augmentation-based training, naturally promote this contraction. The latent vector field thus acts as an implicit summary of the training dynamics, revealing how and where models learn to encode data.
Empirical Results: Attractors Encode Model Behavior
Performance tests demonstrated that these attractors encode key characteristics of the model’s behavior. When training convolutional AEs on MNIST, CIFAR10, and FashionMNIST, it was found that lower bottleneck dimensions (2 to 16) led to high memorization coefficients above 0.8, whereas higher dimensions supported generalization by lowering test errors. The number of attractors increased with the number of training epochs, starting from one and stabilizing as training progressed. When probing a vision foundation model pretrained on Laion2B, the researchers reconstructed data from six diverse datasets using attractors derived purely from Gaussian noise. At 5% sparsity, reconstructions were significantly better than those from a random orthogonal basis. The mean squared error was consistently lower, demonstrating that attractors form a compact and effective dictionary of representations.
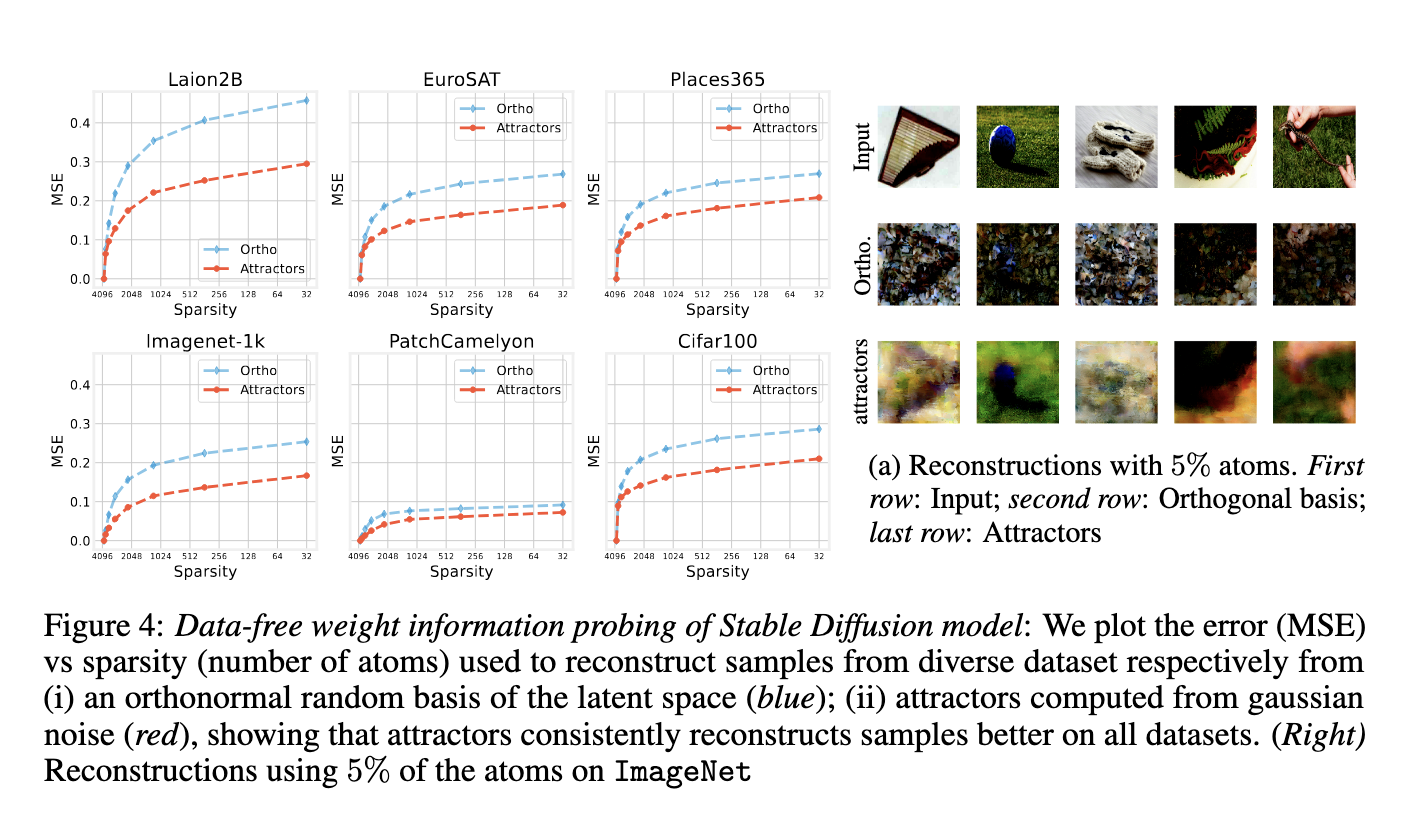
Significance: Advancing Model Interpretability
This work highlights a novel and powerful method for inspecting how neural models store and use information. The researchers from IST Austria and Sapienza revealed that attractors within latent vector fields provide a clear window into a model’s ability to generalize or memorize. Their findings show that even without input data, latent dynamics can expose the structure and limitations of complex models. This tool could significantly aid the development of more interpretable, robust AI systems by revealing what these models learn and how they behave during and after training.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post How Latent Vector Fields Reveal the Inner Workings of Neural Autoencoders appeared first on MarkTechPost.


