
















































































































































![Top Features of Vision-Based Workplace Safety Tools [2025]](https://static.wixstatic.com/media/379e66_7e75a4bcefe14e4fbc100abdff83bed3~mv2.jpg/v1/fit/w_1000,h_884,al_c,q_80/file.png?#)































![How to Use AI as a Productivity Tool with Mike Kaput [MAICON 2025 Speaker Series]](https://www.marketingaiinstitute.com/hubfs/v2MAICON-Speaker_Series.png)
![[The AI Show Episode 152]: ChatGPT Connectors, AI-Human Relationships, New AI Job Data, OpenAI Court-Ordered to Keep ChatGPT Logs & WPP’s Large Marketing Model](https://www.marketingaiinstitute.com/hubfs/ep%20152%20cover.png)
































































































































































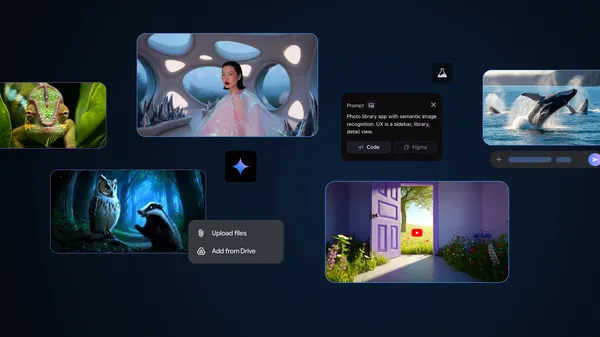























































































































































































![PSA: Widespread internet outage affects Spotify, Google, Discord, Cloudflare, more [U: Fixed]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2024/07/iCloud-Private-Relay-outage-resolved.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)




















![Apple Shares Teaser Trailer for 'The Lost Bus' Starring Matthew McConaughey [Video]](https://www.iclarified.com/images/news/97582/97582/97582-640.jpg)
























































CURE: A Reinforcement Learning Framework for Co-Evolving Code and Unit Test Generation in LLMs
Introduction Large Language Models (LLMs) have shown substantial improvements in reasoning and precision through reinforcement learning (RL) and test-time scaling techniques. Despite outperforming traditional unit test generation methods, most existing approaches such as O1-Coder and UTGEN require supervision from ground-truth code. This supervision increases data collection costs and limits the scale of usable training data. […] The post CURE: A Reinforcement Learning Framework for Co-Evolving Code and Unit Test Generation in LLMs appeared first on MarkTechPost.

Introduction
Large Language Models (LLMs) have shown substantial improvements in reasoning and precision through reinforcement learning (RL) and test-time scaling techniques. Despite outperforming traditional unit test generation methods, most existing approaches such as O1-Coder and UTGEN require supervision from ground-truth code. This supervision increases data collection costs and limits the scale of usable training data.
Limitations of Existing Approaches
Conventional unit test generation relies on:
- Software analysis methods, which are rule-based and rigid.
- Neural machine translation techniques, which often lack semantic alignment.
While recent prompt-based and agentic methods improve performance, they still depend heavily on labeled code for fine-tuning. This reliance restricts adaptability and scalability, particularly in real-world, large-scale deployment scenarios.
CURE: A Self-Supervised Co-Evolutionary Approach
Researchers from the University of Chicago, Princeton University, Peking University, and ByteDance Seed introduce CURE, a self-supervised reinforcement learning framework that jointly trains a code generator and a unit test generator without any ground-truth code.
CURE operates using a self-play mechanism in which:
- The LLM generates both correct and incorrect code.
- The unit test generator learns to distinguish failure modes and refines itself accordingly.
This bidirectional co-evolution enhances both code generation and verification without external supervision.

Architecture and Methodology
Base Models and Sampling Strategy
CURE is built on Qwen2.5-7B and 14B Instruct models, with Qwen3-4B used for long-chain-of-thought (CoT) variants. Each training step samples:
- 16 candidate code completions.
- 16 task-derived unit tests.
Sampling is performed using vLLM with temperature 1.0 and top-p 1.0. For long-CoT models, a response-length-aware transformation penalizes lengthy outputs, improving inference-time efficiency.
Reward Function and Optimization
CURE introduces a mathematically grounded reward formulation to:
- Maximize reward precision, defined as the likelihood that correct code scores higher than incorrect code across generated unit tests.
- Apply response-based reward adjustments for long responses to reduce latency.
Optimization proceeds via policy gradient methods, jointly updating the coder and unit tester to improve their mutual performance.

Benchmark Datasets and Evaluation Metrics
CURE is evaluated on five standard coding datasets:
- LiveBench
- MBPP
- LiveCodeBench
- CodeContests
- CodeForces
Performance is measured across:
- Unit test accuracy
- One-shot code generation accuracy
- Best-of-N (BoN) accuracy using 16 code and test samples.

Performance and Efficiency Gains
The ReasonFlux-Coder models derived via CURE achieve:
- +37.8% in unit test accuracy.
- +5.3% in one-shot code generation accuracy.
- +9.0% in BoN accuracy.
Notably, ReasonFlux-Coder-4B achieves 64.8% reduction in average unit test response length—substantially improving inference speed. Across all benchmarks, these models outperform traditional coding-supervised fine-tuned models (e.g., Qwen2.5-Coder-Instruct).
Application to Commercial LLMs
When ReasonFlux-Coder-4B is paired with GPT-series models:
- GPT-4o-mini gains +5.5% BoN accuracy.
- GPT-4.1-mini improves by +1.8%.
- API costs are reduced while performance is enhanced, indicating a cost-effective solution for production-level inference pipelines.
Use as Reward Model for Label-Free Fine-Tuning
CURE-trained unit test generators can be repurposed as reward models in RL training. Using ReasonFlux-Coder-4B’s generated unit tests yields comparable improvements to human-labeled test supervision—enabling fully label-free reinforcement learning pipelines.
Broader Applicability and Future Directions
Beyond BoN, ReasonFlux-Coder models integrate seamlessly with agentic coding frameworks like:
- MPSC (Multi-Perspective Self-Consistency)
- AlphaCodium
- S*
These systems benefit from CURE’s ability to refine both code and tests iteratively. CURE also boosts agentic unit test generation accuracy by over 25.1%, reinforcing its versatility.
Conclusion
CURE represents a significant advancement in self-supervised learning for code generation and validation, enabling large language models to jointly evolve their coding and unit test generation capabilities without reliance on ground-truth code. By leveraging a co-evolutionary reinforcement learning framework, CURE not only enhances core performance metrics such as one-shot accuracy and Best-of-N selection but also improves inference efficiency through response-length-aware optimization. Its compatibility with existing agentic coding pipelines and ability to function as a label-free reward model make it a scalable and cost-effective solution for both training and deployment scenarios.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 99k+ ML SubReddit and Subscribe to our Newsletter.
The post CURE: A Reinforcement Learning Framework for Co-Evolving Code and Unit Test Generation in LLMs appeared first on MarkTechPost.



