









































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)





















































































































































![Python child class method with additional arguments [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)


























































































































































































































![Apple Watch to Get visionOS Inspired Refresh, Apple Intelligence Support [Rumor]](https://www.iclarified.com/images/news/96976/96976/96976-640.jpg)
![New Apple Watch Ad Features Real Emergency SOS Rescue [Video]](https://www.iclarified.com/images/news/96973/96973/96973-640.jpg)
![Apple Debuts Official Trailer for 'Murderbot' [Video]](https://www.iclarified.com/images/news/96972/96972/96972-640.jpg)
![Alleged Case for Rumored iPhone 17 Pro Surfaces Online [Image]](https://www.iclarified.com/images/news/96969/96969/96969-640.jpg)

















































































































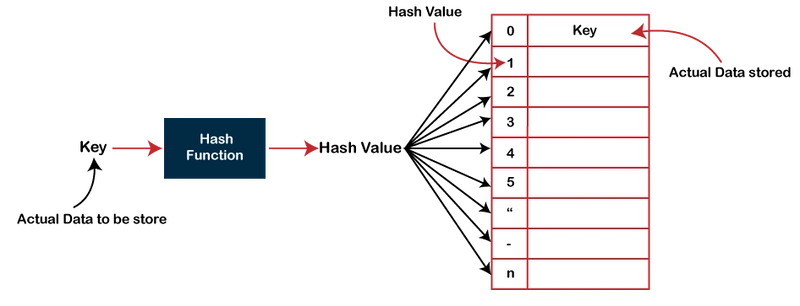
How does S3 provide near-infinite storage and performance?
Did you know that S3 stores more than 350 trillion objects and holds around 10–100 exabytes of data (1 exabyte = 1 million terabytes)? These numbers alone are mind-boggling and make your jaw drop. Ever wondered how AWS manages to provide near-unlimited data storage and infinite scalability? Let's start with some basics... You must have heard many times that S3 is an object storage system, not a file system. What does that mean? And how is it important in terms of performance? Structure The traditional file system uses tree-like structures, while S3 uses a key-value system. If you have studied algorithms, you know that if you have the exact hash/key, the lookup is far faster than the tree. AWS uses this exact scenario. AWS keeps the metadata and files separate. The metadata is stored in a large database, and the file contents are just chunks of data on massive arrays. The metadata database contains pointers to those files as well as hashes of the file contents. So whenever you want to fetch a file, metadata is read from a database, which points to the location of a file in this huge array to return the file you asked for. This improves the performance tremendously over the traditional file system. AWS uses something called "Dynamo" (yes, similar to DynamoDB), which is internal tech designed for a scalable, highly available key-value storage system. https://www.allthingsdistributed.com/2007/10/amazons_dynamo.html Storage Now that we have understood the performance factor, how does S3 function in terms of storage? For every storage system, from your laptop to data centers, hard drives are at its core. Officially, as of 2023/07, AWS was using 26TB HDDs, and since 36TB HDDs are in the market, AWS is most likely using them. The basics of expanding storage are to just add up the HDDs, as many as you can, and we are talking in millions of drives!! As these new drives are added to the system, S3 has automation flows to partition the data, subsystems to handle GET/PUT requests, and data movement from drives to avoid hotspots (high I/O on a single disk). When you are scaling at an unimaginable rate, the problem isn’t about adding the hard drives—it is handling data placement and performance. In the end, you are storing the data on physical drives, which have limits to I/O. Even if you have 10 HDDs to partition the 100TB of data, but a few GBs of high-demand data is stored on a single drive, IOPS can break your application. It's fascinating how AWS manages to scale and maintain its performance at this rate. Architehture AWS S3 receives over 1 million requests per second! To handle this scale, S3 is built on a microservices architecture and uses a fleet of instances distributed across multiple availability zones and regions. When an HTTP request is made to S3 (e.g., a GET request), it is first received by a web server layer. These web servers act as the entry point, authenticating and parsing the request. The request is then routed to the appropriate namespace and region based on metadata and internal routing logic. Once the correct datacenter and availability zone are identified, the request is forwarded to the storage fleet, which handles the object’s metadata and locates the actual data on physical hard drives. From there, the data is retrieved and streamed back through the layers to the client. I am not diving any deeper today, but you can read from the referenced links: https://www.allthingsdistributed.com/2023/07/building-and-operating-a-pretty-big-storage-system.html More about subsystems - https://aws.amazon.com/message/41926/ Note – True scaling architecture under the S3 hood is unknown, but through whitepapers, we can get a glimpse into the black box. Later..
Did you know that S3 stores more than 350 trillion objects and holds around 10–100 exabytes of data (1 exabyte = 1 million terabytes)?
These numbers alone are mind-boggling and make your jaw drop. Ever wondered how AWS manages to provide near-unlimited data storage and infinite scalability?
Let's start with some basics...
You must have heard many times that S3 is an object storage system, not a file system. What does that mean? And how is it important in terms of performance?
Structure
The traditional file system uses tree-like structures, while S3 uses a key-value system. If you have studied algorithms, you know that if you have the exact hash/key, the lookup is far faster than the tree. AWS uses this exact scenario.
AWS keeps the metadata and files separate. The metadata is stored in a large database, and the file contents are just chunks of data on massive arrays.
The metadata database contains pointers to those files as well as hashes of the file contents.
So whenever you want to fetch a file, metadata is read from a database, which points to the location of a file in this huge array to return the file you asked for.
This improves the performance tremendously over the traditional file system.
AWS uses something called "Dynamo" (yes, similar to DynamoDB), which is internal tech designed for a scalable, highly available key-value storage system.
https://www.allthingsdistributed.com/2007/10/amazons_dynamo.html
Storage
Now that we have understood the performance factor, how does S3 function in terms of storage?
For every storage system, from your laptop to data centers, hard drives are at its core. Officially, as of 2023/07, AWS was using 26TB HDDs, and since 36TB HDDs are in the market, AWS is most likely using them.
The basics of expanding storage are to just add up the HDDs, as many as you can, and we are talking in millions of drives!!
As these new drives are added to the system, S3 has automation flows to partition the data, subsystems to handle GET/PUT requests, and data movement from drives to avoid hotspots (high I/O on a single disk).
When you are scaling at an unimaginable rate, the problem isn’t about adding the hard drives—it is handling data placement and performance.
In the end, you are storing the data on physical drives, which have limits to I/O. Even if you have 10 HDDs to partition the 100TB of data, but a few GBs of high-demand data is stored on a single drive, IOPS can break your application.
It's fascinating how AWS manages to scale and maintain its performance at this rate.
Architehture
AWS S3 receives over 1 million requests per second! To handle this scale, S3 is built on a microservices architecture and uses a fleet of instances distributed across multiple availability zones and regions.
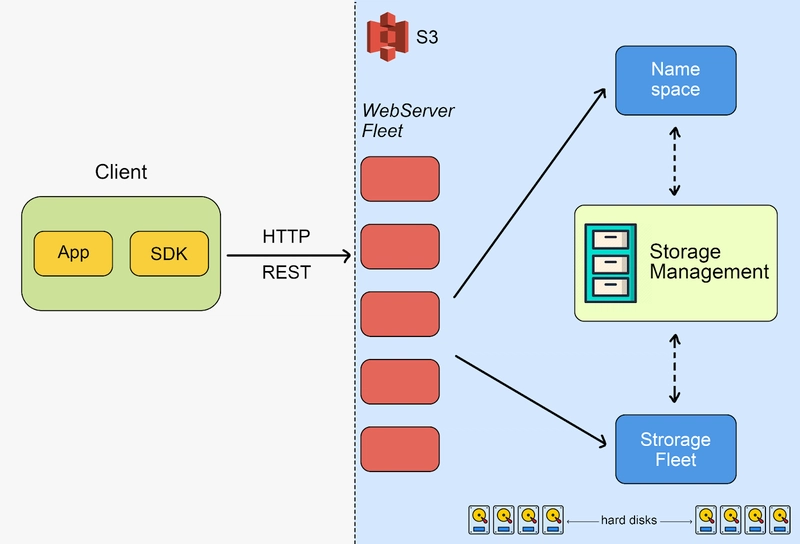
When an HTTP request is made to S3 (e.g., a GET request), it is first received by a web server layer. These web servers act as the entry point, authenticating and parsing the request. The request is then routed to the appropriate namespace and region based on metadata and internal routing logic.
Once the correct datacenter and availability zone are identified, the request is forwarded to the storage fleet, which handles the object’s metadata and locates the actual data on physical hard drives. From there, the data is retrieved and streamed back through the layers to the client.
I am not diving any deeper today, but you can read from the referenced links:
https://www.allthingsdistributed.com/2023/07/building-and-operating-a-pretty-big-storage-system.html
More about subsystems - https://aws.amazon.com/message/41926/
Note – True scaling architecture under the S3 hood is unknown, but through whitepapers, we can get a glimpse into the black box.
Later..



